Apache Flink - 架构和拓扑
Flink结构:

- flink cli 解析本地环境配置,启动
ApplicationMaster - 在
ApplicationMaster中启动JobManager - 在
ApplicationMaster中启动YarnFlinkResourceManager YarnFlinkResourceManager给JobManager发送注册信息YarnFlinkResourceManager注册成功后,JobManager给YarnFlinkResourceManager发送注册成功信息YarnFlinkResourceManage知道自己注册成功后像ResourceManager申请和TaskManager数量对等的 container- 在container中启动
TaskManager TaskManager将自己注册到JobManager中
接下来便是程序的提交和运行。
- flink cli 解析本地环境配置,启动
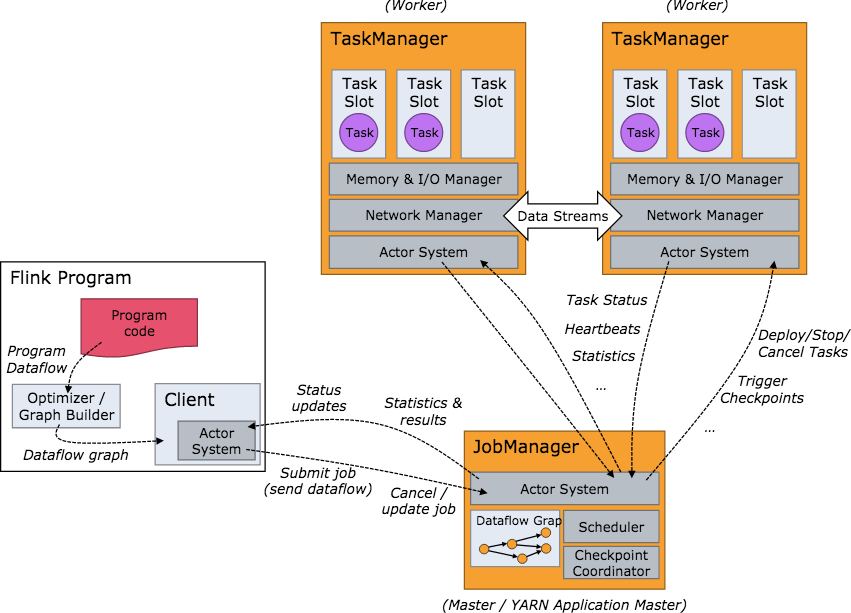
JobManager负责接收 flink 的作业,调度 task,收集 job 的状态、jar 包管理,checkpoint 的协调和发起,管理 TaskManagers。- 算子:flink 的一个 operator 代表一个最顶级的 API接口。对于streaming,在 DataStream 上做诸如 map/reduce/keyBy 等操作均会生成一个算子。
- TaskManager 在 Flink 中也被叫做一个 Instance,统一管理该物理节点上的所有Flink job的task运行,它的功能包括了task的启动销毁、内存管理、磁盘IO、网络传输管理等等。
- 下方是 Flink 集群启动后架构图:
Graph:
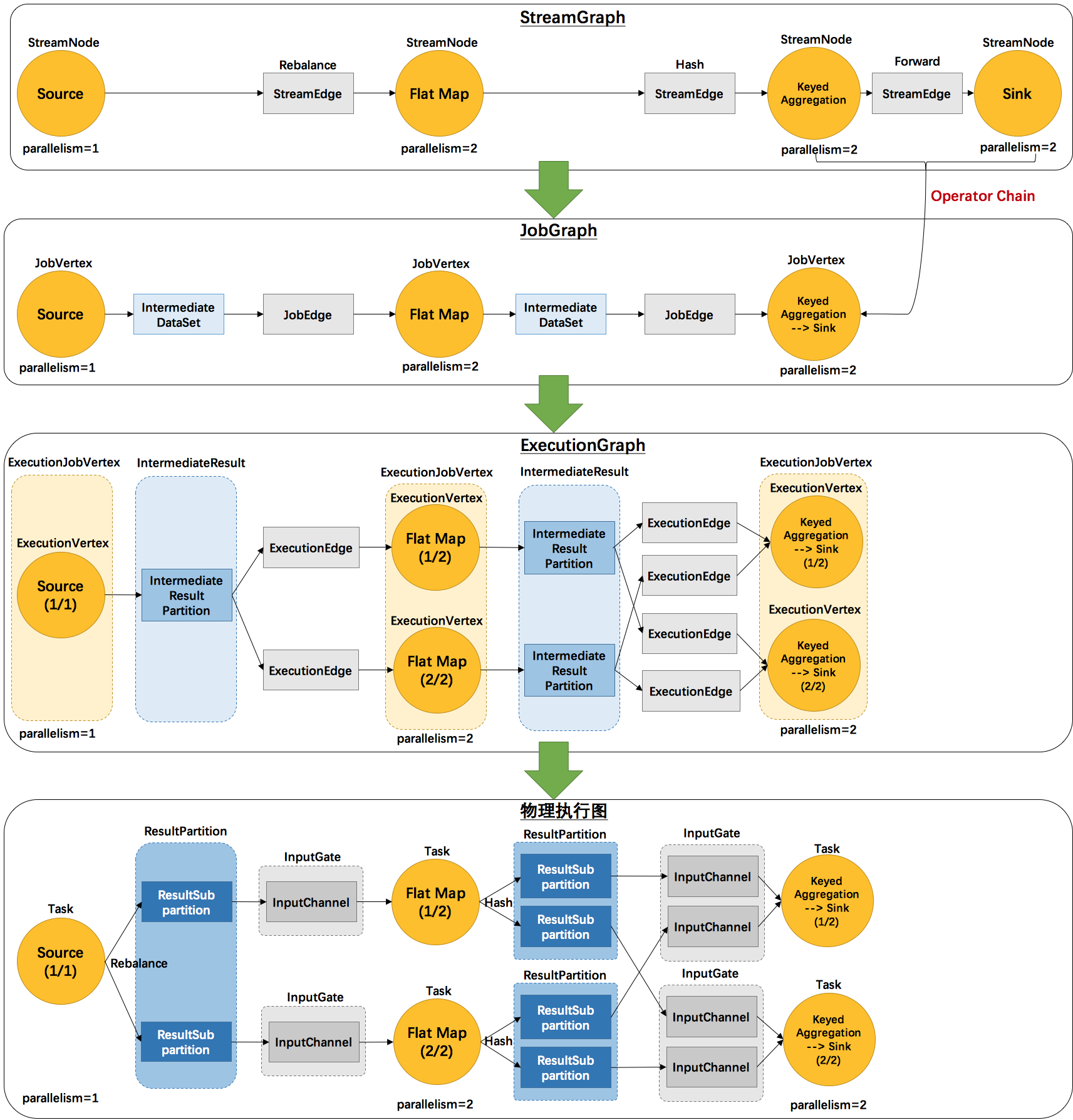
- Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。方便调度和监控和跟踪各个 tasks 的状态。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
- 2个并发度(Source为1个并发度)的
SocketTextStreamWordCount四层执行图的演变过程:- StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
- StreamNode:用来代表 operator 的类,并具有所有相关的属性,如并发度、入边和出边等。
- StreamEdge:表示连接两个StreamNode的边。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
- JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
- IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。
- JobEdge:代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
- ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition。
- IntermediateResult:和JobGraph中的IntermediateDataSet一一对应。一个IntermediateResult包含多个IntermediateResultPartition,其个数等于该operator的并发度。
- IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
- ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
- Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
- Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
- ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。
- ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
- InputGate:代表Task的输入封装,和JobGraph中JobEdge一一对应。每个InputGate消费了一个或多个的ResultPartition。
- InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。
- StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
Apache Flink - 架构和拓扑的更多相关文章
- Apache Flink系列(1)-概述
一.设计思想及介绍 基本思想:“一切数据都是流,批是流的特例” 1.Micro Batching 模式 在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定 ...
- Apache Flink:特性、概念、组件栈、架构及原理分析
2016-04-30 22:24:39 Yanjun Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtim ...
- flink架构介绍
前言 flink作为基于流的大数据计算引擎,可以说在大数据领域的红人,下面对flink-1.7的架构进行逻辑上的分析并和spark做了一些关键点的对比. 架构 如图1,flink架构分为3个部分,cl ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Apache Flink Quickstart
Apache Flink 是新一代的基于 Kappa 架构的流处理框架,近期底层部署结构基于 FLIP-6 做了大规模的调整,我们来看一下在新的版本(1.6-SNAPSHOT)下怎样从源码快速编译执行 ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
- Apache Flink 介绍
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483660&idx=1&sn=ecf01cfc8 ...
- Flink架构、原理与部署测试(转)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- 终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码
摘要: 如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月底正式开源.今天,我们终于等到了这一刻. 阿里妹导 ...
随机推荐
- VUE过滤器 基础回顾5
过滤器是一种在模板中处理数据的便捷方式,特别适合对字符串和数组进行简易显示 <div id="app"> <p>商品1花费{{oneCost | froma ...
- ffmpeg基础使用
https://www.jianshu.com/p/ddafe46827b7
- 【书评:Oracle查询优化改写】第14章 结尾章
[书评:Oracle查询优化改写]第14章 结尾章 一.1 相关参考文章链接 前13章的链接参考相关连接: [书评:Oracle查询优化改写]第一章 http://blog.itpub.net/26 ...
- .net core jenkins持续集成
执行 Shell pwd ls echo ${PATH} whoami which dotnet dotnet --info dotnet --version echo '============== ...
- oracle instantclient_12_2安装
下载地址 http://www.oracle.com/technetwork/database/database-technologies/instant-client/downloads/index ...
- Linux之RHEL7root密码破解(三)
Linux系列root密码破解第三种方式,利用修改boot分区里的开机启动顺序来修改密码,即我们进入BIOS,修改boot启动顺序为CD-ROM: 接下来按F10保存退出 选择Troubleshoot ...
- OpenStack核心组件-neutron网络服务
1. neutron 介绍 1.1 Neutron 概述 传统的网络管理方式很大程度上依赖于管理员手工配置和维护各种网络硬件设备:而云环境下的网络已经变得非常复杂,特别是在多租户场景里,用户随时都可能 ...
- KMP算法的时间复杂度与next数组分析
一.什么是 KMP 算法 KMP 算法是一种改进的字符串匹配算法,用于判断一个字符串是否是另一个字符串的子串 二.KMP 算法的时间复杂度 O(m+n) 三.Next 数组 - KMP 算法的核心 K ...
- 逆向破解之160个CrackMe —— 007
CrackMe —— 007 160 CrackMe 是比较适合新手学习逆向破解的CrackMe的一个集合一共160个待逆向破解的程序 CrackMe:它们都是一些公开给别人尝试破解的小程序,制作 c ...
- Kotlin属性引用详解
继续来学习Kotlin反射相关的,这次主要是跟反射属性相关的东东. 属性引用(Property Reference): 属性引用的用法与函数(方法)引用的用法是完全一致,都是通过::形式来引用的.下面 ...