pandas:由列层次化索引延伸的一些思考
1. 删除列层次化索引
用pandas利用df.groupby.agg() 做聚合运算时遇到一个问题:产生了列方向上的两级索引,且需要删除一级索引。具体代码如下:
# 每个uesr每天消费金额统计:和、均值、最大值、最小值、消费次数、消费种类、
action_info = student_action.groupby(['outid','date']).agg({'opfare':['sum','mean','max','min'],
'acccode':['count','unique'],}).reset_index()
action_info 表结果如下:

删除列的层次化索引操作如下:
# 列的层次化索引的删除
levels = action_info.columns.levels
labels = action_info.columns.labels
print(levels,labels)
action_info.columns = levels[1][labels[1]]
2. agg()与apply()的区别
以 student_action表为例:
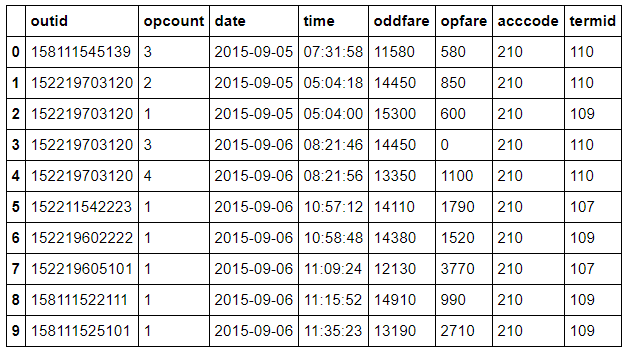
apply()方法:
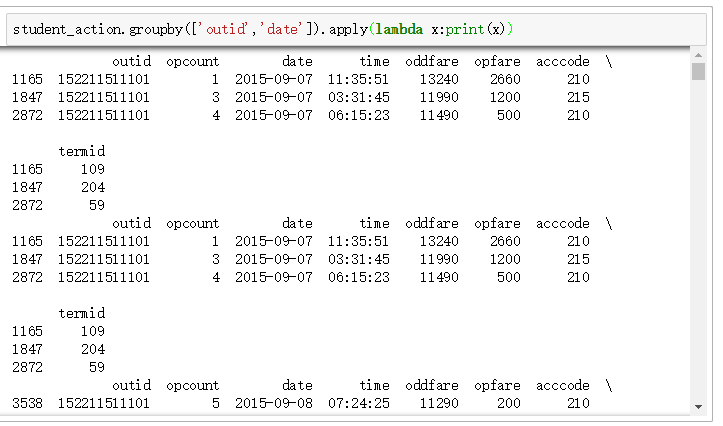
agg()方法:
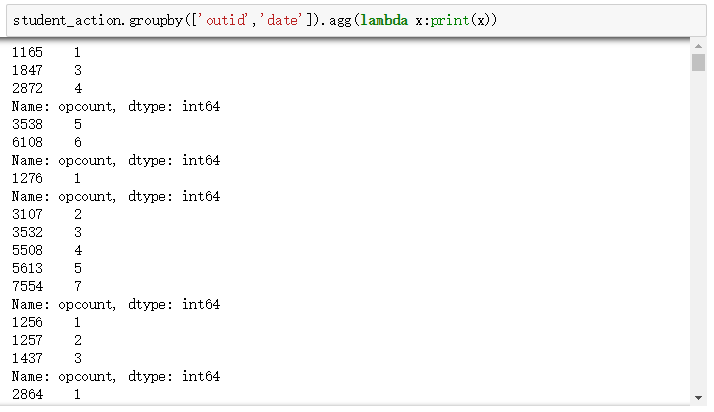
可以看到,apply()可以展示所有维度的数据,而agg()仅可以展示一个维度的数据。
事实上,如果值是一维数组,在利用完特定的函数之后,能做到简化的话,agg就能调用,反之,如果比如自定义的函数是排序,或者是一些些更复杂统计的函数,当然是agg所不能解决的,这时候用apply就可以解决。因为他更一般化,不存在什么简化,什么一维数组,什么标量值。且apply会将当前分组后的数据一起传入,可以返回多维数据。
例子:根据 student_action表,统计每个学生每天最高使用次数的终端、最低使用次数的终端以及最高使用次数终端的使用次数、最低使用次数终端的使用次数。
针对这个例子,有两种方法:
方法一:low到爆 永不使用!!
1. 构造每个用户每天的终端列表,需要one-hot termid
2. 构造groupby.agg()所使用的方法
2.1 列表模糊查找,找到包含'termid_'的字段名
termid_features = [x for i,x in enumerate(student_termid_onehot.columns.tolist()) if x.find('termid_')!=-1]
2.2 构造指定长度,指定元素的列表
sum_methods= ['sum'for x in range(0, len(termid_features))]
2.3 agg_methods=dict(zip(termid_features,sum_methods))
3. 每个学生每天的终端使用次数明细表
find_termid_df = student_termid_onehot.groupby(['outid','date']).agg(agg_methods).reset_index()
4. 找到student_termid_onehot中包含 'termid_'字段元素的最大值对应的字段名
4.1 构造列表保存
4.2 遍历每行数据,构造dict,并过滤value =0.0 的 k-v
4.3 找到每个dict的value值最大的key
max(filtered_statics_dict, key=filtered_statics_dict.get)
方法二:优雅直观
def transmethod(df):
"""
每个用户每天消费记录最大值、最高使用次数的终端、最低使用次数的终端
以及最高使用次数终端的使用次数、最低使用次数终端的使用次数。 df type:
outid opcount date time oddfare opfare acccode \
3538 152211511101 5 2015-09-08 07:24:25 11290 200 210
6108 152211511101 6 2015-09-08 12:09:01 10440 850 210 termid
3538 13
6108 39 """
# 每日最大消费额
maxop = df['opfare'].max()
statics_dict={}
for i in set(df['acccode'].tolist()):
statics_dict[i] = df['acccode'].tolist().count(i)
highest_termid = max(statics_dict, key=statics_dict.get)
lowhest_termid = min(statics_dict, key=statics_dict.get)
highest_termid_freq = statics_dict[highest_termid]
lowhest_termid_freq = statics_dict[lowhest_termid] return maxop,highest_termid,highest_termid_freq,lowhest_termid,lowhest_termid_freq
groupby.apply() 组合使用:
pd.DataFrame(student_action.groupby(['outid','date']).apply(lambda x:transmethod(x)))
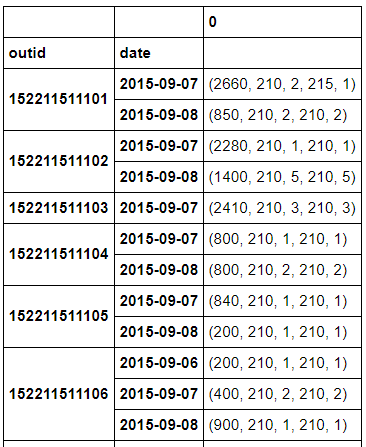
可以发现,apply()方法要比agg()方法灵活的多的多!
3. 总结
- 列层次索引的删除
- 列表的模糊查找方式
- 查找dict的value值最大的key 的方式
- 当做简单的聚合操作(max,min,unique等),可以使用agg(),在做复杂的聚合操作时,一定使用apply()
pandas:由列层次化索引延伸的一些思考的更多相关文章
- Pandas基本功能之层次化索引及层次化汇总
层次化索引 层次化也就是在一个轴上拥有多个索引级别 Series的层次化索引 data=Series(np.random.randn(10),index=[ ['a','a','a','b','b', ...
- pandas(五)处理缺失数据和层次化索引
pandas用浮点值Nan表示浮点和非浮点数组中的缺失数据.它只是一个便于被检测的标记而已. >>> string_data = Series(['aardvark','artich ...
- pandas中层次化索引与切片
Pandas层次化索引 1. 创建多层索引 隐式索引: 常见的方式是给dataframe构造函数的index参数传递两个或是多个数组 Series也可以创建多层索引 Series多层索引 B =Ser ...
- (三)pandas 层次化索引
pandas层次化索引 1. 创建多层行索引 1) 隐式构造 最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组 Series也可以创建多层索引 import numpy ...
- 利用Python进行数据分析(11) pandas基础: 层次化索引
层次化索引 层次化索引指你能在一个数组上拥有多个索引,例如: 有点像Excel里的合并单元格对么? 根据索引选择数据子集 以外层索引的方式选择数据子集: 以内层索引的方式选择数据: 多重索引S ...
- pandas学习(创建多层索引、数据重塑与轴向旋转)
pandas学习(创建多层索引.数据重塑与轴向旋转) 目录 创建多层索引 数据重塑与轴向旋转 创建多层索引 隐式构造 Series 最常见的方法是给DataFrame构造函数的index参数传递两个或 ...
- 利用Python进行数据分析_Pandas_层次化索引
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 层次化索引主要解决低纬度形式处理高纬度数据的问题 import pandas ...
- SQL Server 2014聚集列存储索引
转发请注明引用和原文博客(http://www.cnblogs.com/wenBlog) 简介 之前已经写过两篇介绍列存储索引的文章,但是只有非聚集列存储索引,今天再来简单介绍一下聚集的列存储索引,也 ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
随机推荐
- 初学Linux(一)关闭操作shutdown halt reboot
1.shutdown –h 10 #这个命令告诉大家,计算机将在10分钟后关机,并且会显示在登陆用户的当前屏幕中. 2.Shutdown –h now #立马关机 3.Shutdown –h 11:1 ...
- Entity Framework的基本操作
一.使用基本的方法进行增删改查 二.使用状态进行增删改查,即使用基类对象进行操作 三.多个表同时进行添加 添加数据后获取自动增长 ...
- docker 自制alpine-lnp镜像
简单粗暴点吧 jenkins 镜像下载:docker pull jenkins:alpine dockfile 原地址:https://gist.github.com/phith0n/373cc078 ...
- 超强IIS站点工具一键设置PHP,支持多个PHP同时运行
PHPWAMP8.8.8.8IN支持三大主流Web服务器:iis.apache.nginx NGINX站点管理.IIS站点管理.Apache站点管理均支持php多版本同时运行,无限自定义mysql.p ...
- JS代码高亮编辑器 ace.js
JS代码高亮编辑器 ace.js 字数254 阅读2 评论0 喜欢0 瞎扯 ace 是 js 实现的代码编辑器 编译打包之后的 ACE 代码 官网,未提供编译好的文件 ACE 拥有的特点 语法高亮超过 ...
- Alpha 冲刺报告(6/10)
Alpha 冲刺报告(6/10) 队名:洛基小队 峻雄(组长) 已完成:实现角色的移动. 明日计划:关于角色的属性设计. 剩余任务:角色的属性脚本 困难:角色的属性以及具体的编码 ---------- ...
- JDBC规范(转)
公司开发一直用的是ibatis,进来心血来潮想研究一下源码,可是发现自己的JDBC似乎已经忘得差不多了,为了自己能顺利的研读ibatis的源码,于是乎找到了 XIAO_DF的JDBC规范的博客,转到自 ...
- Angular总结二:Angular 启动过程
要弄清楚 Angular 的启动过程,就要弄明白 Angular 启动时加载了哪个页面,加载了哪些脚本,这些脚本做了哪些事? 通过 Angular 的编译依赖文件 .angular-cli.json ...
- python第一课——关于python的一些概念
day01(上午): 1.学习方法(建议): 1).不要依赖于我的视频,绝对不要晚上将视频全部在过一遍 2).上课不要记笔记,而且不要用纸质的笔记本去整理笔记 3).不要只看不敲,代码方面我们需要做到 ...
- 1925: [Sdoi2010]地精部落
1925: [Sdoi2010]地精部落 Time Limit: 10 Sec Memory Limit: 64 MB Submit: 1929 Solved: 1227 [Submit][Statu ...