虚拟机spark集群搭建
RDD弹性分布式数据集 (Resilient Distributed Dataset)
RDD只读可分区,数据集可以缓存在内存中,在多次计算间重复利用。
弹性是指内存不够时可以与磁盘进行交互
join操作就是笛卡尔积的操作过程
spark streaming
实时数据流
Discretized Streams (DStreams) 离散流
Graphx
图计算
spark sql
使用SchemaRDD来操作SQL
MLBase机器学习
MLlib算法库
Tachyon
高容错分布式文件系统
scala环境
tar -xvf scala-2.11.8.tgz
mv scala-2.11.8/ scala
#配置环境变量
export SCALA_HOME=/usr/local/scala
export PATH=$SCALA_HOME/bin:$PATH
[root@sjck-node01 ~]# scala -version
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
spark环境
tar -xvf spark-2.4.0-bin-hadoop2.7.tgz
mv scala-2.11.8/ scala
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
spark配置
cp spark-env.sh.template spark-env.sh
export JAVA_HOME=/usr/local/src/jdk/jdk1.8
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=sjck-node01
export SPARK_MASTER_HOST=sjck-node01
export SPARK_LOCAL_IP=sjck-node01
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
slaves配置
cp slaves.template slaves
sjck-node02
sjck-node03
copy到slave节点,配置对应的环境变量
scp -r /usr/local/scala/ sjck-node02:/usr/local/
scp -r /usr/local/spark-2.4.0-bin-hadoop2.7/ sjck-node02:/usr/local/
vim spark-env.sh
把SPARK_LOCAL_IP改成对应的ip
启动顺序,先启动hadoop,再启动spark
/usr/local/hadoop/sbin/start-all.sh
/usr/local/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
/usr/local/hadoop/sbin/stop-all.sh
/usr/local/spark-2.4.0-bin-hadoop2.7/sbin/stop-all.sh
[root@sjck-node01 ~]# /usr/local/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-sjck-node01.out
sjck-node02: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-sjck-node02.out
sjck-node03: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-sjck-node03.out
查看集群jps状态
[root@sjck-node01 ~]# jps
5233 Master
4595 NameNode
4788 SecondaryNameNode
5305 Jps
4942 ResourceManager
[root@sjck-node02 conf]# jps
3808 Worker
3538 DataNode
3853 Jps
3645 NodeManager
[root@sjck-node03 conf]# jps
3962 NodeManager
3851 DataNode
4173 Jps
4126 Worker
查看集群状态
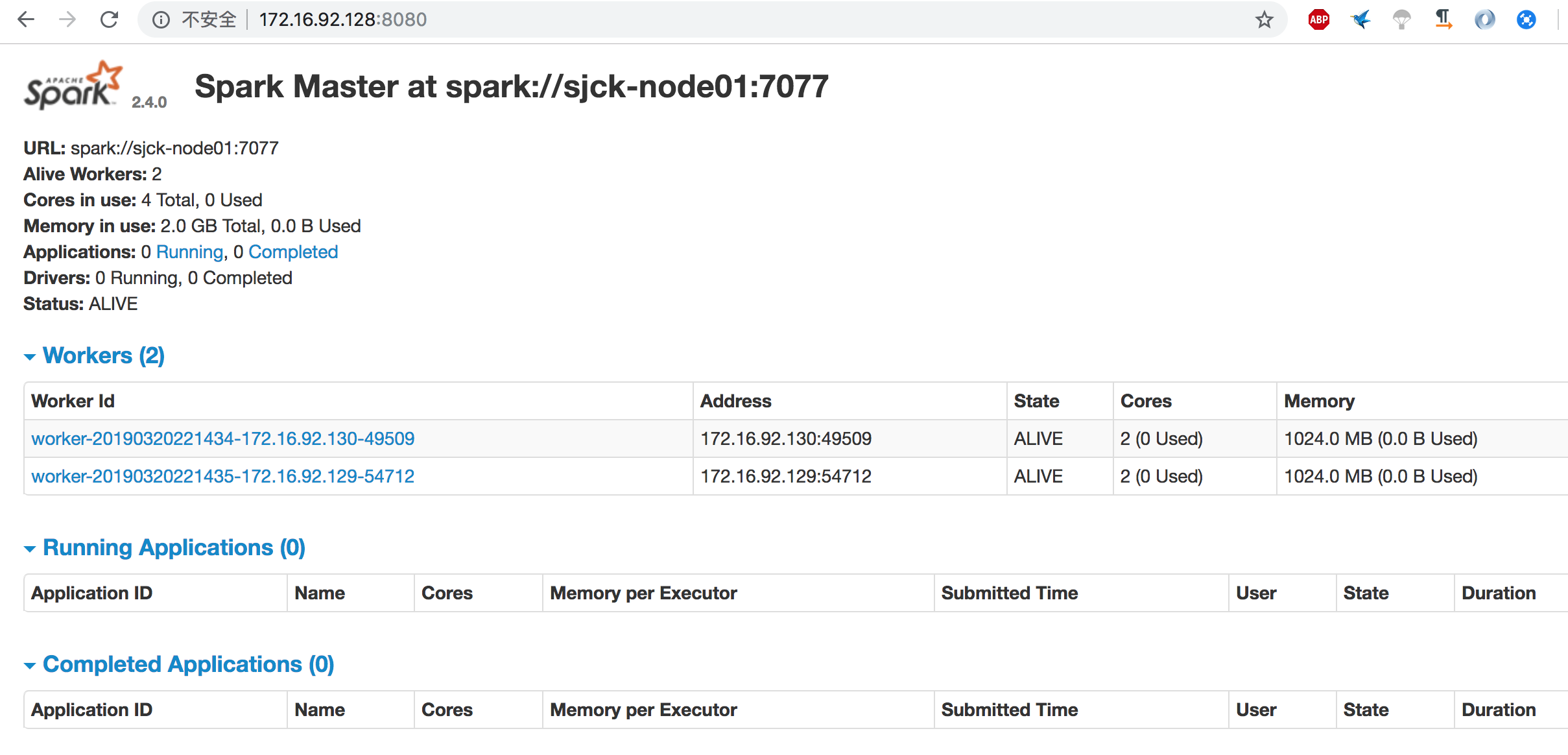
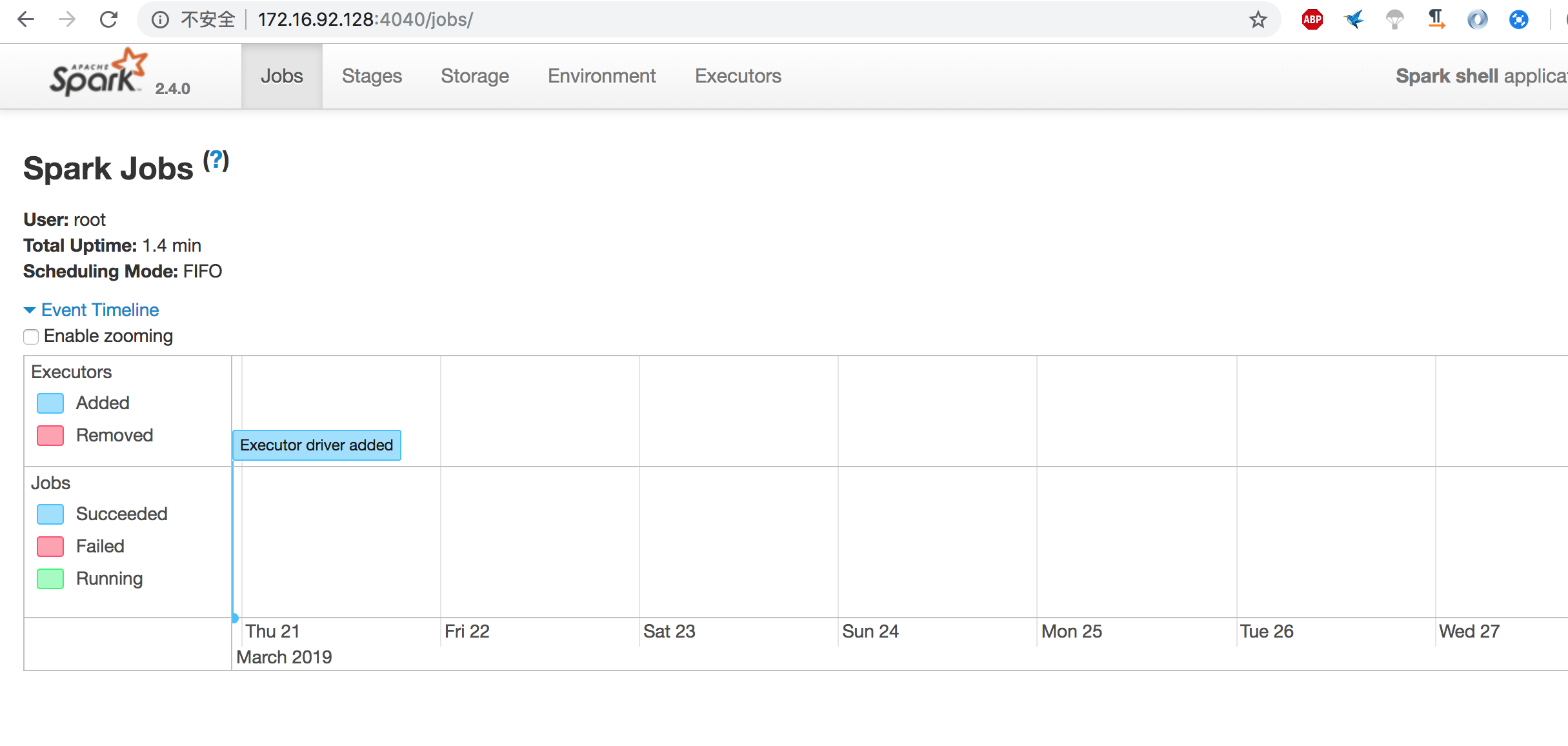
查看webui的jobs
http://172.16.92.128:4040/jobs/
pyspark,scall的是spark-shell
[root@sjck-node01 bin]# pyspark
Python 2.7.4 (default, Mar 21 2019, 00:09:49)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-23)] on linux2
2019-03-21 20:53:11 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Python version 2.7.4 (default, Mar 21 2019 00:09:49)
SparkSession available as 'spark'.
>>>
上传文件本地文件至HDFS
[root@sjck-node01 data]# hadoop fs -put /data/READ.md
[root@sjck-node01 data]# hadoop fs -ls
Found 1 items
-rw-r--r-- 2 root supergroup 3952 2019-03-23 21:07 READ.md
虚拟机spark集群搭建的更多相关文章
- Spark集群搭建简配+它到底有多快?【单挑纯C/CPP/HADOOP】
最近耳闻Spark风生水起,这两天利用休息时间研究了一下,果然还是给人不少惊喜.可惜,笔者不善JAVA,只有PYTHON和SCALA接口.花了不少时间从零开始认识PYTHON和SCALA,不少时间答了 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- spark集群搭建
文中的所有操作都是在之前的文章scala的安装及使用文章基础上建立的,重复操作已经简写: 配置中使用了master01.slave01.slave02.slave03: 一.虚拟机中操作(启动网卡)s ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- Spark集群搭建简要
Spark集群搭建 1 Spark编译 1.1 下载源代码 git clone git://github.com/apache/spark.git -b branch-1.6 1.2 修改pom文件 ...
- Spark集群搭建_Standalone
2017年3月1日, 星期三 Spark集群搭建_Standalone Driver: node1 Worker: node2 Worker: node3 1.下载安装 下载地址 ...
- Spark集群搭建_YARN
2017年3月1日, 星期三 Spark集群搭建_YARN 前提:参考Spark集群搭建_Standalone 1.修改spark中conf中的spark-env.sh 2.Spark on ...
- Spark 集群搭建
0. 说明 Spark 集群搭建 [集群规划] 服务器主机名 ip 节点配置 s101 192.168.23.101 Master s102 192.168.23.102 Worker s103 19 ...
随机推荐
- [转载]HTML5开发入门经典教程和案例合集(含视频教程)
http://www.iteye.com/topic/1132555 HTML5作为下一代网页语言,对Web开发者而言,是一门必修课.本文档收集了多个HTML5经典技术文档(HTML5入门资料.经典) ...
- 【CodeForces】914 F. Substrings in a String bitset
[题目]F. Substrings in a String [题意]给定小写字母字符串s,支持两种操作:1.修改某个位置的字符,2.给定字符串y,查询区间[l,r]内出现y多少次.|s|,Σ|y|&l ...
- 20155310 2016-2017-2 《Java程序设计》第六周学习总结
20155310 2016-2017-2 <Java程序设计>第六周学习总结 教材学习内容总结 4.1 Y86指令集体系结构 •有8个程序寄存器:%eax.%ecx.%edx.%ebx.% ...
- HDU 1259 ZJUTACM
解题报告:就用了一个swap函数就行了. #include<cstdio> #include<iostream> int main() { int x,y,T,n; scanf ...
- Python time()方法
from:http://www.runoob.com/python/att-time-time.html 描述 Python time time() 返回当前时间的时间戳(1970纪元后经过的浮点秒数 ...
- asp.net 获取音视频时长 的方法
http://www.evernote.com/l/AHPMEDnEd65A7ot_DbEP4C47QsPDYLhYdYg/ 日志: 1.第一种方法: 调用:shell32.dll ,win7 ...
- java 一个函数如何返回多个值
在开发过程中,经常会有这种情况,就是一个函数需要返回多个值,这是一个问题!! 网上这个问题的解决方法: 1.使用map返回值:这个方法问题是,你并不知道如何返回值的key是什么,只能通过doc或者通过 ...
- 手淘移动适配方案flexible.js兼容bug处理
什么是flexible.js 移动端自适应方案 https://www.jianshu.com/p/04efb4a1d2f8 什么是rem 这个单位代表根元素的 font-size 大小(例如 元素的 ...
- git —— 基本命令以及操作(No.1)
git基本命令(附加描述) 1.把文件添加到暂存区$ git add readme.txt 2.把暂存区的文件文件添加到仓库$ git commit -m "提交说明" 备注:ad ...
- No.4 selenium学习之路之iframe
查看iframe: 1.top window ——可以直接进行定位