ubuntu之路——day10.2单一数字评估指标与满足和优化的评估指标
单一数字评估指标:
FP:错误地标记为正,即算法预测它是好西瓜,但这个西瓜真实情况是坏西瓜;
FN:错误地标记为负,即算法预测为坏西瓜,(F算法预测的不对)但这个西瓜真实情况是好西瓜(双重否定也是肯定);
TN:正确地标记为负,即算法标记为坏西瓜,(T算法预测的正确)这个西瓜真实情况是坏西瓜。
所以有:



当beta>1时查全率重要,beta<1时查准率重要
以上关于精度、查准率、查全率的论述转自https://blog.csdn.net/qq_27871973/article/details/81065074 总结的很好所以我没有改动。
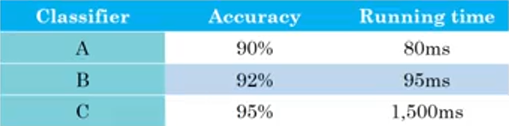
首先Accuracy也可以是上述单一数字评估指标中的任何一种,然后我们又得到了算法的时间性能running time。在这两种条件下如何综合衡量模型的好坏呢?
第一种方法:
线性叠加的思路:cost = Accuracy - 0.5Running time
当然这种线性加权求和的方式显得有些武断
第二种方法:
满足和优化的思路:cost = max(Accuracy) && Running time < 100
这种思路下,认为Accuracy是一种优化指标optimizing metric,同时Running time是一种满足指标satisficing metric,因为只要其满足了条件之后无论多好我们不再关注。
总结一下:当你有N个指标去考量的时候,通常选取其中的1种作为优化指标,剩下的N-1都是满足指标
ubuntu之路——day10.2单一数字评估指标与满足和优化的评估指标的更多相关文章
- ubuntu之路——day10.7 提高模型的表现
总结一下就是在提升偏差的方面(即贝叶斯最优误差和训练误差的差距) 1.尝试更大更深的网络 2.加入优化算法比如前面提过的momentum.RMSprop.Adam等 3.使用别的神经网络架构比如RNN ...
- ubuntu之路——day10.6 如何理解人类表现和超过人类表现
从某种角度来说,已知的人类最佳表现其实可以被当做贝叶斯最优错误,对于医学图像分类可以参见下图中的例子. 那么如何理解超过人类表现,在哪些领域机器已经做到了超越人类呢?
- ubuntu之路——day10.5 可避免偏差
可避免偏差: 总结一下就是当贝叶斯最优误差接近于训练误差的时候,比如下面的例子B,我们不会说我们的训练误差是8%,我们会说我可避免偏差是0.5%.
- ubuntu之路——day10.4 什么是人的表现
结合吴恩达老师前面的讲解,可以得出一个结论: 在机器学习的早期阶段,传统的机器学习算法在没有赶超人类能力的时候,很难比较这些经典算法的好坏.也许在不同的数据场景下,不同的ML算法有着不同的表现. 但是 ...
- ubuntu之路——day10.3 train/dev/test的划分、大小和指标更新
train/dev/test的划分 我们在前面的博文中已经提到了train/dev/test的相关做法.比如不能将dev和test混为一谈.同时要保证数据集的同分布等. 现在在train/dev/t ...
- ubuntu之路——day10.1 ML的整体策略——正交化
orthogonalization 正交化的概念就是指,将你可以调整的参数设置在不同的正交的维度上,调整其中一个参数,不会或几乎不会影响其他维度上的参数变化,这样在机器学习项目中,可以让你更容易更快速 ...
- [DeeplearningAI笔记]ML strategy_1_1正交化/单一数字评估指标
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 什么是ML策略 机器学习策略简介 情景模拟 假设你正在训练一个分类器,你的系统已经达到了90%准确 ...
- Python之路,Day10 - 异步IO\数据库\队列\缓存
Python之路,Day9 - 异步IO\数据库\队列\缓存 本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitM ...
- python之路-Day10
操作系统发展史介绍 进程.与线程区别 python GIL全局解释器锁 线程 语法 join 线程锁之Lock\Rlock\信号量 将线程变为守护进程 Event事件 queue队列 生产者消费者模型 ...
随机推荐
- mongoose 警告信息 { useNewUrlParser: true } { useUnifiedTopology: true }
问题: 解决:
- HTTP协议复习一--认识HTTP
HTTP 是什么 HTTP 是一个在计算机世界里专门在两点之间传输文字.图片.音频.视频等超文本数据的约定和规范. HTTP 是一个用在计算机世界里的协议,它确立了一种计算机之间交流通信的规范,以及相 ...
- SetCurrentCellAddressCore 函数的可重入调用
绑定数据在线程中 private void dataGridView1_CellEndEdit(object sender, DataGridViewCellEventArgs e) { if (Di ...
- DRF 视图初识
from django.shortcuts import render from rest_framework.generics import ListAPIView,CreateAPIView,Up ...
- Kubernetes- Dashboard 部署
获取dashboard 的yaml文件 wget wget https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/dep ...
- QT5无法定位程序输入点 于动态链接库QtCore5.dll的解决
本人新手刚接触QT5,今天在写程序时,在QtCreator中可以运行,但是单独运行.exe文件时报错 之后发现是因为我之前在path路径中添加了MinGw,导致里面也有Qt库.但是我编译的时候用的是安 ...
- python 全局声明 global
https://www.cnblogs.com/Lin-Yi/p/7305364.html 在基本的python语法当中,一个函数可以随意读取全局数据,但是要修改全局数据的时候有两种方法:1 glob ...
- readme.txt 为什么我们不重视
1.很多源码项目下面都有编译说明,readme 2.我们的电脑上每个目录都有很多文件,我们似乎可以建立一个readme.txt 知道是什么 节约一些时间
- dt二次开发之-url伪静态的自定义
dt内核的方便性在于代码内核完全开源,都可以根据自身需要进行优化整改,个人在这段时间的深入研究,发现这套内核的方便性,今天继续给大家分享下DT的url伪静态如何自定义函数. url自定义文件是在api ...
- CF553E Kyoya and Train
Kyoya and Train 一个有\(n\)个节点\(m\)条边的有向图,每条边连接了\(a_i\)和\(b_i\),花费为\(c_i\). 每次经过某一条边就要花费该边的\(c_i\). 第\( ...