RNN & LSTM & GRU 的原理与区别
RNN
循环神经网络,是非线性动态系统,将序列映射到序列,主要参数有五个:[Whv,Whh,Woh,bh,bo,h0][Whv,Whh,Woh,bh,bo,h0],典型的结构图如下:

- 和普通神经网络一样,RNN有输入层输出层和隐含层,不一样的是RNN在不同的时间t会有不同的状态,其中t-1时刻隐含层的输出会作用到t时刻的隐含层.
- 参数意义是: WhvWhv:输入层到隐含层的权重参数,WhhWhh:隐含层到隐含层的权重参数,WohWoh:隐含层到输出层的权重参数,bhbh:隐含层的偏移量,bobo输出层的偏移量,h0h0:起始状态的隐含层的输出,一般初始为0.
- 不同时间的状态共享相同的权重w和偏移量b
RNN的计算方式
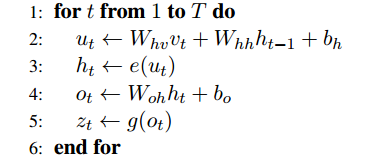
给定一个损失函数 L(z,y)=∑Tt=1L(zt,yt)L(z,y)=∑t=1TL(zt,yt)
RNN因为加入了时间序列,因此训练过程也是和之前的网络不一样,RNN的训练使用的是BPTT(Back Prropagation Through TIme),该方法是由Werbo等人在1990年提出来的。
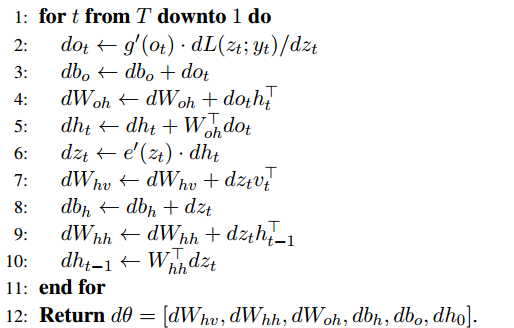
上面的算法也就是求解梯度的过程,使用的也是经典的BP算法,并没有什么新鲜的。但是值得一提的是,在 t-1 时刻对 ht−1ht−1的求导值,也需加上t时刻的求导中对ht−1ht−1 的求导值,因此BPTT也是一个链式的求导过程。
但是因为上面算法中的第10行,在训练t时刻的时候,出现了t-1的参数,因此对单个的求导就变成了对整个之前状态的求导之和。
也正是因为存在长依赖关系,BPTT无法解决长时依赖问题(即当前的输出与前面很长的一段序列有关,一般超过十步就无能为力了),因为BPTT会带来所谓的梯度消失或梯度爆炸问题(the vanishing/exploding gradient problem)。
这篇文章很好的解释了为什么会产生梯度消失和为什么会梯度爆炸的问题,其实主要问题就是因为在BPTT算法中,以w为例,其求导过程的链太长,而太长的求导链在以tanh为激活函数(其求导值在0~1之间的BPTT中,连乘就会使得最终的求导为0,这就是梯度消失问题,也就是t时刻已经学习不到t-N时刻的参数了。当然,有很多方法去解决这个问题,如LSTMs便是专门应对这种问题的,还有一些方法,比如设计一个更好的初始参数以及更换激活函数(如换成ReLU激活函数)。
参数量
model.add(Embedding(output_dim=32, input_dim=2800, input_length=380))
model.add(SimpleRNN(units=16))
model.add(Dense(uints=256, activation=relu))
...
model.summary()
#output
simple_rnn_1 (SimpleRNN) param #
dense_1 (Dense) param #
其中:784=16+1616+1632( WhvWhv + WhhWhh + bhbh)
LSTM
假设我们试着去预测“I grew up in France... I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN会丧失学习到连接如此远的信息的能力。在理论上,RNN绝对可以处理"长期依赖"问题。人们可以仔细挑选参数来解决这类问题中的最初级形式,但在实践中,RNN 肯定不能够成功学习到这些知识。Bengio, et al.等人对该问题进行了深入的研究,他们发现一些使训练 RNN 变得非常困难的根本原因。
然而,幸运的是,LSTM 并没有这个问题!
LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构。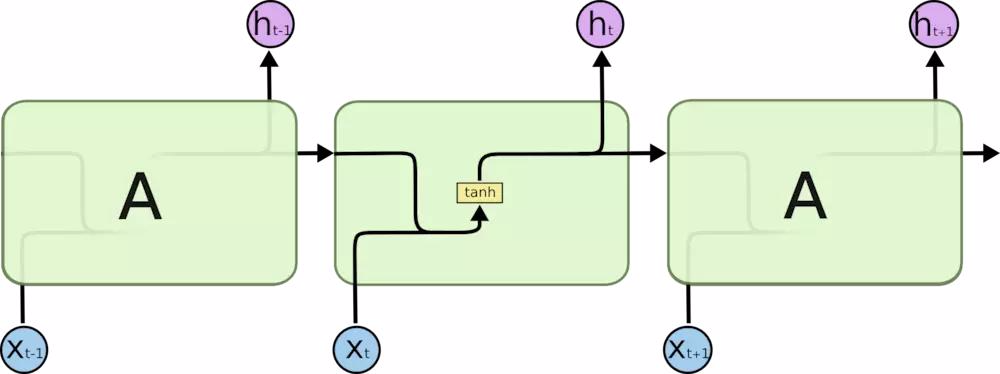
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于单一神经网络层,以一种非常特殊的方式进行交互。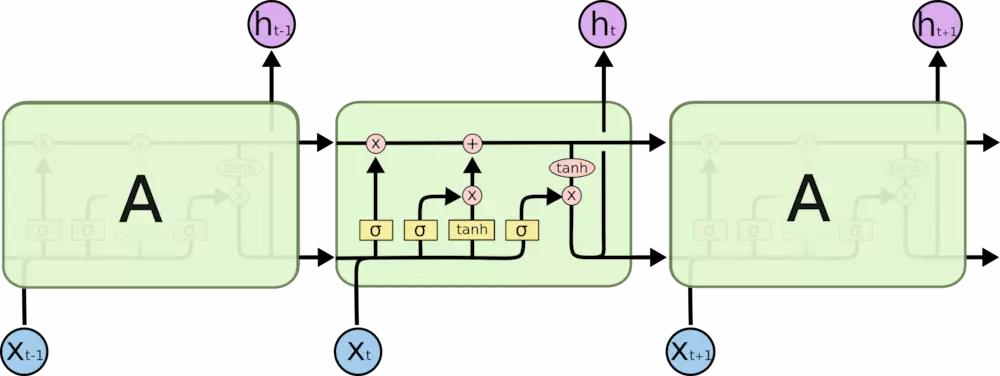
核心思想
LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。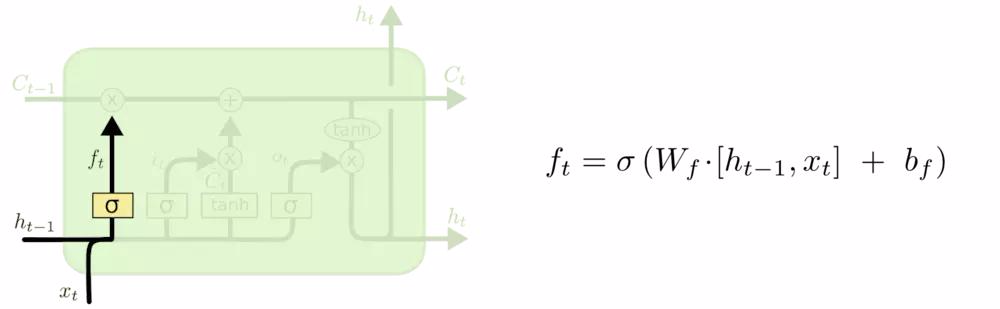
下一步是确定什么样的新信息被存放在细胞状态中。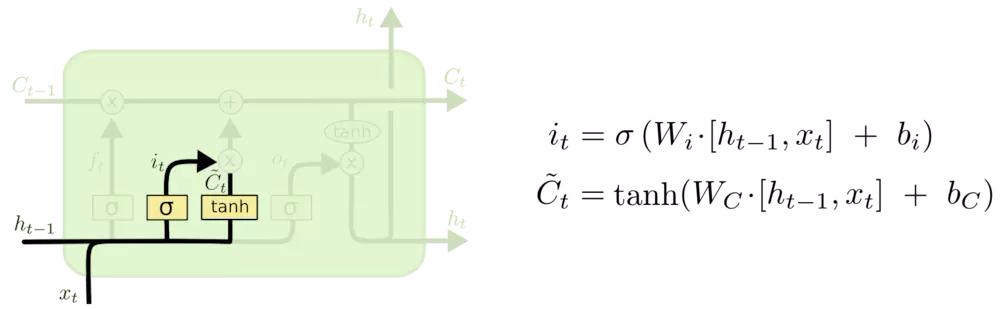
我们把旧状态与 ftft 相乘,丢弃掉我们确定需要丢弃的信息。接着加上 it∗C~tit∗C~t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。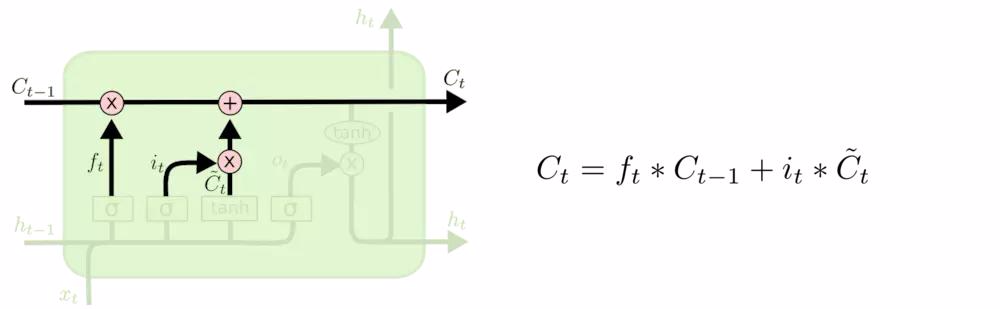
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。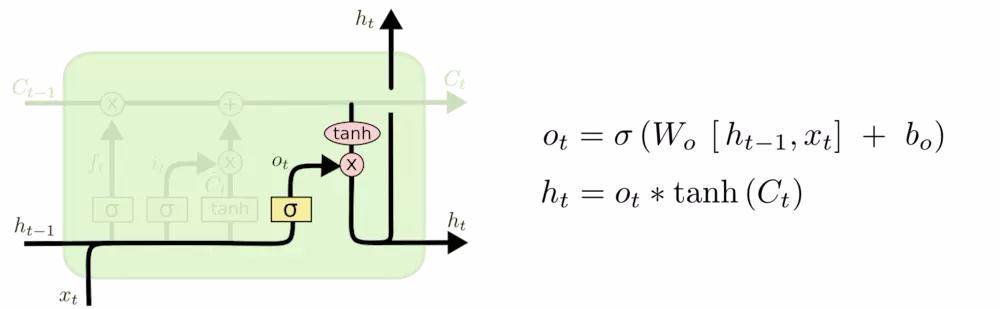
我们到目前为止都还在介绍正常的 LSTM。但是不是所有的 LSTM 都长成一个样子的。实际上,几乎所有包含 LSTM 的论文都采用了微小的变体。
图中最上面的一条线的状态即 s(t) 代表了长时记忆,而下面的 h(t)则代表了工作记忆或短时记忆。
参数量
model.add(Embedding(output_dim=32, input_dim=2800, input_length=380))
model.add(LSTM(32))
model.add(Dense(uints=256, activation=relu))
...
model.summary()
#output
lstm_1 (LSTM) param #
其中:8320=(32+32)324+4*32( WoWo + WCWC + WiWi + WfWf + bobo + bCbC + bibi + bfbf)。
GRU
LSTM有很多变体,其中较大改动的是Gated Recurrent Unit (GRU),这是由 Cho, et al. (2014)提出。它将忘记门和输入门合成了一个单一的 更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM模型要简单。效果和LSTM差不多,但是参数少了1/3,不容易过拟合。
参考:
来自为知笔记(Wiz)
RNN & LSTM & GRU 的原理与区别的更多相关文章
- RNN,LSTM,GRU基本原理的个人理解
记录一下对RNN,LSTM,GRU基本原理(正向过程以及简单的反向过程)的个人理解 RNN Recurrent Neural Networks,循环神经网络 (注意区别于recursive neura ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- RNN/LSTM/GRU/seq2seq公式推导
概括:RNN 适用于处理序列数据用于预测,但却受到短时记忆的制约.LSTM 和 GRU 采用门结构来克服短时记忆的影响.门结构可以调节流经序列链的信息流.LSTM 和 GRU 被广泛地应用到语音识别. ...
- RNN - LSTM - GRU
循环神经网络 (Recurrent Neural Network,RNN) 是一类具有短期记忆能力的神经网络,因而常用于序列建模.本篇先总结 RNN 的基本概念,以及其训练中时常遇到梯度爆炸和梯度消失 ...
- [PyTorch] rnn,lstm,gru中输入输出维度
本文中的RNN泛指LSTM,GRU等等 CNN中和RNN中batchSize的默认位置是不同的. CNN中:batchsize的位置是position 0. RNN中:batchsize的位置是pos ...
- RNN, LSTM, GRU cells
项目需要,先简记cell,有时间再写具体改进原因 RNN cell LSTM cell: GRU cell: reference: 1.https://towardsdatascience.com/a ...
- 自己动手实现深度学习框架-7 RNN层--GRU, LSTM
目标 这个阶段会给cute-dl添加循环层,使之能够支持RNN--循环神经网络. 具体目标包括: 添加激活函数sigmoid, tanh. 添加GRU(Gate Recurrent U ...
- NLP教程(5) - 语言模型、RNN、GRU与LSTM
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- RNN,GRU,LSTM
2019-08-29 17:17:15 问题描述:比较RNN,GRU,LSTM. 问题求解: 循环神经网络 RNN 传统的RNN是维护了一个隐变量 ht 用来保存序列信息,ht 基于 xt 和 ht- ...
随机推荐
- git命令上传项目到码云总结
码云上传项目git命令总结: git clone https://git.oschina.net/xh-lxx/xh-lxx.oschina.io.git 进入到克隆下来的文件夹,然后操作git命令 ...
- 【AGC012E】 Camel and Oases ST表+状压dp
题目大意:一排点,两点间有距离. 初始你有一个行走值$v$,如果相邻两点距离不超过$v$你可以自由在这两点行走. 当$v$大于$0$时,你可以选择某一时刻突然飞到任意点,这样做后$v$会减半(下取整) ...
- WebAPI POST GET
简而言之,在WEBAPI中采用GET方法方法时在接受参数的时候会在参数前申明 [fromuri]标注从uri中获取如: [HttpPost] public IHttpActionResult AddP ...
- Liunx-history命令
1. 查看历史命令执行记录 2. 查看命令cd 的历史执行记录 3. 执行历史记录中,序号为1的命令
- 2018春招-今日头条笔试题-第一题(python)
题目描述:2018春招-今日头条笔试题5题(后附大佬答案-c++版) 解题思路: 要想得到输入的数字列中存在相隔为k的数,可以将输入的数字加上k,然后判断其在不在输入的数字列中即可. #-*- cod ...
- notepad++中设置python运行
1. Notepad++ ->"运行"菜单->"运行"按钮 2. 在弹出的窗口内输入以下命令: cmd /k python "$(FULL ...
- 关于mpvue和wafer2-client-sdk的 微信登录失败,请检查网络状态
关于mpvue和wafer2-client-sdk的登录使用. 错误形式: <script> // import {get} from './util' import qcloud fro ...
- Python -- 数据结构实现
1.堆栈(pyStack.py) class PyStack: def __init__(self, size=20): self.stack = [] self.size = size self.t ...
- safari input默认样式
在i标签下嵌套一个input标签 设置了 -webkit-apprarence:none: 设置了宽高,和padding:3px 结果placeholder显示不全 经排查 这时候的input默认有 ...
- 11-hdfs-NameNode-HA-wtihQJM解决单点故障问题
在hdfs中, NN只有一个, 但其中保存的数据尤其重要, 所以需要将元数据保存, 其中源数据有2个形式, fsimage 和 edit文件, 最简单的解决方法就是复制fsimage, 并在文件修改时 ...