SKLearn数据集API(一)
注:本文是人工智能研究网的学习笔记
数据集一览
| 类型 | 获取方式 |
|---|---|
| 自带的小数据集 | sklearn.datasets.load_ |
| 在线下载的数据集 | sklearn.datasets.fetch_ |
| 计算机生成的数据集 | sklearn.datasets.make_ |
| svmlight/libsvm格式的数据集 | sklearn.datasets.load_svmlight_file(...) |
| mldata.org在线下载数据集 | sklearn.datasets.fetch_mldata(...) |
自带的小数据集
返回的是bunch对象,是字典类型
| 名称 | 数据包 |
|---|---|
| 鸢尾花数据集 | load_iris() |
| 乳腺癌数据集 | load_breast_cancer() |
| 手写数字数据集 | load_digits() |
| 糖尿病数据集 | load_diabetes() |
| 波士顿房价数据集 | load_boston() |
| 体能训练数据集 | load_linnerud() |
| 图像数据集 | load_sample_image(name) |
鸢尾花数据集
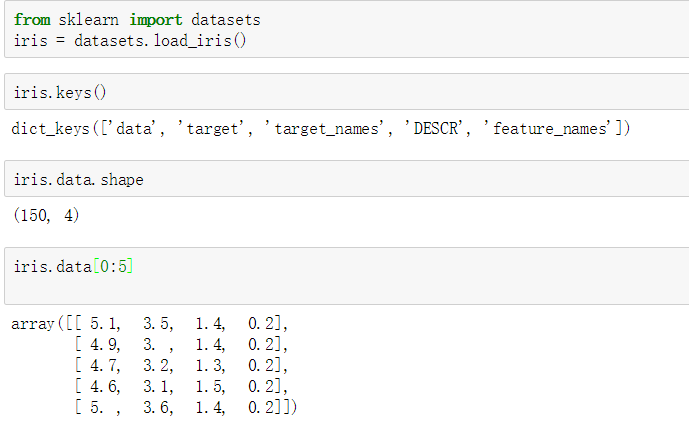
下面使用花萼长度单个特征来划分查看,这是探索性分析,当我们不知道该使用那些特征的时候,就这样查看一下。
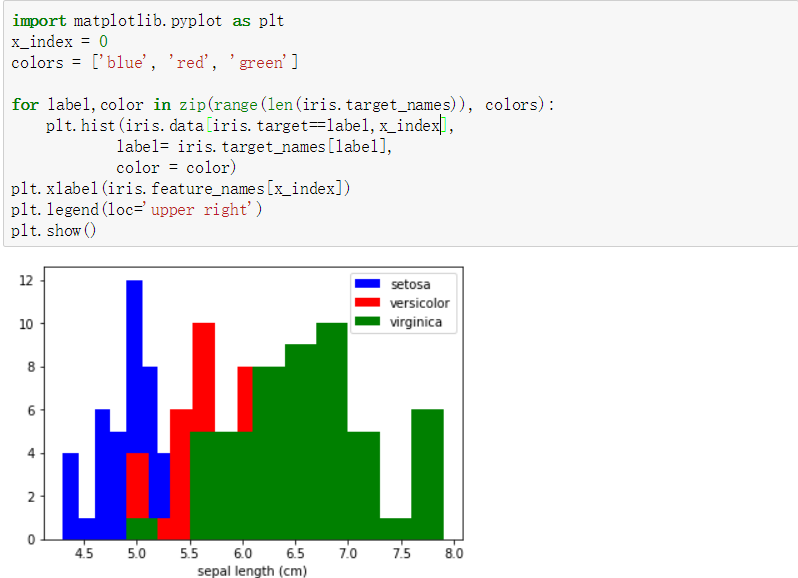
下面使用两个特征来划分查看
手写数字数据集

图像数据集

在线下载的数据集
使用datasets.get_data_home()函数获取下载目录
| 类型 | 获取方式 |
|---|---|
| 20类新闻文本数据集 | fetch_20newsgroups() / fetch_20newsgroups_vectorized() |
| 野外带标记人脸数据集 | fetch_lfw_people() / fetch_lfw_pairs() |
| Olivetti人脸数据集 | fetch_olivetti_faces() |
| rcvl多标签数据集 | fetch_rcvl() |
| 加利福尼亚房价数据集 | fetch_canlifornia_housing() |
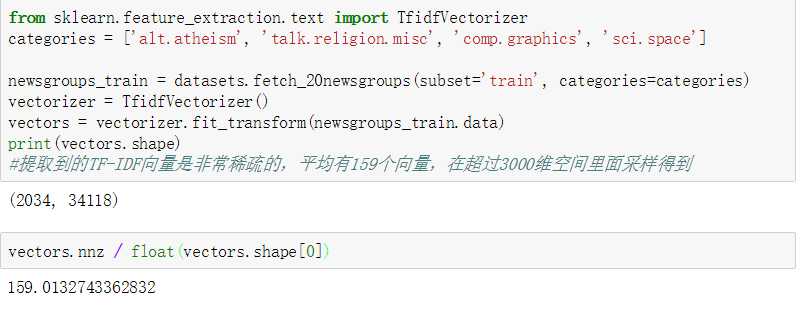
20类新闻文本数据集
包含了关于20个话题(topic)的18000条新闻报道,被分为两个子集: 训练集和测试集
| 函数 | 内容 |
|---|---|
| fetch_20newsgroups() | 原始的文本列表,该文本可以被输入到文本特征提取器sklearn.feature_extraction.text.CountVectorizer进一步处理得到特征向量 |
| fetch_20newsgroups_vectorized() | 返回一个直接可以使用的特征,无须在进行特征提取。 |
Olivetti人脸数据集
Olivetti人脸数据集是AT&T在1992-1994年手机的人脸数据集,包含了40个不同的目标,每个目标10张图片,某些目标的图像在不同的时间段采集,带有光照,面部表情(眼镜开闭,笑容),面部袭细节的各种变化,所有的人脸图像被正立的放在一个灰色的背景上。
每一张图像上有256个灰度级,用无符号8为来存。加载函数会将所有的图像转换成[0,1]区间上的浮点数,目标值target存放着0到39的数字代表人脸的类别标签。然而每个标签对应的人脸图像都只有10张,每张图像的分辨率是64*64。这个小数据集会更加适合来做无监督学习或者半监督学习。
SKLearn数据集API(一)的更多相关文章
- SKLearn数据集API(二)
注:本文是人工智能研究网的学习笔记 计算机生成的数据集 用于分类任务和聚类任务,这些函数产生样本特征向量矩阵以及对应的类别标签集合. 数据集 简介 make_blobs 多类单标签数据集,为每个类分配 ...
- 【学习笔记】sklearn数据集与估计器
数据集划分 机器学习一般的数据集会划分为两个部分: 训练数据:用于训练,构建模型 测试数据:在模型检验时使用,用于评估模型是否有效 训练数据和测试数据常用的比例一般为:70%: 30%, 80%: 2 ...
- sklearn——数据集调用及应用
忙了许久,总算是又想起这边还没写完呢. 那今天就写写sklearn库的一部分简单内容吧,包括数据集调用,聚类,轮廓系数等等. 自带数据集API 数据集函数 中文翻译 任务类型 数据规模 load_ ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- 机器学习笔记(四)--sklearn数据集
sklearn数据集 (一)机器学习的一般数据集会划分为两个部分 训练数据:用于训练,构建模型. 测试数据:在模型检验时使用,用于评估模型是否有效. 划分数据的API:sklearn.model_se ...
- sklearn数据集
数据集划分: 机器学习一般的数据集会划分为两个部分 训练数据: 用于训练,构建模型 测试数据: 在模型检验时使用,用于评估模型是否有效 sklearn数据集划分API: 代码示例文末! scikit- ...
- sklearn python API
sklearn python API LinearRegression from sklearn.linear_model import LinearRegression # 线性回归 # modul ...
- sklearn数据集划分
sklearn数据集划分方法有如下方法: KFold,GroupKFold,StratifiedKFold,LeaveOneGroupOut,LeavePGroupsOut,LeaveOneOut,L ...
- 深度学习常用数据集 API(包括 Fashion MNIST)
基准数据集 深度学习中经常会使用一些基准数据集进行一些测试.其中 MNIST, Cifar 10, cifar100, Fashion-MNIST 数据集常常被人们拿来当作练手的数据集.为了方便,诸如 ...
随机推荐
- vue_router 动态路由
配置子路由: 路由的视图都需要使用view-router 子路由也可以嵌套路由使用: children来做嵌套如上图 使用location.页面name就可以做页面跳转 mounted:挂载,延迟跳转 ...
- sklearn_k均值聚类
# 机器学习之k均值聚类 # coding:utf-8 import sklearn.datasets as datasets from sklearn.cluster import KMeans i ...
- imperva-代理安装
首先创建网关上面的监听端口
- 5 - django-csrf-session&cookie
目录 1 CSRF跨站请求伪造 1.1 CSRF攻击介绍及防御 1.2 防御CSRF攻击 1.2.1 验证 HTTP Referer 字段 1.2.2 在请求地址中添加 token 并验证 1.2.3 ...
- verilog中wire与reg类型的区别
每次写verilog代码时都会考虑把一个变量是设置为wire类型还是reg类型,因此把网上找到的一些关于这方面的资料整理了一下,方便以后查找. wire表示直通,即只要输入有变化,输出马上无条件地反映 ...
- linux下定时器介绍1
POSIX Timer 间隔定时器 setitimer 有一些重要的缺点,POSIX Timer 对 setitimer 进行了增强,克服了 setitimer 的诸多问题: 首先,一个进程同一时刻只 ...
- Django 2.0.3安装-压缩包方式
OS:Windows 10家庭中文版,CPU:Intel Core i5-8250U Python版本:Python 2.7,Python 3.6 Django版本:2.0.3(最新2.0.5) 解压 ...
- 洛谷P1177快速排序
传送门 #include<iostream> #include<cstdio> #include<cstring> #include<algorithm> ...
- master..xp_fileexist
declare @sql varchar(800) set @sql='E:\temp.dbf'create table #tb(a bit,b bit,c bit) insert into #t ...
- Linux下堆漏洞的利用机制
1.保护机制 )) malloc_printerr (check_action, "corrupted double-linked list", P); 这个就是所谓的堆指针的ch ...