使用Cloudera Manager搭建Hive服务
使用Cloudera Manager搭建Hive服务
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.安装Hive环境
1>.进入CM服务安装向导

2>.选择需要安装的hive服务

3>.选择hive的依赖环境,我们选择第一个即可(hive不仅仅可以使用mr计算,还可以使用tez计算哟~) 
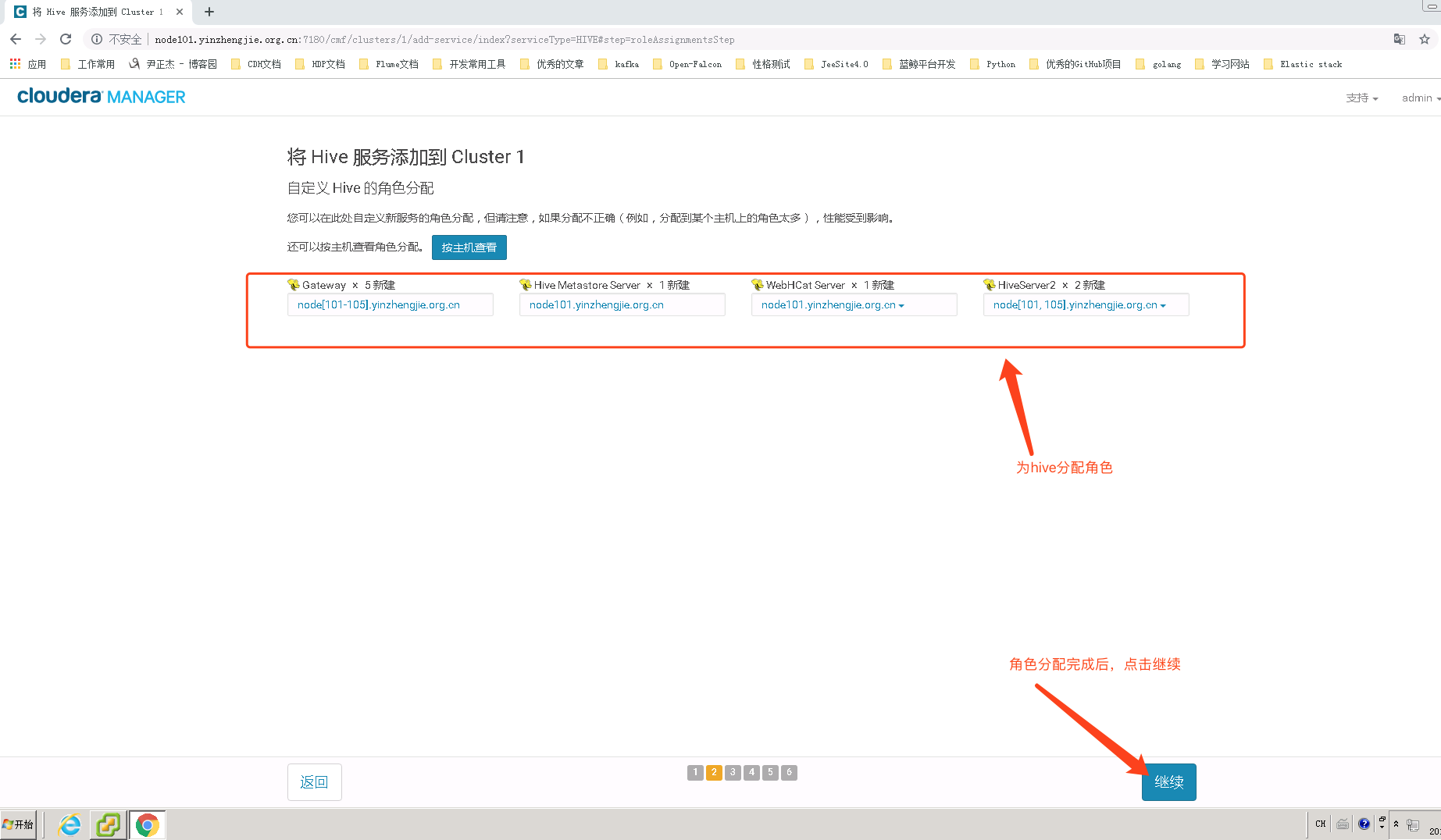
4>.为Hive分配角色
Hive Metastore是管理和存储元信息的服务,它保存了数据库的基本信息以及数据表的定义等,为了能够可靠地保存这些元信息,Hive Metastore一般将它们持久化到关系型数据库中,默认采用了嵌入式数据库Derby(数据存放在内存中),用户可以根据需要启用其他数据库,比如MySQL。
推荐阅读:https://www.cnblogs.com/yinzhengjie/p/10836132.html
Hive Metastore 简介戳我
HCatalog是Hadoop中的表和存储管理层,能够支持用户用不同的工具(Pig、MapReduce)更容易地表格化读写数据。
HCatalog从Apache孵化器毕业,并于2013年3月26日与Hive项目合并。
Hive版本0..0是包含HCatalog的第一个版本。(随Hive一起安装),CDH 5.15.1默认使用的是Hive版本为:1.1.+cdh5.15.1+,即Apache Hive 1.1.0版本。
HCatalog的表抽象向用户提供了Hadoop分布式文件系统(HDFS)中数据的关系视图,并确保用户不必担心数据存储在哪里或以什么格式存储 - RCFile格式,文本文件,SequenceFiles或ORC文件。
HCatalog支持读写任意格式的SerDe(序列化 - 反序列化)文件。默认情况下,HCatalog支持RCFile,CSV,JSON和SequenceFile以及ORC文件格式。要使用自定义格式,您必须提供InputFormat,OutputFormat和SerDe。
HCatalog构建于Hive metastore,并包含Hive的DDL。HCatalog为Pig和MapReduce提供读写接口,并使用Hive的命令行界面发布数据定义和元数据探索命令。
HCatalog 简介戳我
HiveServer2(HS2)是一个服务端接口,使远程客户端可以执行对Hive的查询并返回结果。目前基于Thrift RPC的实现是HiveServer的改进版本,并支持多客户端并发和身份验证
启动hiveServer2服务后,就可以使用jdbc,odbc,或者thrift的方式连接。 用java编码jdbc或则beeline连接使用jdbc的方式,据说hue是用thrift的方式连接的hive服务。
HiveServer2 简介戳我
5>.hive的数据库设置(存储元数据metastore的数据库)
mysql> CREATE DATABASE hive CHARACTER SET = utf8;
Query OK, row affected (0.00 sec) mysql>
mysql> GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%' IDENTIFIED BY 'yinzhengjie' WITH GRANT OPTION;
Query OK, rows affected (0.07 sec) mysql>
mysql> FLUSH PRIVILEGES;
Query OK, rows affected (0.02 sec) mysql> quit
Bye
[root@node101.yinzhengjie.org.cn ~]#
MySQL授权hive用户的准备工作

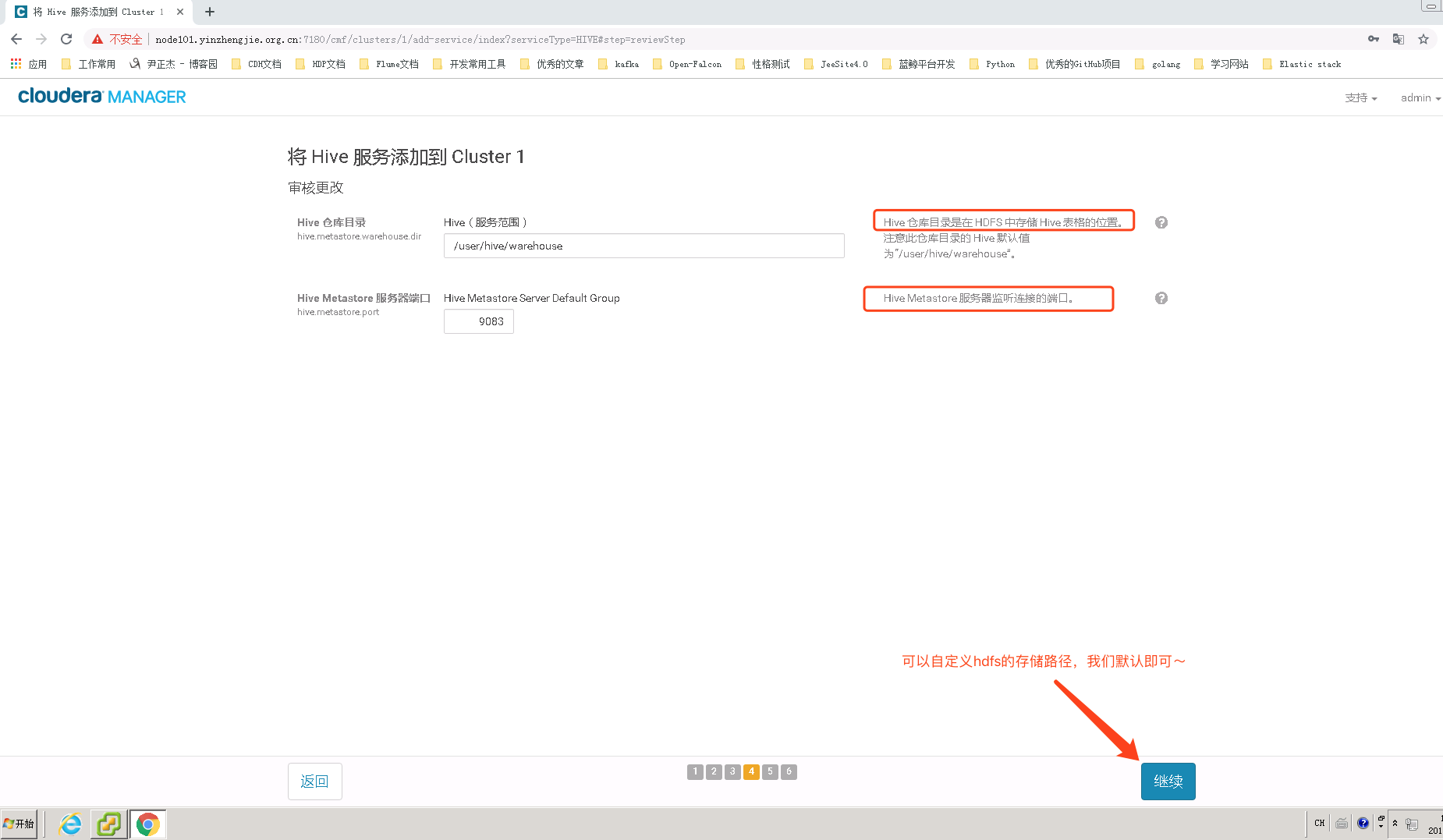
6>.修改hive在hdfs的数据仓库存放位置
7>.等待Hive服务部署完成

mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| cdh |
| hive |
| mysql |
| performance_schema |
+--------------------+
rows in set (0.00 sec) mysql> use hive
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A Database changed
mysql>
mysql> show tables;
+---------------------------+
| Tables_in_hive |
+---------------------------+
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_TXN_COMPONENTS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| IDXS |
| INDEX_PARAMS |
| MASTER_KEYS |
| METASTORE_DB_PROPERTIES |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_TXN_ID |
| NOTIFICATION_LOG |
| NOTIFICATION_SEQUENCE |
| NUCLEUS_TABLES |
| PARTITIONS |
| PARTITION_EVENTS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_PRIVS |
| PART_COL_STATS |
| PART_PRIVS |
| ROLES |
| ROLE_MAP |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| TBL_COL_PRIVS |
| TBL_PRIVS |
| TXNS |
| TXN_COMPONENTS |
| TYPES |
| TYPE_FIELDS |
| VERSION |
+---------------------------+
rows in set (0.00 sec) mysql>
配置完成后,我们观察hive数据库中是存放元数据信息相关表的(说实话,初始化表挺多的,我这里现实有54张表,为随机抽取记账本看了下,都是空表~)
8>.Hive服务添加成功

9>.在CM界面中可以看到Hive服务是运行正常的

二.测试Hive环境是否可用
1>.将测试数据上传到HDFS中
[root@node101.yinzhengjie.org.cn ~]# cat PageViewData.csv
// :,us,,www.yahoo.com/clq,www.yahoo.com/jxq,948.323.252.617
// :,de,,www.google.com/g4,www.google.com/uypu,416.358.537.539
// :,se,,www.google.com/f5,www.yahoo.com/soeos,564.746.582.215
// :,de,,www.google.com/h5,www.yahoo.com/agvne,685.631.592.264
// :,cn,,www.yinzhengjie.org.cn/g4,www.google.com/uypu,416.358.537.539
// :,us,,www.yahoo.com/clq,www.yahoo.com/jxq,948.323.252.617
// :,de,,www.google.com/g4,www.google.com/uypu,416.358.537.539
// :,se,,www.google.com/f5,www.yahoo.com/soeos,564.746.582.215
// :,de,,www.google.com/h5,www.yahoo.com/agvne,685.631.592.264
// :,de,,www.yinzhengjie.org.cn/g4,www.google.com/uypu,416.358.537.539
// :,us,,www.yahoo.com/clq,www.yahoo.com/jxq,948.323.252.617
// :,de,,www.google.com/g4,www.google.com/uypu,416.358.537.539
// :,se,,www.google.com/f5,www.yahoo.com/soeos,564.746.582.215
// :,de,,www.google.com/h5,www.yahoo.com/agvne,685.631.592.264
// :,de,,www.yinzhengjie.org.cn/g4,www.google.com/uypu,416.358.537.539
// :,us,,www.yahoo.com/clq,www.yahoo.com/jxq,948.323.252.617
// :,de,,www.google.com/g4,www.google.com/uypu,416.358.537.539
// :,se,,www.google.com/f5,www.yahoo.com/soeos,564.746.582.215
// :,de,,www.google.com/h5,www.yahoo.com/agvne,685.631.592.264
// :,de,,www.yinzhengjie.org.cn/g4,www.google.com/uypu,416.358.537.539
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# cat PageViewData.csv ##查看本地文件日志,为了测试我就随机写了条数据
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -ls /tmp/
Found items
d--------- - hdfs supergroup -- : /tmp/.cloudera_health_monitoring_canary_files
drwxr-xr-x - yarn supergroup -- : /tmp/hadoop-yarn
drwx-wx-wx - root supergroup -- : /tmp/hive
drwxrwxrwt - mapred hadoop -- : /tmp/logs
drwxr-xr-x - mapred supergroup -- : /tmp/mapred
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# ll
total
-rw-r--r-- root root May : PageViewData.csv
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -put PageViewData.csv /tmp/
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -ls /tmp/
Found items
d--------- - hdfs supergroup -- : /tmp/.cloudera_health_monitoring_canary_files
-rw-r--r-- root supergroup -- : /tmp/PageViewData.csv
drwxr-xr-x - yarn supergroup -- : /tmp/hadoop-yarn
drwx-wx-wx - root supergroup -- : /tmp/hive
drwxrwxrwt - mapred hadoop -- : /tmp/logs
drwxr-xr-x - mapred supergroup -- : /tmp/mapred
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]#
[root@node101.yinzhengjie.org.cn ~]# hdfs dfs -put PageViewData.csv /tmp/ #将数据上传到HDFS的/tmp目录中
2>.创建数据表page_view,以保证结构化用户访问日志
[root@node101.yinzhengjie.org.cn ~]# hive
Java HotSpot(TM) -Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Java HotSpot(TM) -Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0 Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-5.15.-.cdh5.15.1.p0./jars/hive-common-1.1.-cdh5.15.1.jar!/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> CREATE TABLE page_view(
> view_time String,
> country String,
> userid String,
> page_url String,
> referrer_url String,
> ip String)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED by '\n'
> STORED AS TEXTFILE;
OK
Time taken: 2.598 seconds
hive> show tables;
OK
page_view
Time taken: 0.166 seconds, Fetched: row(s)
hive>
创建Hive数据表时,需显式指定数据存储格式,在以上示例中,TEXTFILE表示文本文件,“,”表示每列分隔符为逗号,而“\n”表示分隔符。
3>.使用LOAD语句将HDFS上的指定目录或文件加载到数据表page_view中
hive> LOAD DATA INPATH "/tmp/PageViewData.csv" INTO TABLE page_view;
Loading data to table default.page_view
Table default.page_view stats: [numFiles=, totalSize=]
OK
Time taken: 0.594 seconds
hive>
4>.使用HQL查询数据。
hive> SELECT country,count(userid) FROM page_view WHERE view_time > "1990/01/12 10:12" GROUP BY country;
Query ID = root_20190523125656_e7558dc5-d450-4d17-bf81-209f802605de
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Starting Job = job_201905221917_0001, Tracking URL = http://node101.yinzhengjie.org.cn:50030/jobdetails.jsp?jobid=job_201905221917_0001
Kill Command = /opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop/bin/hadoop job -kill job_201905221917_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-05-23 12:56:45,895 Stage-1 map = 0%, reduce = 0%
2019-05-23 12:56:52,970 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.29 sec
2019-05-23 12:56:59,017 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.37 sec
MapReduce Total cumulative CPU time: 5 seconds 370 msec
Ended Job = job_201905221917_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.37 sec HDFS Read: 10553 HDFS Write: 21 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 370 msec
OK
cn 1
de 11
se 4
us 4
Time taken: 25.063 seconds, Fetched: 4 row(s)
hive>
hive> SELECT country,count(userid) FROM page_view WHERE view_time > "1990/01/12 10:12" GROUP BY country;
使用Cloudera Manager搭建Hive服务的更多相关文章
- 使用Cloudera Manager搭建Impala环境
使用Cloudera Manager搭建Impala服务 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用CM安装Imapala 1>.进入CM的服务安装向导 2> ...
- 使用Cloudera Manager添加Sentry服务
使用Cloudera Manager添加Sentry服务 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.通过CM添加Sentry服务 1>.点击添加服务进入CM服务安装向 ...
- 使用Cloudera Manager搭建Kudu环境
使用Cloudera Manager搭建Kudu环境 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 1>.点击添加服务进入CM服务安装向导 2>.选择需要安装的kudu ...
- 使用Cloudera Manager搭建HBase环境
使用Cloudera Manager搭建HBase环境 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用CM安装HBase服务 1>.进入CM服务安装向导 2>. ...
- 使用Cloudera Manager搭建MapReduce集群及MapReduce HA
使用Cloudera Manager搭建MapReduce集群及MapReduce HA 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.通过CM部署MapReduce On ...
- 使用Cloudera Manager搭建YARN集群及YARN HA
使用Cloudera Manager搭建YARN集群及YARN HA 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用Cloudera Manager搭建YARN集群 1& ...
- 使用Cloudera Manager搭建zookeeper集群及HDFS HA实战篇
使用Cloudera Manager搭建zookeeper集群及HDFS HA实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用Cloudera Manager搭建zo ...
- 使用Cloudera Manager搭建HDFS完全分布式集群
使用Cloudera Manager搭建HDFS完全分布式集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 关于Cloudera Manager的搭建我这里就不再赘述了,可以参考 ...
- 使用Cloudera Manager部署Spark服务
使用Cloudera Manager部署Spark服务 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 1>.点击添加服务进入CM服务安装向导 2>.选择需要安装的spa ...
随机推荐
- [LeetCode] 380. Insert Delete GetRandom O(1) 插入删除获得随机数O(1)时间
Design a data structure that supports all following operations in average O(1) time. insert(val): In ...
- 【SSH进阶之路】Spring的AOP逐层深入——采用注解完成AOP(七)
上篇博文[SSH进阶之路]Spring的AOP逐层深入——AOP的基本原理(六),我们介绍了AOP的基本原理,以及5种通知的类型, AOP的两种配置方式:XML配置和Aspectj注解方式. 这篇我们 ...
- ehcache和redis的区别及适用场景
区别: (1)Redis 独立程序,是通过socket访问到缓存服务,效率比ecache低,比数据库要快很多,处理集群和分布式缓存方便,有成熟的方案 (2)Ehcache 直接在jvm虚拟机中缓存,速 ...
- Oracle Spatial分区应用研究之一:分区与分表查询性能对比
1.名词解释 分区:将一张大表在物理上分成多个分区,逻辑上仍然是同一个表名. 分表:将一张大表拆分成多张小表,不同表有不同的表名. 两种数据组织形式的原理图如下: 图 1分表与分区的原理图 2.实验目 ...
- python的安装与配置
pyhton的下载与安装 1.python官网地址:https://www.python.org 2.下载 Python 编辑器PyCharm PyCharm 是一款功能强大的 Python 编辑器 ...
- 【剑指offer】面试题 31. 栈的压入、弹出序列
面试题 31. 栈的压入.弹出序列 NowCoder LeetCode 题目描述 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序.假设压入栈的所有数字均不相等.例如 ...
- 将自定义jar包上传github并制作成maven仓库
参照:https://www.jianshu.com/p/98a141701cc7 第一阶段 :配置github 1.创建mvn-repo分支 首先在你的github上创建一个maven-re ...
- day20——规范化目录
day20 为什么要有规范化目录 可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等.从而非常快速的了解这个项目. 可维护性高: 定 ...
- 05- if-else语句、循环for
if-else 语句 if是条件语句.if语句的语法是 if 条件{ #注意大括号和条件之间不能换行 执行代码 } if语句还包括else if 和 else 部分 package main impo ...
- CCS中的linked resource
一.关于CCS中的linked resource linkded resources 是eclipse中的一个功能,可以将存放在项目所在位置以外某个路径的文件或者文件夹链接至工程项目中.这个功能最大的 ...