Python 10min系列之面试题解析丨Python实现tail -f功能

关于这道题,简单说一下我的想法吧。当然,也有很好用的 pyinotify 模块专门监听文件变化,不过我更想介绍的,是解决的思路。
毕竟作为面试官,还是想看到一下解决问题的思路,而且我觉得这一题的难点不在于监控文件增量,而在于怎么打印最后面10行。
希望大家在读这篇文章前,对 Python 基础、处理文件和常用模块有一个简单的了解,知道下面几个名词是什么:

下面的思路仅限于我个人知识和见解,免不了有错误和考虑不周的地方。希望大家有更好的方法能够提出来,我会随时优化代码。
怎么用 Python 实现
其实思路也不算难啦
1.打开这个文件,指针移到最后
2.每隔一秒就尝试readline一下,有内容就打印出来,没内容就sleep
监听文件
思路如下:
1.用open打开文件
2.用seek文件指针,给大爷把跳到文件最后面
3.while True进行循环
持续不停的readline,如果能读到内容,打印出来即可
代码呼之欲出
with open('test.txt') as f:
f.seek(0,2)
while True:
last_pos = f.tell()
line = f.readline()
if line:
print line
代码说明:
1. seek第二个参数2,意思就是从文件结尾处开始seek,更标准的写法使用os模块下面的SEEK_END,可读性更好
2.只写出了简单的逻辑,代码简单粗暴,如果这个题目是10分的话,最多也就拿4分吧,不能再多了
优化点:
1.print有缺陷,每次都是新的一行,换成sys.stdout.write(line)更和谐
2.文件名传参,不能写死
3.直接打印可以当成默认行为,具体要做什么,可以写成函数处理,这样我们就可以把新行做其他处理,比如展示在浏览器里
4.加上容错处理,比如文件不存在会报错
5.while True一直都文件,比较耗性能,每读一次,间隔一秒比较靠谱
调用time.sleep(1)
6.用类来组织代码
实例代码如下:
# coding=utf-8
import sys
import time
class Tail():
def __init__(self,file_name,callback=sys.stdout.write):
self.file_name = file_name
self.callback = callback
def follow(self):
try:
with open(self.file_name) as f:
f.seek(0,2)
while True:
line = f.readline()
if line:
self.callback(line)
time.sleep(1)
except Exception,e:
print '打开文件失败,囧,看看文件是不是不存在,或者权限有问题'
print e
使用方法:
# 使用默认的sys.stdout.write打印到屏幕
py_tail = Tail('test.txt')
py_tail.follow()
# 自己定义处理函数
def test_tail(line):
print 'xx'+line+'xx'
py_tail1 = Tail('test.txt', test_tail)
py_tail1.follow()
咦 ,等等!tail -f 默认还会打印最后10行,这个好像才是这个题目的难点所在。众所周知,Python 里读文件指针,只能移动到固定位置,不能判断是哪一行。那就先实现简单的,然后逐渐加强吧。
默认打印最后十行
现在这个代码,大概能拿6分啦,我们还有一个功能没做,那就是打印最后n行,默认是10行,现在把这个功能加上,加一个函数就行啦。
文件小的时候
我们知道,readlines可以获取所有内容,并且分行,代码呼之欲出,获取list最后10行很简单有么有,切片妥妥的。
# 演示代码,说明核心逻辑,完整代码在下面
last_lines = f.readlines()[-10:]
for line in last_lines:
self.callback(line)
此时代码就变成这样了:
import sys
import time
class Tail():
def __init__(self,file_name,callback=sys.stdout.write):
self.file_name = file_name
self.callback = callback
def follow(self,n=10):
try:
with open(self.file_name) as f:
self._file = f
self.showLastLine(n)
self._file.seek(0,2)
while True:
line = self._file.readline()
if line:
self.callback(line)
except Exception,e:
print '打开文件失败,囧,看看文件是不是不存在,或者权限有问题'
print e
def showLastLine(self, n):
last_lines = self._file.readlines()[-10:]
for line in last_lines:
self.callback(line)
更进一步:大的日志怎么办
但是如果文件特别大呢,特别是日志文件,很容易就是几个G。我们只需要最后几行,全部读出来内存受不了,所以我们要继续优化showLastLine 函数,我觉得这才是这题的难点所在。
大概的思路如下:
1.我先估计日志一行大概是100个字符,注意,我只是估计一个大概,多了也没关系,我们只是需要一个初始值,后面会修正
2.我要读十行,所以一开始就 see k到离结尾1000的位置seek(-1000,2),把最后1000个字符读出来,然后有一个判断
3.如果这1000个字符长度大于文件长度,不用管了 属于级别1的情况,直接read然后split
4.如果1000个字符里面的换行符大于10,说明1000个字符里,大于10行,那也好办,处理思路类似级别1,直接split取后面十个
5.问题就在于 如果小于10怎么处理
比如1000个里,只有四个换行符,说明一行大概是1000/4=250个字符,我们还缺6行,所以我们再读250*5=1500,一共有2500的大概比较靠谱,然后在对2500个字符进行相同的逻辑判断,直到读出的字符里,换行符大于10,读取结束
逻辑清晰以后,代码就呼之欲出啦
# coding=utf-8
import sys
import time
class Tail():
def __init__(self,file_name,callback=sys.stdout.write):
self.file_name = file_name
self.callback = callback
def follow(self,n=10):
try:
with open(self.file_name) as f:
self._file = f
self._file.seek(0,2)
self.file_length = self._file.tell()
self.showLastLine(n)
while True:
line = self._file.readline()
if line:
self.callback(line)
time.sleep(1)
except Exception,e:
print '打开文件失败,囧,看看文件是不是不存在,或者权限有问题'
print e
def showLastLine(self, n):
len_line = 100
read_len = len_line*n
while True:
if read_len>self.file_length:
self._file.seek(0)
last_lines = self._file.read().split('\n')[-n:] break
self._file.seek(-read_len, 2)
last_words = self._file.read(read_len)
count = last_words.count('\n')
if count>=n:
last_lines = last_words.split('\n')[-n:] break
else:
if count==0:
len_perline = read_len
else:
len_perline = read_len/count
read_len = len_perline * n
for line in last_lines:
self.callback(line+'\n')
if __name__ == '__main__':
py_tail = Tail('test.txt')
py_tail.follow()
加上注释的版本:
# coding=utf-8
import sys
import time
class Tail():
def __init__(self,file_name,callback=sys.stdout.write):
self.file_name = file_name
self.callback = callback
def follow(self,n=10):
try:
# 打开文件
with open(self.file_name) as f:
self._file = f
self._file.seek(0,2)
# 存储文件的字符长度
self.file_length = self._file.tell()
# 打印最后10行
self.showLastLine(n)
# 持续读文件 打印增量
while True:
line = self._file.readline()
if line:
self.callback(line)
time.sleep(1)
except Exception,e:
print '打开文件失败,囧,看看文件是不是不存在,或者权限有问题'
print e
def showLastLine(self, n):
# 一行大概100个吧 这个数改成1或者1000都行
len_line = 100
# n默认是10,也可以follow的参数传进来
read_len = len_line*n
# 用last_lines存储最后要处理的内容
while True:
# 如果要读取的1000个字符,大于之前存储的文件长度
# 读完文件,直接break
if read_len>self.file_length:
self._file.seek(0)
last_lines = self._file.read().split('\n')[-n:] break
# 先读1000个 然后判断1000个字符里换行符的数量
self._file.seek(-read_len, 2)
last_words = self._file.read(read_len)
# count是换行符的数量
count = last_words.count('\n')
if count>=n:
# 换行符数量大于10 很好处理,直接读取
last_lines = last_words.split('\n')[-n:] break
# 换行符不够10个
else:
# break
#不够十行
# 如果一个换行符也没有,那么我们就认为一行大概是100个
if count==0:
len_perline = read_len
# 如果有4个换行符,我们认为每行大概有250个字符
else:
len_perline = read_len/count
# 要读取的长度变为2500,继续重新判断
read_len = len_perline * n
for line in last_lines:
self.callback(line+'\n')
if __name__ == '__main__':
py_tail = Tail('test.txt')
py_tail.follow(20)
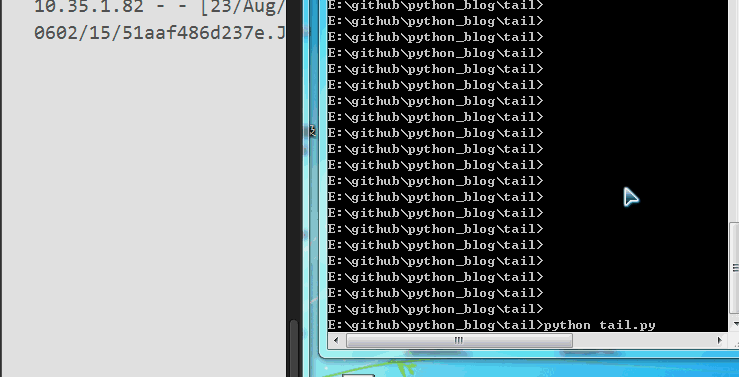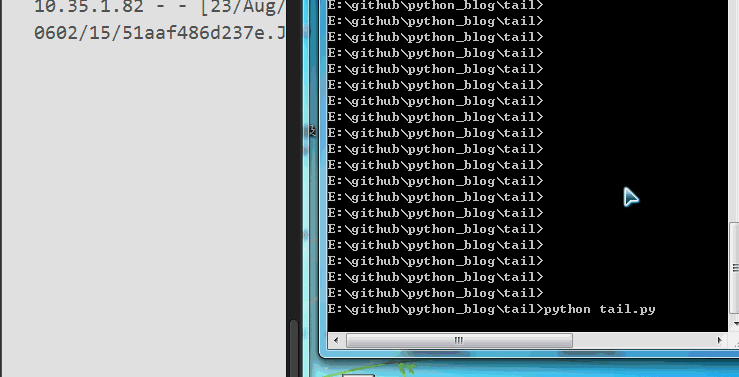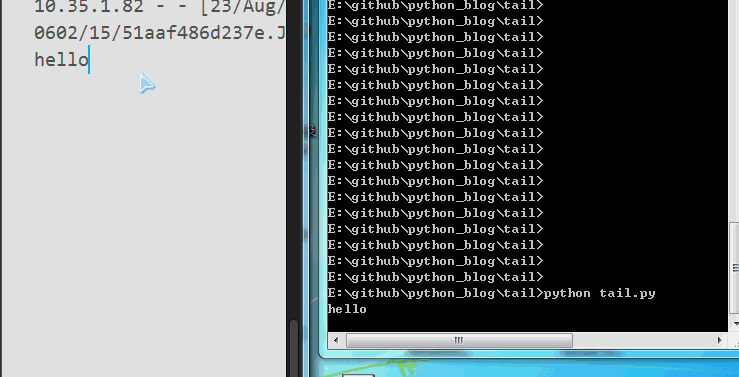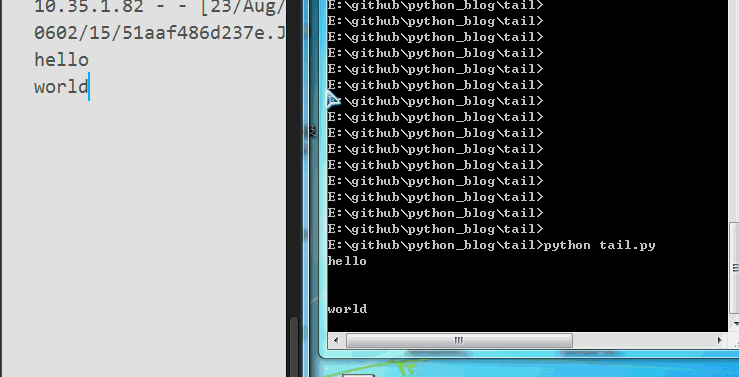
效果如下,终于可以打印最后几行了,大家可以试一下,无论日志每行只有1个,还是每行有300个字符,都是可以打印最后10行的。
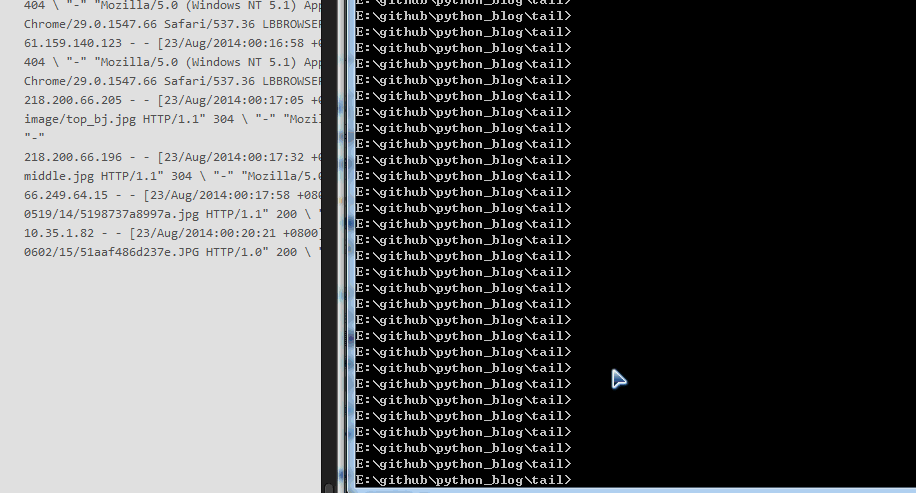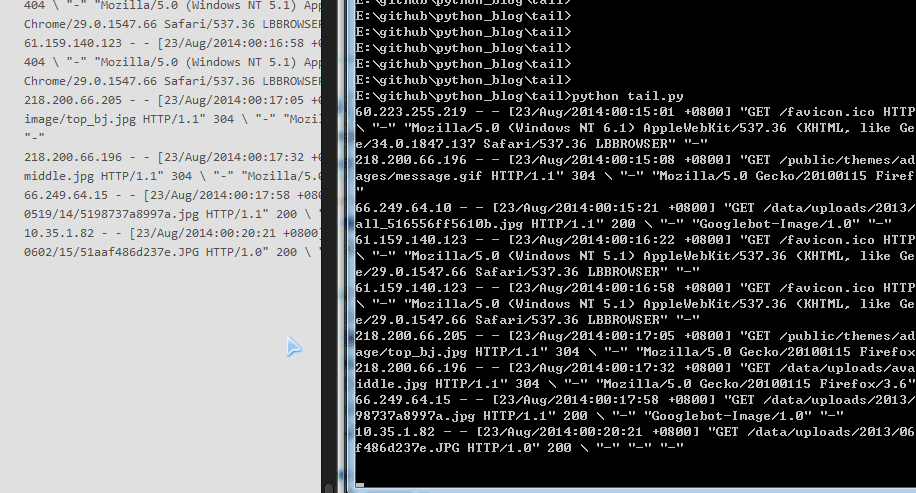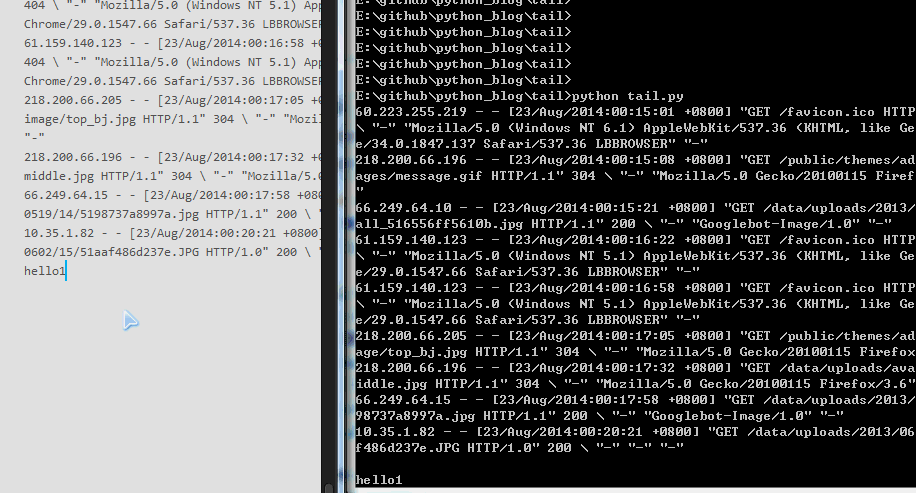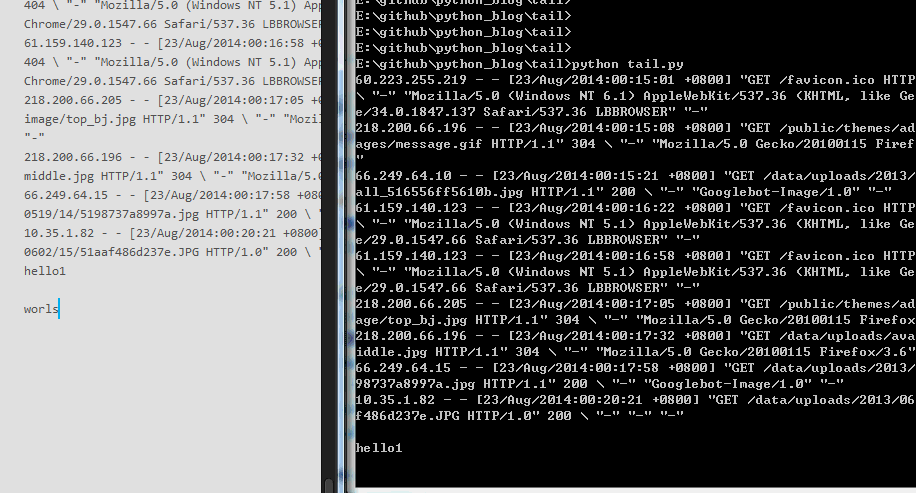
能做到这个地步,一般的面试官就直接被你搞定了,这个代码大概8分吧,如果还想再进一步,还有一些可以优化的地方,代码放 github 上了,有兴趣的可以拿去研究。
(Github 地址:https://github.com/shengxinjing/pytail/blob/master/tail.py)
待优化:留给大家作为扩展
1.如果你tail -f的过程中,日志被备份清空或者切割了,怎么处理
其实很简单,你维护一个指针位置,如果下次循环发现文件指针位置变了,从最新的指针位置开始读就行
2.具体每种错误的类型
我这里只是简单的try 可以写个函数,把文件不存在,文件没权限这些报错信息分开
3.性能小优化,比如我第一次读了1000,只有4行,我大概估计每行250个字符,总体需要2500行,下次没必要直接读2500个,而是读1500行和之前1000行拼起来即可
最后大杀器
如果写出来这个,基本面试官会直接……
import os
def tail(file_name):
os.system('tail -f '+file_name)
tail('log.log')
打死你!!!

以上就是我对这个题的想法,实际开发中想监控文件变化,其实还是pyinotify 好用。
Python 学习交流:238757010
Python 10min系列之面试题解析丨Python实现tail -f功能的更多相关文章
- python10min系列之面试题解析:python实现tail -f功能
同步发布在github上,跪求star 这篇文章最初是因为reboot的群里,有人去面试,笔试题有这个题,不知道怎么做,什么思路,就发群里大家讨论 我想了一下,简单说一下我的想法吧,当然,也有很好用的 ...
- Python fullstack系列【1】:初识Python
Python简介 Python的前世今生: Python诞生于1989年的圣诞节期间,其作者是吉多·范罗苏姆(Guido van Rossum).当时Guido(江湖人称龟叔)在阿姆斯特丹度假时着手开 ...
- python实现tail -f 功能
这篇文章最初是因为reboot的群里,有人去面试,笔试题有这个题,不知道怎么做,什么思路,就发群里大家讨论 我想了一下,简单说一下我的想法吧,当然,也有很好用的pyinotify模块专门监听文件变化, ...
- python实现tail -f功能
这篇文章最初是因为reboot的群里,有人去面试,笔试题有这个题,不知道怎么做,什么思路,就发群里大家讨论 我想了一下,简单说一下我的想法吧,当然,也有很好用的pyinotify模块专门监听文件变化, ...
- 扩展Python模块系列(三)----参数解析与结果封装
在上一节中,通过一个简单的例子介绍了C语言扩展Python内建模块的整体流程,从本节开始讲开始深入讨论一些细节问题,在细节讨论中从始至终都会涉及[引用计数]的问题.首先讨论C语言封装的Python函数 ...
- python面试题解析(python基础篇80题)
1. 答:出于编程的喜爱,以及行业本身的前瞻性,创造性,优越性,越是综合的科目越能检验一个人的能力,喜欢这种有挑战的事情. 2. 答:跟随老师学习,以及自己查询资料,结合实战,进行输入输出以及 ...
- python 10min系列之实现增删改查系统
woniu-cmdb 奇技淫巧--写配置文件生成增删改查系统 视频教程 项目主页跪求github给个star, 线上demo,此页面都是一个配置文件自动生成的 详细的文章介绍和实现原理分析会发布在我的 ...
- Python学习系列之(一)---Python的安装
Python几乎可以在任何平台下运行,如我们所熟悉的:Windows/Unix/Linux/Macintosh. 在这里我们说一下,在Windows操作系统中安装python. 我的操作系统为:Win ...
- Python学习系列(六)(模块)
Python学习系列(六)(模块) Python学习系列(五)(文件操作及其字典) 一,模块的基本介绍 1,import引入其他标准模块 标准库:Python标准安装包里的模块. 引入模块的几种方式: ...
随机推荐
- September 20th 2017 Week 38th Wednesday
All our dreams can come true if we have the courage to pursue them. 如果我们有勇气去追求梦想,我们的梦想一定可以成为现实. If y ...
- VRSProcess(一)
1.freopen( "CONOUT$","w",stdout);在操作系统中,命令行控制台(即键盘或者显示器)被视为一个文件,既然是文件,那么就有“文件名”. ...
- #003 React 组件 继承 自定义的组件
主题:React组件 继承 自定义的 组件 一.需求说明 情况说明: 有A,B,C,D 四个组件,里面都有一些公用的逻辑,比如 设置数据,获取数据,有某些公用的的属性,不想在 每一个 组件里面写这些属 ...
- 前端统计利器:Sentry & Matomo
今天主要说下两款前端统计工具的使用,Sentry & Matomo.以下主要是统计代码接入方式,因此使用前提是你已经在自己的服务器上搭建好了Sentry和Matomo的服务器 Sentry统计 ...
- [转]IE9.0或者360下js(JavaScript、jQuery)不能正确执行(加载),按F12后执行正常;Firefox下ajax的success返回数据data(json、string)无法获取
兼容问题1: 页面的分享等插件加载不全,并无法点击. 兼容问题2: IE下页面选择器(#id..class.etc.)绑定click事件无法访问到,后台springmvc方法,也无法获取ajax的su ...
- Python 3 与 Javascript escape 传输确保数据正确方法和中文乱码解决方案
注意:现在已不推荐 escape 函数,推荐使用 encodeURIComponent 函数,其中方法更简单,只需进行URL解码即可. 当然了,如下文章解决方案一样可行. 前几天用Python的Bo ...
- 1305. [CQOI2009]跳舞【最大流+二分】
Description 一次舞会有n个男孩和n个女孩.每首曲子开始时,所有男孩和女孩恰好配成n对跳交谊舞.每个男孩都不会和同一个女孩跳两首(或更多)舞曲.有一些男孩女孩相互喜欢,而其他相互不喜欢(不会 ...
- virtualbox+vagrant学习-2(command cli)-17-vagrant ssh命令
SSH 格式: vagrant ssh [options] [name|id] [-- extra ssh args] 这将SSH导入正在运行的vagrant机器,并允许你访问机器的shell. us ...
- c++版 nms
目前这个代码运行会报一些错误,还要再修改修改才行 #include<iostream> #include<vector> #include<algorithm> # ...
- STM32F103 ucLinux内核没有完全启动
STM32F103 ucLinux内核没有完全启动 从BOOT跳转到内核后,执行一长段的汇编语言,然后来到startkernel函数,开启C语言之旅. 但是内核输出不正常,如下所示: Linux ve ...