HBase 系列(三)—— HBase 基本环境搭建
一、安装前置条件说明
1.1 JDK版本说明
HBase 需要依赖 JDK 环境,同时 HBase 2.0+ 以上版本不再支持 JDK 1.7 ,需要安装 JDK 1.8+ 。JDK 安装方式见本仓库:
1.2 Standalone模式和伪集群模式的区别
- 在
Standalone模式下,所有守护进程都运行在一个jvm进程/实例中; - 在伪分布模式下,HBase 仍然在单个主机上运行,但是每个守护进程 (HMaster,HRegionServer 和 ZooKeeper) 则分别作为一个单独的进程运行。
说明:两种模式任选其一进行部署即可,对于开发测试来说区别不大。
二、Standalone 模式
2.1 下载并解压
从官方网站 下载所需要版本的二进制安装包,并进行解压:
# tar -zxvf hbase-2.1.4-bin.tar.gz2.2 配置环境变量
# vim /etc/profile添加环境变量:
export HBASE_HOME=/usr/app/hbase-2.1.4
export PATH=$HBASE_HOME/bin:$PATH使得配置的环境变量生效:
# source /etc/profile2.3 进行HBase相关配置
修改安装目录下的 conf/hbase-env.sh,指定 JDK 的安装路径:
# The java implementation to use. Java 1.8+ required.
export JAVA_HOME=/usr/java/jdk1.8.0_201修改安装目录下的 conf/hbase-site.xml,增加如下配置:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///home/hbase/rootdir</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/zookeeper/dataDir</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>hbase.rootdir: 配置 hbase 数据的存储路径;
hbase.zookeeper.property.dataDir: 配置 zookeeper 数据的存储路径;
hbase.unsafe.stream.capability.enforce: 使用本地文件系统存储,不使用 HDFS 的情况下需要禁用此配置,设置为 false。
2.4 启动HBase
由于已经将 HBase 的 bin 目录配置到环境变量,直接使用以下命令启动:
# start-hbase.sh2.5 验证启动是否成功
验证方式一 :使用 jps 命令查看 HMaster 进程是否启动。
[root@hadoop001 hbase-2.1.4]# jps
16336 Jps
15500 HMaster验证方式二 :访问 HBaseWeb UI 页面,默认端口为 16010 。
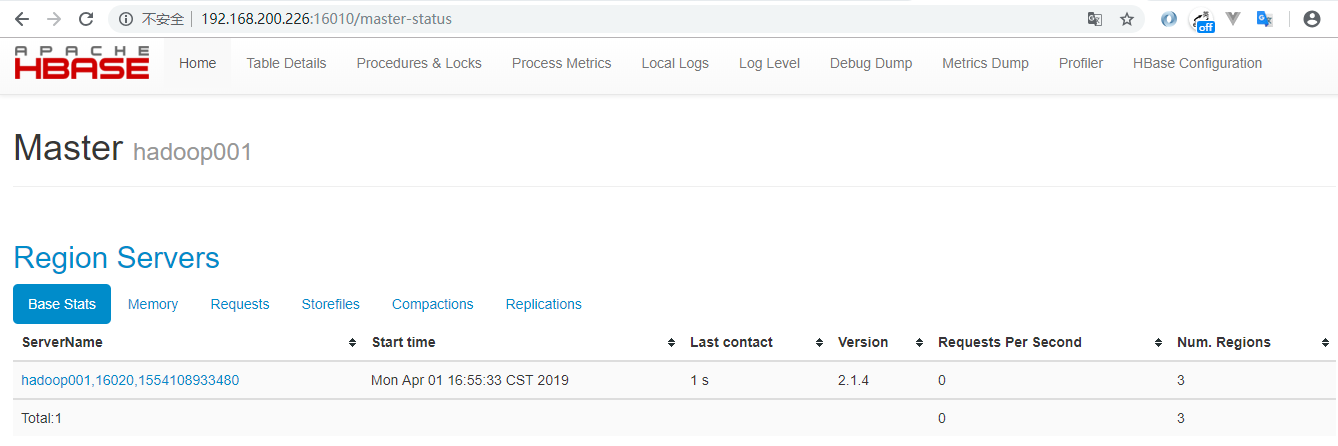
三、伪集群模式安装(Pseudo-Distributed)
3.1 Hadoop单机伪集群安装
这里我们采用 HDFS 作为 HBase 的存储方案,需要预先安装 Hadoop。Hadoop 的安装方式单独整理至:
3.2 Hbase版本选择
HBase 的版本必须要与 Hadoop 的版本兼容,不然会出现各种 Jar 包冲突。这里我 Hadoop 安装的版本为 hadoop-2.6.0-cdh5.15.2,为保持版本一致,选择的 HBase 版本为 hbase-1.2.0-cdh5.15.2 。所有软件版本如下:
- Hadoop 版本: hadoop-2.6.0-cdh5.15.2
- HBase 版本: hbase-1.2.0-cdh5.15.2
- JDK 版本:JDK 1.8
3.3 软件下载解压
下载后进行解压,下载地址:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zxvf hbase-1.2.0-cdh5.15.2.tar.gz3.4 配置环境变量
# vim /etc/profile添加环境变量:
export HBASE_HOME=/usr/app/hbase-1.2.0-cdh5.15.2
export PATH=$HBASE_HOME/bin:$PATH使得配置的环境变量生效:
# source /etc/profile3.5 进行HBase相关配置
1.修改安装目录下的 conf/hbase-env.sh,指定 JDK 的安装路径:
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME=/usr/java/jdk1.8.0_2012.修改安装目录下的 conf/hbase-site.xml,增加如下配置 (hadoop001 为主机名):
<configuration>
<!--指定 HBase 以分布式模式运行-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--指定 HBase 数据存储路径为 HDFS 上的 hbase 目录,hbase 目录不需要预先创建,程序会自动创建-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop001:8020/hbase</value>
</property>
<!--指定 zookeeper 数据的存储位置-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/zookeeper/dataDir</value>
</property>
</configuration>3.修改安装目录下的 conf/regionservers,指定 region servers 的地址,修改后其内容如下:
hadoop0013.6 启动
# bin/start-hbase.sh3.7 验证启动是否成功
验证方式一 :使用 jps 命令查看进程。其中 HMaster,HRegionServer 是 HBase 的进程,HQuorumPeer 是 HBase 内置的 Zookeeper 的进程,其余的为 HDFS 和 YARN 的进程。
[root@hadoop001 conf]# jps
28688 NodeManager
25824 GradleDaemon
10177 Jps
22083 HRegionServer
20534 DataNode
20807 SecondaryNameNode
18744 Main
20411 NameNode
21851 HQuorumPeer
28573 ResourceManager
21933 HMaster验证方式二 :访问 HBase Web UI 界面,需要注意的是 1.2 版本的 HBase 的访问端口为 60010
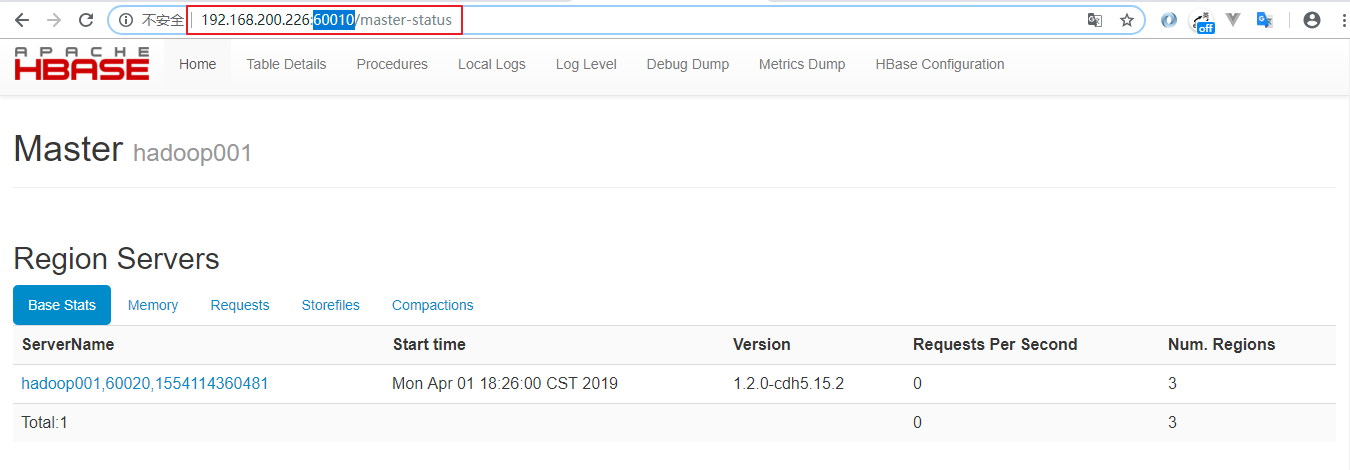
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
HBase 系列(三)—— HBase 基本环境搭建的更多相关文章
- 基于GTK+3 开发远程控制管理软件(C语言实现)系列三 Windows7开发环境搭建
一.介绍与准备 考虑到目标客户端基本都是windows客户端,所以此次开发环境将搭建在windows7下,相关开发工具有Msys2 和 Eclipse For C/C++ Msys2 是msys的升级 ...
- Qt在Windows下的三种编程环境搭建
尊重作者,支持原创,如需转载,请附上原地址:http://blog.csdn.net/libaineu2004/article/details/17363165 从QT官网可以得知其支持的平台.编译器 ...
- Qt4.8在Windows下的三种编程环境搭建
Qt4.8在Windows下的三种编程环境搭建 Qt的版本是按照不同的图形系统来划分的,目前分为四个版本:Win32版,适用于Windows平台:X11版,适合于使用了X系统的各种Linux和Unix ...
- Qt在Windows下的三种编程环境搭建(图文并茂,非常清楚)good
尊重作者,支持原创,如需转载,请附上原地址:http://blog.csdn.net/libaineu2004/article/details/17363165 从QT官网可以得知其支持的平台.编译器 ...
- 【Qt开发】Qt在Windows下的三种编程环境搭建
从QT官网可以得知其支持的平台.编译器和调试器的信息如图所示: http://qt-project.org/doc/qtcreator-3.0/creator-debugger-engines.htm ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- RabbitMQ学习系列三:.net 环境下 C#代码订阅 RabbitMQ 消息并处理
上一篇已经讲了Rabbitmq如何在Windows平台安装 不懂请移步: RabbitMQ学习系列二:.net 环境下 C#代码使用 RabbitMQ 消息队列 一.理论 .net环境下,C#代码订阅 ...
- .Net Core 系列:1、环境搭建
前言: 2016年6月28日微软宣布发布 .NET Core 1.0.ASP.NET Core 1.0 和 Entity Framework Core 1.0. .NET Core是微软在两年前发起的 ...
- windows phone 8 开发系列(一)环境搭建
一:前奏说明 本人一名普通的neter,对新玩意有点小兴趣,之前wp7出来的时候,折腾学习过点wp7开发,后来也没怎么用到(主要对微软抛弃wp7的行为比较不爽),现在wp8已经出来一段时间了,市场上也 ...
随机推荐
- Java编程思想之七复用类
复用代码是Java众多引人注目的功能之一.但要想成为极具革命性的语言,仅仅能够复制代码并对之加以改变是不够的,它还必须做更多的事情. 使用类而不破坏程序代码: 在新类中产生现有对象.由于新的类是由现有 ...
- unix udp sendto 最大可发送的数据长度
sendto 的最大可发送数据长度受限于两个值. 第一 [2^16 -1 - 8 -20] 第二 [SO_SNDBUF] 解释受限于[2^16-1-8-20] 数据封装过程 第一步: 用户层 : us ...
- 使用Alibaba的Nacos做为SpringCloud的注册和配置中心,并结合Sentinel+Nocos动态进行限流熔断
最近在学习阿里的Nacos组件以及Sentinel组件,折腾出了一个小demo. Git地址:https://github.com/yangzhilong/nacos-client 有兴趣的小伙伴可以 ...
- sql server中raiserror的用法(动态参数传值)
1.raiserrror定义: 返回用户定义的错误信息并设系统标志,记录发生错误.通过使用 RAISERROR 语句,客户端可以从 sysmessages 表中检索条目, 或者使用用户指定的严重度和状 ...
- ESB企业服务总线到底是什么东西呢?
顾名思义,企业服务总线(ESB)就是一条企业架构的总线,所有的企业服务都挂接到该总线上对外公布,企业服务总线负责管理服务目录,解析服务请求者的请求方法.消息格式,并对服务提供者进行寻址,转发服务请求. ...
- cps在jenkins构建报错
修改ares的版本号即可,改为2.0.1.14-20191126-RELEASE
- 卷积神经网络概念及使用 PyTorch 简单实现
卷积神经网络 卷积神经网络(CNN)是深度学习的代表算法之一 .具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络”.随着深度学习理论的提出和数值计算设备 ...
- LeetCode 108. Convert Sorted Array to Binary Search Tree (将有序数组转换成BST)
108. Convert Sorted Array to Binary Search Tree Given an array where elements are sorted in ascendin ...
- 在nginx环境下搭建基于ssl证书的websocket服务转发,wss
1.证书准备 本地调试,可以安装自签名证书,安装方法参考https本地自签名证书添加到信任证书访问 2.修改配置文件 将上面的配置文件拷贝到conf目录,添加或者修改节点如下 # HTTPS serv ...
- phpspreadsheet 中文文档(二) 结构+自动筛选
2019年10月11日13:55:41 原理图 自动加载器 PhpSpreadsheet依赖于Composer自动加载器.因此,在独立使用PhpSpreadsheet之前,请确保先运行composer ...