初学Hadoop之图解MapReduce与WordCount示例分析
1、MapReduce整体流程
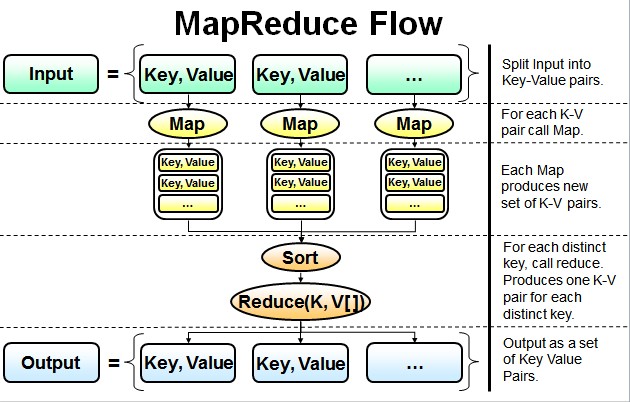
- 并行读取文本中的内容,然后进行MapReduce操作。
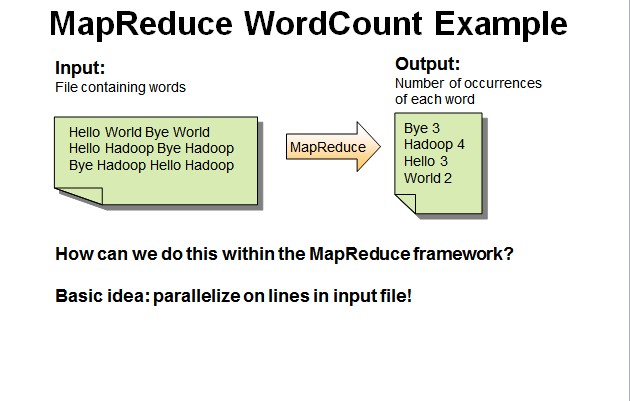
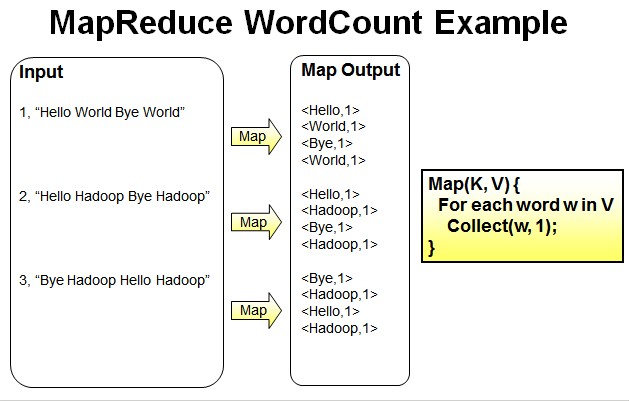
- Map过程:并行读取文本,对读取的单词进行map操作,每个词都以<key,value>形式生成。
我的理解:
一个有三行文本的文件进行MapReduce操作。
读取第一行Hello World Bye World ,分割单词形成Map。
<Hello,1> <World,1> <Bye,1> <World,1>
读取第二行Hello Hadoop Bye Hadoop ,分割单词形成Map。
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>
读取第三行Bye Hadoop Hello Hadoop,分割单词形成Map。
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
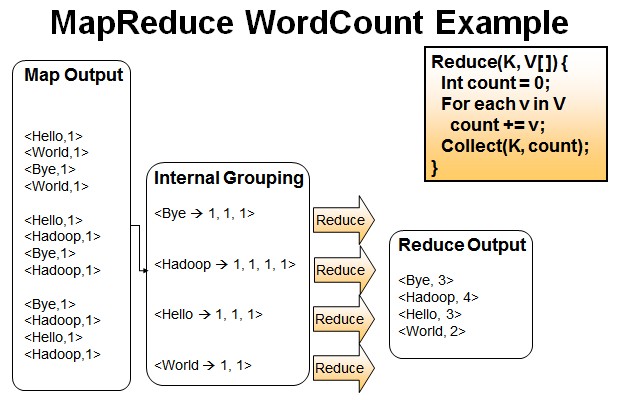
- Reduce操作是对map的结果进行排序,合并,最后得出词频。
我的理解:
经过进一步处理(combiner),将形成的Map根据相同的key组合成value数组。
<Bye,1,1,1> <Hadoop,1,1,1,1> <Hello,1,1,1> <World,1,1>
循环执行Reduce(K,V[]),分别统计每个单词出现的次数。
<Bye,3> <Hadoop,4> <Hello,3> <World,2>
2、WordCount源码
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
*
* 描述:WordCount explains by York
* @author Hadoop Dev Group
*/
publicclass WordCount {
/**
* 建立Mapper类TokenizerMapper继承自泛型类Mapper
* Mapper类:实现了Map功能基类
* Mapper接口:
* WritableComparable接口:实现WritableComparable的类可以相互比较。所有被用作key的类应该实现此接口。
* Reporter 则可用于报告整个应用的运行进度,本例中未使用。
*
*/
publicstaticclass TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
/**
* IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类实现了WritableComparable接口,
* 都能够被串行化从而便于在分布式环境中进行数据交换,你可以将它们分别视为int,String 的替代品。
* 声明one常量和word用于存放单词的变量
*/
privatefinalstatic IntWritable one =new IntWritable(1);
private Text word =new Text();
/**
* Mapper中的map方法:
* void map(K1 key, V1 value, Context context)
* 映射一个单个的输入k/v对到一个中间的k/v对
* 输出对不需要和输入对是相同的类型,输入对可以映射到0个或多个输出对。
* Context:收集Mapper输出的<k,v>对。
* Context的write(k, v)方法:增加一个(k,v)对到context
* 程序员主要编写Map和Reduce函数.这个Map函数使用StringTokenizer函数对字符串进行分隔,通过write方法把单词存入word中
* write方法存入(单词,1)这样的二元组到context中
*/
publicvoid map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr =new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} publicstaticclass IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result =new IntWritable();
/**
* Reducer类中的reduce方法:
* void reduce(Text key, Iterable<IntWritable> values, Context context)
* 中k/v来自于map函数中的context,可能经过了进一步处理(combiner),同样通过context输出
*/
publicvoid reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum =0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} publicstaticvoid main(String[] args) throws Exception {
/**
* Configuration:map/reduce的j配置类,向hadoop框架描述map-reduce执行的工作
*/
Configuration conf =new Configuration();
String[] otherArgs =new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length !=2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job =new Job(conf, "word count"); //设置一个用户定义的job名称
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //为job设置Mapper类
job.setCombinerClass(IntSumReducer.class); //为job设置Combiner类
job.setReducerClass(IntSumReducer.class); //为job设置Reducer类
job.setOutputKeyClass(Text.class); //为job的输出数据设置Key类
job.setOutputValueClass(IntWritable.class); //为job输出设置value类
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //为job设置输入路径
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));//为job设置输出路径
System.exit(job.waitForCompletion(true) ?0 : 1); //运行job
}
}
3、WordCount逐行解析
- 对于map函数的方法。
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {…}
这里有三个参数,前面两个Object key, Text value就是输入的key和value,第三个参数Context context这是可以记录输入的key和value,例如:context.write(word, one);此外context还会记录map运算的状态。
- 对于reduce函数的方法。
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {…}
reduce函数的输入也是一个key/value的形式,不过它的value是一个迭代器的形式Iterable<IntWritable> values,也就是说reduce的输入是一个key对应一组的值的value,reduce也有context和map的context作用一致。
至于计算的逻辑则需要程序员编码实现。
- 对于main函数的调用。
首先是:
Configuration conf = new Configuration();
运行MapReduce程序前都要初始化Configuration,该类主要是读取MapReduce系统配置信息,这些信息包括hdfs还有MapReduce,也就是安装hadoop时候的配置文件例如:core-site.xml、hdfs-site.xml和mapred-site.xml等等文件里的信息,有些童鞋不理解为啥要这么做,这个是没有深入思考MapReduce计算框架造成,我们程序员开发MapReduce时候只是在填空,在map函数和reduce函数里编写实际进行的业务逻辑,其它的工作都是交给MapReduce框架自己操作的,但是至少我们要告诉它怎么操作啊,比如hdfs在哪里,MapReduce的jobstracker在哪里,而这些信息就在conf包下的配置文件里。
接下来的代码是:
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
If的语句好理解,就是运行WordCount程序时候一定是两个参数,如果不是就会报错退出。至于第一句里的GenericOptionsParser类,它是用来解释常用hadoop命令,并根据需要为Configuration对象设置相应的值,其实平时开发里我们不太常用它,而是让类实现Tool接口,然后再main函数里使用ToolRunner运行程序,而ToolRunner内部会调用GenericOptionsParser。
接下来的代码是:
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
第一行就是在构建一个job,在mapreduce框架里一个mapreduce任务也叫mapreduce作业也叫做一个mapreduce的job,而具体的map和reduce运算就是task了,这里我们构建一个job,构建时候有两个参数,一个是conf这个就不累述了,一个是这个job的名称。
第二行就是装载程序员编写好的计算程序,例如我们的程序类名就是WordCount了。这里我要做下纠正,虽然我们编写mapreduce程序只需要实现map函数和reduce函数,但是实际开发我们要实现三个类,第三个类是为了配置mapreduce如何运行map和reduce函数,准确的说就是构建一个mapreduce能执行的job了,例如WordCount类。
第三行和第五行就是装载map函数和reduce函数实现类了,这里多了个第四行,这个是装载Combiner类,这个类和mapreduce运行机制有关,其实本例去掉第四行也没有关系,但是使用了第四行理论上运行效率会更好。
接下来的代码:
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
这个是定义输出的key/value的类型,也就是最终存储在hdfs上结果文件的key/value的类型。
最后的代码是:
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
第一行就是构建输入的数据文件,第二行是构建输出的数据文件,最后一行如果job运行成功了,我们的程序就会正常退出。
初学Hadoop之图解MapReduce与WordCount示例分析的更多相关文章
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一.MapReduce介绍 (最好以下面的两个示例来理解原理) 1. MapReduce的基本思想 Map-reduce的思想就是“分而治之” Map Mapper负责“分”,即把复杂的任务分解为若干 ...
- Hadoop实战3:MapReduce编程-WordCount统计单词个数-eclipse-java-ubuntu环境
之前习惯用hadoop streaming环境编写python程序,下面总结编辑java的eclipse环境配置总结,及一个WordCount例子运行. 一 下载eclipse安装包及hadoop插件 ...
- Hadoop实战5:MapReduce编程-WordCount统计单词个数-eclipse-java-windows环境
Hadoop研发在java环境的拓展 一 背景 由于一直使用hadoop streaming形式编写mapreduce程序,所以目前的hadoop程序局限于python语言.下面为了拓展java语言研 ...
- Hadoop实战2:MapReduce编程-WordCount实例-streaming-python环境
这是搭建hadoop环境后的第一个MapReduce程序: 基于hadoop streaming的python的脚本: 1 map.py文件,把文本的内容划分成单词: #!/usr/bin/pytho ...
- WordCount示例深度学习MapReduce过程(1)
我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测试Hadoop安装是否成功.在终端中用命令创建一个文件夹,简单的向两个文件中各写入一段话,然后运行Hadoop,Wou ...
- WordCount示例深度学习MapReduce过程
转自: http://blog.csdn.net/yczws1/article/details/21794873 . 我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测 ...
- MapReduce 编程模型 & WordCount 示例
学习大数据接触到的第一个编程思想 MapReduce. 前言 之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧.一来是加 ...
- 三.hadoop mapreduce之WordCount例子
目录: 目录见文章1 这个案列完成对单词的计数,重写map,与reduce方法,完成对mapreduce的理解. Mapreduce初析 Mapreduce是一个计算框架,既然是做计算的框架,那么表现 ...
随机推荐
- SQL中select与set的区别
转自 : http://www.cnblogs.com/4mylife/archive/2012/10/25/2738466.html 下表列出 SET 与 SELECT 的区别 SELECT S ...
- oracle共享与专用模式的动态转换及区别(转载)
一直没对专用于共享的互换搞清楚,找到了这篇文章 http://blog.csdn.net/tianlesoftware/archive/2010/06/26/5695784.aspx ,让我实践了一把 ...
- tornado-通过判断后台数据限制登陆--简单的
import tornado.ioloop import tornado.web import tornado.httpserver # 非阻塞 import tornado.options # 提供 ...
- uva-10420-排序
根据国家名字统计人数,然后排序 #include<stdio.h> #include<iostream> #include<queue> #include<m ...
- ERROR 1222 (21000): The used SELECT statements have a different number of columns :
转自:https://blog.csdn.net/linshichen/article/details/52484224
- VSS SVN GIT SVN 加锁签出
VSS TFS SVN GIT VSS 两大功能: 1.签出后加锁,别人不能签出,独占签出. 2.在服务端可以查看哪些用户签出了哪些文件. 3.查看所有签出未签入的文件列表,SVN未发现此功能. 缺点 ...
- 解决打开visio2013提示windows正在配置的问题
由于之前装过office2007.也装过2010版本.新安装visio2013就会出现如下情况 解决办法: 主要是要清理完visio2010及之前的那些没用选项 1.在cmd命令下打开regedit注 ...
- License 校验
1:了解keytool 的一些命令 http://www.micmiu.com/lang/java/keytool-start-guide/ 本人在github找的一个demo:https://gi ...
- 9 并发编程-(线程)-守护线程&互斥锁
一 .守护线程 无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁 需要强调的是:运行完毕并非终止运行 1.对主进程来说,运行完毕指的是主进程代码运行完毕 2.对主线程来说,运行完毕 ...
- locate包的安装
linux中locate命令可以快速定位我们需要查找的文件,但是在yum中,locate的安装包名为 mlocate(yum list | grep locate可以查看),安装方法: yum -y ...