python操作oracle数据库-查询
python操作oracle数据库-查询
参照文档
http://www.oracle.com/technetwork/cn/articles/dsl/mastering-oracle-python-1391323-zhs.html
http://cx-oracle.readthedocs.io/en/latest/module.html
DB API 2.0 和 cx_Oracle 介绍
Python 数据库 API 规范 v2.0 是集体努力的成果,用于统一不同数据库系统的访问模型。拥有一组相对较少的方法和属性,在更换数据库供应商时就易于学习并保持一致。它不以任何方式将数据库对象映射到 Python 结构中。用户仍然需要手工编写 SQL。在更换到另一数据库后,此 SQL 可能需要重新编写。尽管如此,它还是出色妥善地解决了 Python 数据库的连接性问题。
该规范定义了 API 的各个部分,如模块接口、连接对象、游标对象、类型对象和构造器、DB API 的可选扩展以及可选的错误处理机制。
数据库和 Python 语言之间的网关是连接对象。它包含制作数据库驱动的应用程序所需的全部组件,不仅符合 DB API 2.0,而且是规范方法和属性的一个超集。在多线程的程序中,模块和连接可以在不同线程间共享,但是不支持游标共享。这一限制通常是可接受的,因为共享游标可能带来死锁风险。
Python 大量使用了异常模型,DB API 定义了若干标准异常,它们在调试应用程序中的问题时会非常有用。下面是一些标准异常,同时提供了原因类型的简要说明:
- Warning — 数据在执行插入操作时被截断,等等
- Error — 这里提到的除 Warning 外的所有异常的基类。
- InterfaceError — 数据库接口而非数据库本身故障(本例为 cx_Oracle 问题)
- DatabaseError — 严格意义上的数据库问题
- DataError — 包含如下结果数据的问题除数为 0,值超出范围等
- OperationalError — 与编程人员无关的数据库错误:连接丢失、内存分配错误、事务处理错误等
- IntegrityError — 数据库的关系完整性受到了影响,例如,外键约束失败
- InternalError — 数据库遇到内部错误,例如,游标无效、事务不同步
- ProgrammingError — 未找到表、SQL 语句中的语法错误、指定参数的数量错误等
- NotSupportedError — 调用的 API 部件并不存在
连接过程首先从连接对象开始,这是创建游标对象的基础。除游标操作外,连接对象还使用 commit() 和 rollback() 方法对事务进行管理。执行 SQL 查询、发出 DML/DCL 语句和获取结果这些过程均受游标控制。
第一步:导入cx_Oracle ,建立连接
>>> import cx_Oracle
>>> db = cx_Oracle.connect('hr', 'hrpwd', 'localhost:1521/XE')
>>> db1 = cx_Oracle.connect('hr/hrpwd@localhost:1521/XE')
>>> dsn_tns = cx_Oracle.makedsn('localhost', 1521, 'XE')
>>> print dsn_tns
(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521)))(CONNECT_DATA=(SID=XE)))
>>> db2 = cx_Oracle.connect('hr', 'hrpwd', dsn_tns)
# 通过客户端连接oracle
connection = cx_Oracle.connect('test/test@ORCL')
第二步:建立 Cursor 光标,查询
您可以使用连接对象的 cursor() 方法定义任意数量的游标。简单的程序使用一个游标就可以了,该游标可以一再地重复使用。但较大的项目可能要求几个不同的游标。
>>> cursor = db.cursor()
应用程序逻辑通常需要明确区分针对数据库发出的语句的各个处理阶段。这有助于更好地理解性能瓶颈并编写更快且经过优化的代码。语句处理分三个阶段:
- 分析(可选)
- cx_Oracle.Cursor.parse([statement])
实际上并不需要调用,因为在执行阶段会自动分析 SQL 语句。该方法可以用于在执行语句前对其进行验证。当这类语句中检测出错误时,会引发 DatabaseError 异常,相应的错误消息通常可能是“ORA-00900:invalid SQL statement, ORA-01031:insufficient privileges or ORA-00921:unexpected end of SQL command.”
- cx_Oracle.Cursor.parse([statement])
- 执行
- cx_Oracle.Cursor.execute(statement, [parameters], **keyword_parameters)
此方法可以接受单个参数 — 一条 SQL 语句 — 直接针对数据库来运行。通过 parameters 或 keyword_parameters 参数赋值的绑定变量可以指定为字典、序列或一组关键字参数。如果已经提供了字典或关键字参数,那么这些值将与名称绑定。如果给出的是序列,将根据这些值的位置对它们进行解析。如果是查询操作,此方法返回一个变量对象列表;如果不是,则返回 None。 - cx_Oracle.Cursor.executemany(statement, parameters)
对于批量插入尤其有用,因为它可以将所需的 Oracle 执行操作的数量限制为仅一个。有关如何使用该方法的详细信息,请参见下面的“一次多行”部分。
- cx_Oracle.Cursor.execute(statement, [parameters], **keyword_parameters)
- 获取(可选)— 仅用于查询(因为 DDL 和 DCL 语句不返回结果)。在不执行查询的游标上,这些方法将引发 InterfaceError 异常。
- cx_Oracle.Cursor.fetchall()
以字节组列表形式获取结果集中的所有剩余行。如果没有剩余的行,它返回一个空白列表。获取操作可以通过设置游标的 arraysize 属性进行调整,该属性可设置在每个底层请求中从数据库中返回的行数。arraysize 的设置越高,需要在网络中往返传输的次数越少。arraysize 的默认值为 1。 - cx_Oracle.Cursor.fetchmany([rows_no])
获取数据库中接下来的 rows_no 行。如果该参数未指定,该方法获取的行数是 arraysize 的数量。如果 rows_no 大于获取到的行的数目,该方法获取的行数是剩余的行数。 - cx_Oracle.Cursor.fetchone()
从数据库中获取单个字节组,如果没有剩余行,则返回 none。
- cx_Oracle.Cursor.fetchall()
在继续了解游标示例前,请先了解 pprint 模块的 pprint 函数。它用于以清晰、可读的形式输出 Python 数据结构。
# 获得游标对象
cursor = connection.cursor () try:
# 解析sql语句
cursor.parse("select * dual")
# 捕获SQL异常
except cx_Oracle.DatabaseError as e:
print(e) # ORA-00923: 未找到要求的 FROM 关键字 # 执行sql 语句
cursor.execute ("select * from dual")
# 提取一条数据,返回一个元祖
row = cursor.fetchone()
pprint(row) # ('X',)
数据类型
在获取阶段,基本的 Oracle 数据类型会映射到它们在 Python 中的等同数据类型中。cx_Oracle 维护一个单独的、有助于这一转换的数据类型集合。Oracle - cx_Oracle - Python 映射为
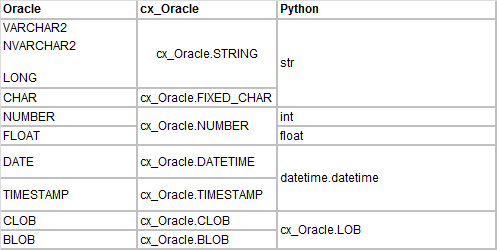
查询列字段信息
# 查询列字段信息
column_data_types = cursor.execute('SELECT * FROM python_modules')
pprint(column_data_types.description)
# [('MODULE_NAME', <class 'cx_Oracle.STRING'>, 50, 50, None, None, 0),
# ('FILE_PATH', <class 'cx_Oracle.STRING'>, 300, 300, None, None, 0)]
绑定变量模式
正如 Oracle 大师 Tom Kyte 介绍的那样,绑定变量是数据库开发的核心原则。它们不仅使程序运行更快,同时可以防范 SQL 注入攻击。
按名称传递绑定变量要求执行方法的 parameters 参数是一个字典或一组关键字参数。下面的 query1 和 query2 是等同的:
>>> named_params = {'dept_id':50, 'sal':1000}
>>> query1 = cursor.execute('SELECT * FROM employees WHERE department_id=:dept_id AND salary>:sal', named_params)
>>> query2 = cursor.execute('SELECT * FROM employees WHERE department_id=:dept_id AND salary>:sal', dept_id=50, sal=1000)
在使用已命名的绑定变量时,您可以使用游标的 bindnames() 方法检查目前已指定的绑定变量:
>>> print cursor.bindnames()
['DEPT_ID', 'SAL']
# 绑定变量模式查询
named_params = {'MODULE_NAME': 'cx_Oracle'}
cursor.execute('SELECT * FROM python_modules where MODULE_NAME =:MODULE_NAME',named_params)
# 在使用已命名的绑定变量时,您可以使用游标的 bindnames() 方法检查目前已指定的绑定变量:
print(cursor.bindnames())
pprint(cursor.fetchone())
# ('cx_Oracle',
# 'C:\\Program '
# 'Files\\Python36\\lib\\site-packages\\cx_Oracle.cp36-win_amd64.pyd')
# 在绑定时,您可以首先准备该语句,然后利用改变的参数执行 None。
# 根据绑定变量时准备一个语句即足够这一原则,
# Oracle 将如同在上例中一样对其进行处理。准备好的语句可执行任意次。
cursor.prepare('SELECT * FROM python_modules where MODULE_NAME =:MODULE_NAME')
cursor.execute(None, named_params)
pprint(cursor.fetchone())
# ('cx_Oracle',
# 'C:\\Program '
# 'Files\\Python36\\lib\\site-packages\\cx_Oracle.cp36-win_amd64.pyd')
一次多行
大型的插入操作不需求多次的单独插入,这是因为 Python 通过 cx_Oracle.Cursor.executemany 方法完全支持一次插入多行。
限制执行操作的数量极大地改善了程序性能,因此在编写存在大量插入操作的应用程序时应首先考虑这一功能。
我们首先为 Python 模块列表创建一个表,这次直接从 Python 开始。您将在以后删除该表。
import cx_Oracle
# 用于以清晰、可读的形式输出 Python 数据结构
from pprint import pprint
from sys import modules # 通过客户端连接oracle
connection = cx_Oracle.connect('test/test@testDB') print(connection.version) # 获得游标对象
cursor = connection.cursor () try:
# 解析sql语句
cursor.parse("select * dual")
# 捕获SQL异常
except cx_Oracle.DatabaseError as e:
print(e) # ORA-00923: 未找到要求的 FROM 关键字 # 执行sql 语句
cursor.execute ("select * from dual")
# 提取一条数据,返回一个元祖
row = cursor.fetchone()
pprint(row) # ('X',) create_table = """
CREATE TABLE python_modules (
module_name VARCHAR2(50) NOT NULL,
file_path VARCHAR2(300) NOT NULL
)
"""
# 执行创建表
create_flag = cursor.execute(create_table) # 添加模块信息
M = []
for m_name, m_info in modules.items():
try:
M.append((m_name, m_info.__file__))
except AttributeError:
pass print(len(M)) insert_sql = "INSERT INTO python_modules(module_name, file_path) VALUES (:1, :2)" # 在prepare之后,你再去execute的时候,就不用写上sql语句参数了
cursor.prepare(insert_sql)
cursor.executemany(None, M) # 注意,第一个参数是None
connection.commit() # 提交 # 查询
r = cursor.execute("SELECT COUNT(*) FROM python_modules")
pprint(cursor.fetchone()) # 查询列字段信息
column_data_types = cursor.execute('SELECT * FROM python_modules')
pprint(column_data_types.description)
# [('MODULE_NAME', <class 'cx_Oracle.STRING'>, 50, 50, None, None, 0),
# ('FILE_PATH', <class 'cx_Oracle.STRING'>, 300, 300, None, None, 0)] # 取10条记录信息
pprint(len(cursor.fetchmany(10))) # # 取之后所有记录信息,不包括前10条
pprint(len(cursor.fetchall())) # # 绑定变量模式查询
named_params = {'MODULE_NAME': 'cx_Oracle'}
cursor.execute('SELECT * FROM python_modules where MODULE_NAME =:MODULE_NAME',named_params)
# 在使用已命名的绑定变量时,您可以使用游标的 bindnames() 方法检查目前已指定的绑定变量:
print(cursor.bindnames())
pprint(cursor.fetchone())
# ('cx_Oracle',
# 'C:\\Program '
# 'Files\\Python36\\lib\\site-packages\\cx_Oracle.cp36-win_amd64.pyd') # 在绑定时,您可以首先准备该语句,然后利用改变的参数执行 None。
# 根据绑定变量时准备一个语句即足够这一原则,
# Oracle 将如同在上例中一样对其进行处理。准备好的语句可执行任意次。
cursor.prepare('SELECT * FROM python_modules where MODULE_NAME =:MODULE_NAME')
cursor.execute(None, named_params)
pprint(cursor.fetchone())
# ('cx_Oracle',
# 'C:\\Program '
# 'Files\\Python36\\lib\\site-packages\\cx_Oracle.cp36-win_amd64.pyd') # 删除python_modules
cursor.execute("DROP TABLE python_modules PURGE") # 关闭游标
cursor.close()
# 关闭连接
connection.close () # BLOB & CLOB 格式的创建:
#
# binary_content = cursor.var(cx_Oracle.BLOB)
# binary_content.setvalue(0, content)
python操作oracle数据库-查询的更多相关文章
- Python操作Oracle数据库:cx_Oracle
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- python操作oracle数据库
本文主要介绍python对oracle数据库的操作学习 包含:oracle数据库在Windows操作系统下的安装和配置.python需要安装的第三方拓展包以及基本操作的样例学习. 1 ...
- python接口自动化测试框架实现之操作oracle数据库
python操作oracle数据库需要使用到cx-oracle库. 安装:pip install cx-oracle python连接oracle数据库分以下步骤: 1.与oracle建立连接: 2. ...
- Python 连接Oracle数据库
连接:python操作oracle数据库 python——连接Oracle数据库 python模块:cx_Oracle, DBUtil 大概步骤: 1. 下载模块 cx_Oracle (注意版本) ...
- python对oracle数据库的操作
1 Oracle数据库 1.1 Oracle环境配置&客户端连接 1.1.1 下载安装Oracle绿色版客户端instantclient: 到o ...
- ASP.NET操作ORACLE数据库之模糊查询
ASP.NET操作ORACLE数据库之模糊查询 一.ASP.NET MVC利用OracleHelper辅助类操作ORACLE数据库 //连接Oracle数据库的连接字符串 string connect ...
- Python使用cx_Oracle模块连接操作Oracle数据库
1. 简单介绍 cx_Oracle 是一个用来连接并操作 Oracle 数据库的 Python 扩展模块, 支持包含 Oracle 9.2 10.2 以及 11.1 等版本号 2.安装 最好是去官网h ...
- Python使用cx_Oracle模块操作Oracle数据库--通过sql语句和存储操作
https://www.jb51.net/article/125160.htm?utm_medium=referral Python使用cx_Oracle调用Oracle存储过程的方法示例 http ...
- python_操作oracle数据库
1. cx_Oracle Python 连接Oracle 数据库,需要使用cx_Oracle 包. 该包的下载地址:http://cx-Oracle.sourceforge.net/ 下载的时候,注意 ...
随机推荐
- 在EF中使用MySQL的方法及常见问题
有时需要在网上租用空间或数据库,Mysql成本低一些,所以想将sql server转成mysql…… 注意:在安装Mysql时要选择文字集为utf8,否则将不能使用中文(当前也可以在创建数据库时使用u ...
- PHP二个高精确度数字相加减
1.相加 string bcadd(string left operand, string right operand, int [scale]); 2.相减 string bcsub(string ...
- Django介绍(2)
https://www.cnblogs.com/yuanchenqi/articles/5658455.html
- 简单的Java,Python,C,C++
Java 语言 //package main //注意不要添加包名称,否则会报错. import java.io.*; import java.util.*; cin.hasNext(); cin.h ...
- kallinux2.0安装网易云音乐
安装 dpkg -i netease-cloud-music_1.0.0_amd64.kali2.0(yagami).deb apt-get -f install dpkg -i netease-cl ...
- android public.xml 用法
一.android的pulibc.xml文件 如果你用 apktoool 反编译过 apk 就知道,反编译后res/values 下有一个 public.xml 文件,内容如图 这个东西有什么用呢 ...
- Amazon成本和产出的衡量方式
Amazon用一种T-Shirt Size 估计的方式来做项目. 产品经理会对每一条需求评估上业务影响力的尺寸,如:XXXL 影响一千万人以上或是可以占到上亿美金的市场,XXL,影响百万用户或是占了千 ...
- Spring注解使用和与配置文件的关系
Spring注解使用和与配置文件的关系 1 注解概述与容器管理机制 Spring 2.5 中除了提供 @Component 注释外,还定义了几个拥有特殊语义的注释,它们分别是:@Repositor ...
- swipe js bug
最近因为要写新的mobile site页面,有好几个页面上面必须用到photo slider. 使用插件: /* * Swipe 2.0 * * Brad Birdsall * Copyright 2 ...
- maven下@override标签失效
经常遇见此问题,现记录如下,以备下次查阅. 在pom文件添加配置: <plugin> <groupId>org.apache.maven.plugins</groupId ...