Scrapy:创建爬虫程序的方式
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0,
在Scrapy中,建立爬虫程序或项目的方式有两种(在孤读过Scrapy的大部分文档后):
1.继承官方Spider类(5个)
2.命令行工具scrapy genspider(4个)
方式一:继承官方Spider类
下图是官网的示例:继承了scrapy.Spider
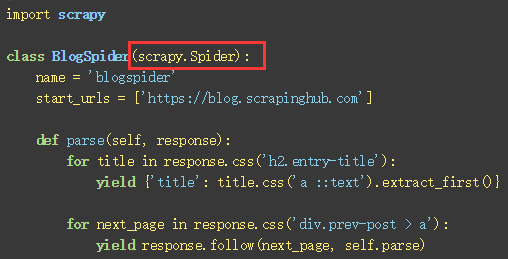
这里的scrapy.Spider是在scrapy包的__init__.py中导入的,实际上来自于scrapy.spiders.Spiders:

除了Spider类以外,scrapy内部还有几个Generic Spiders类:
-class scrapy.spiders.CrawlSpider
-class scrapy.spiders.XMLFeedSpider
-class scrapy.spiders.CSVFeedSpider
-class scrapy.spiders.SitemapSpider
上面的几个Spider类都可以被继承以实现自己的爬虫程序(目前自己不是很熟悉,仅在前面测试过SitemapSpider,但其官网SitemapSpider的示例没有name属性,故需要添加后才可以运行)。
更多资料:Scrapy官方Spiders文档
方式二:命令行工具scrapy genspider
还可以使用scrapy genspider命令建立爬虫程序。
在官文Command line tool介绍中,genspider是一个global命令,这意味着可以使用genspider在 Scrapy项目内 或 外 都可以建立爬虫程序。
下面几个配置项需要注意:
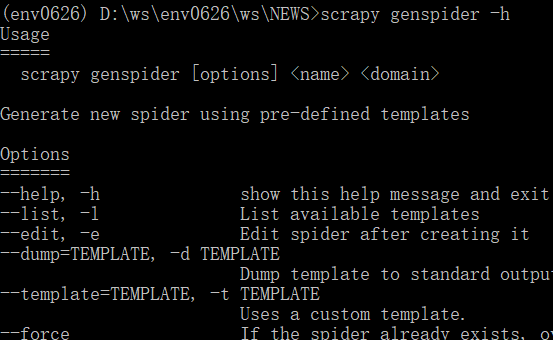
-scrapy genspider -h
genspider的帮助信息(下图展示了部分Usage信息)。
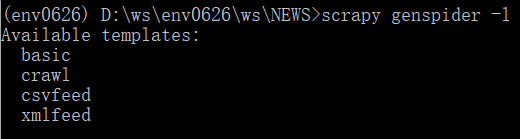
-scrapy genspider -l
显示可以使用的爬虫模板,就是 新建爬虫程序可以继承哪个内部爬虫类。这里存在一个疑问,没有SitemapSpider的模板。
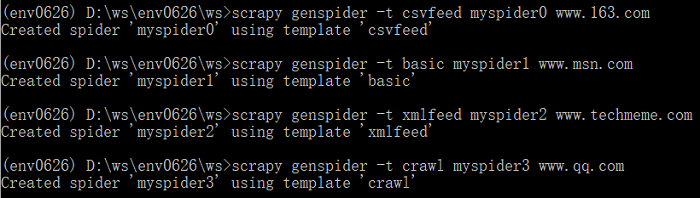
-scrapy genspider -t TEMPLATE ...
使用TEMPLATE对应的内部爬虫类建立爬虫程序(下图分别用四种模板建立了四个爬虫程序,其实,basic是默认的,可以不用写)。
打开其中的www.techmeme.com的爬虫程序看看:使用模板xmlfeed建立,继承了XMLFeedSpider。
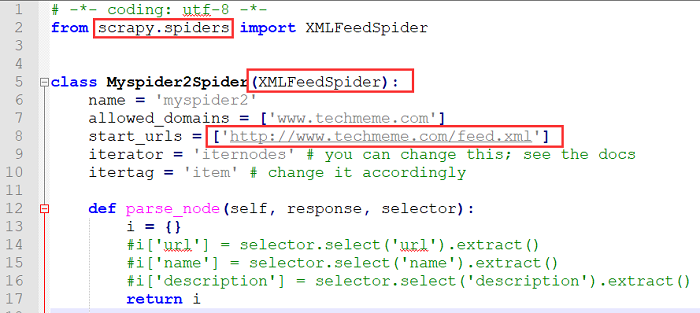
但这里存在问题:www.techmeme.com(一个很有名的科技资讯网站)的主页是HTTPS的,而这里的start_urls显示的是HTTP!
前面看资料说在DNS服务器还是什么地方可以配置自动跳转到HTTPS版本。 可是, 这里是否需要更改为HTTPS呢?孤认为是需要的!做 试验 验证会更好哦!)
注意,上面是使用genspider命令在项目外建立爬虫程序,而要在项目内建立爬虫程序时,需要选择Scrapy项目中的spiders目录,否则,无法自动检测到(按理说是这样,总不能在项目下的任何位置建立吧,项目要有项目的规矩)。
总结
从建立爬虫程序的效率来看,使用命令行的方式快速很多,但不能创建SitemapSpider类;
上面讲的都是 继承Scrapy内部的爬虫类, 那么,是否可以 继承自定义的爬虫类 呢?按理说是可以的,实际上也应该可以,需要验证;
无论哪种方式,都需要后续更多的coding工作,因此,在继续之前,请熟悉Scrapy的爬虫的工作机制,见官文Spiders;
如果还有更多的方式,或者,读者自己研发的方式,欢迎告知,会很感激;
当然,使用其它命令行工具也可以建立一些看不见的爬虫程序,就不是本文所涉及的了,需要更理解Scrapy才可以。
0704-0951 Update
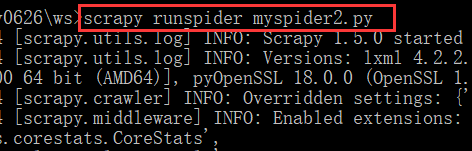
关于www.techmeme.com的爬虫程序,使用runspider进行了测试:
-默认的HTTP时会发生 重定向(302)

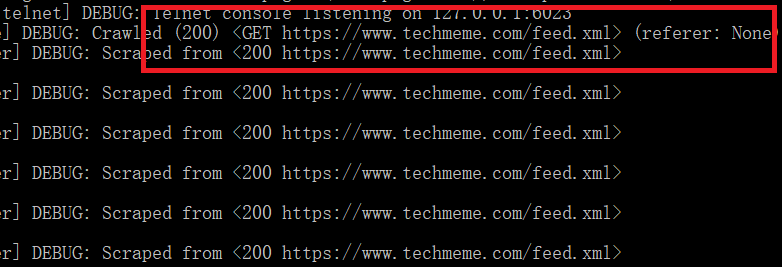
-更改为HTTPS后则不会 发生 重定向
也可以使用scrapy parse命令进行测试,但是,首先要将上面的myspider2放到某个Scrapy项目的spiders目录下:
scrapy parse --spider=myspider2 -d 3 "https://www.techmeme.com"
Scrapy:创建爬虫程序的方式的更多相关文章
- Scrapy:运行爬虫程序的方式
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0, 在创建了爬虫程序后,就可以运行爬虫程序了.Scrapy中介绍了几种运行爬虫程序的方式,列举如下: -命令行工具之s ...
- 使用scrapy 创建爬虫项目
使用scrapy 创建爬虫项目 步骤一: scrapy startproject tutorial 步骤二: you can start your first spider with: cd tuto ...
- Scrapy创建爬虫项目
1.打开cmd命令行工具,输入scrapy startproject 项目名称 2.使用pycharm打开项目,查看项目目录 3.创建爬虫,打开CMD,cd命令进入到爬虫项目文件夹,输入scrapy ...
- Scrapy框架-爬虫程序相关属性和方法汇总
一.爬虫项目类相关属性 name:爬虫任务的名称 allowed_domains:允许访问的网站 start_urls: 如果没有指定url,就从该列表中读取url来生成第一个请求 custom_se ...
- 使用Scrapy编写爬虫程序中遇到的问题及解决方案记录
1.创建与域名不一致的Request时,请求会报错 解决方法:创建时Request时加上参数dont_filter=True 2.当遇到爬取失败(对方反爬检测或网络问题等)时,重试,做法为在解析res ...
- scrapy工具创建爬虫工程
1.scrapy创建爬虫工程:scrapy startproject scrape_project_name >scrapy startproject books_scrapeNew Scrap ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 十 web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --upgrade pip2.安装,wheel(建议网络安装) pip install wheel ...
- liunx系统下crontab定时启动Scrapy爬虫程序
定时启动爬虫 # 查看命令得绝对路径 # which scrapy # cd到爬虫得项目目录下 + scrapy命令得绝对路径 + 启动命令 */5 * * * * cd /opt/mafengwo/ ...
随机推荐
- 【BZOJ4774】修路(动态规划,斯坦纳树)
[BZOJ4774]修路(动态规划,斯坦纳树) 题面 BZOJ 题解 先讲怎么求解最小斯坦纳树. 先明白什么是斯坦纳树. 斯坦纳树可以认为是最小生成树的一般情况.最小生成树是把所有给定点都要加入到联通 ...
- Nginx web服务优化 (一)
1.Nginx基本安全优化 a.更改配置文件参数隐藏版本 编辑nginx.conf配置文件增加参数,实现隐藏Nginx版本号的方式如下.在nginx配置文件nginx.conf中的http标签段内加入 ...
- 【Asp.net入门08】第一个Asp.net应用程序-创建窗体并设置其样式
本节内容: 添加一个aspx窗体并设计窗体内容 为aspx窗体添加样式 前面我们为PartyInvites应用程序项目添加了两个c#文件:GuestResponse.cs和ResponseReposi ...
- 【Asp.net入门04】第一个ASP.NET 应用程序-如何添加Web窗体到网站中
添加Web窗体 本部分内容: 什么是web form 怎样添加web form 1.添加Web窗体到项目中 Web 窗体是一项 ASP.NET 功能,您可以使用它为 Web 应用程序创建用户界面.We ...
- Nginx反向代理websocket配置实例(官网)
https://www.nginx.com/blog/websocket-nginx/ Blog Tech Rick Nelson of NGINX, Inc. May 16, 2014 NG ...
- R kernel for Jupyter Notebook 支持r
1/2) Installing via supplied binary packages(default on Windows + Mac OS X) You can install all pack ...
- linux缓存手动清理
一般情况下不建议这么做, 如果你确定向的话还是可以的首先运行sync把未存盘的cache都写入磁盘,稍等片刻, 或者是直接运行sync 两遍 然后echo 1 试试应该大部分缓存可以释放 释放ca ...
- logstash过滤配置
input { redis { host => "127.0.0.1" port => 6380 data_type => "list" ke ...
- 一篇很棒的 MySQL 触发器学习教程
一.触发器概念 触发器(trigger):监视某种情况,并触发某种操作,它是提供给程序员和数据分析员来保证数据完整性的一种方法,它是与表事件相关的特殊的存储过程,它的执行不是由程序调用,也不是手工启动 ...
- excel sum求和遇到的问题及解决
在偶遇的,借助excel公式sum对一个数字数组进行求和,结果为0,很是诧异,当然原因就是,数组里的数字是“常规”格式,不是“数值”格式,由于系统生成的excel,不方便生成的同时再做格式的设置,于是 ...