python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>>
爬取酷狗歌单,保存入csv文件
直接上源代码:(含注释)
import requests #用于请求网页获取网页数据
from bs4 import BeautifulSoup #解析网页数据
import time #time库中的sleep()方法可以让程序暂停
import csv '''
爬虫测试
酷狗top500数据
写入csv文件
'''
fp = open('D://kugou.csv','wt',newline='',encoding='utf-8')#创建csv
writer = csv.writer(fp)
writer.writerow(('rank','singer','song','time'))
#加入请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
} #定义获取信息的函数
def get_info(url):
wb_data = requests.get(url,headers=headers)#get方法加入请求头
soup = BeautifulSoup(wb_data.text,'html.parser')#对返回结果进行解析
#定位元素位置并通过selector方法获取
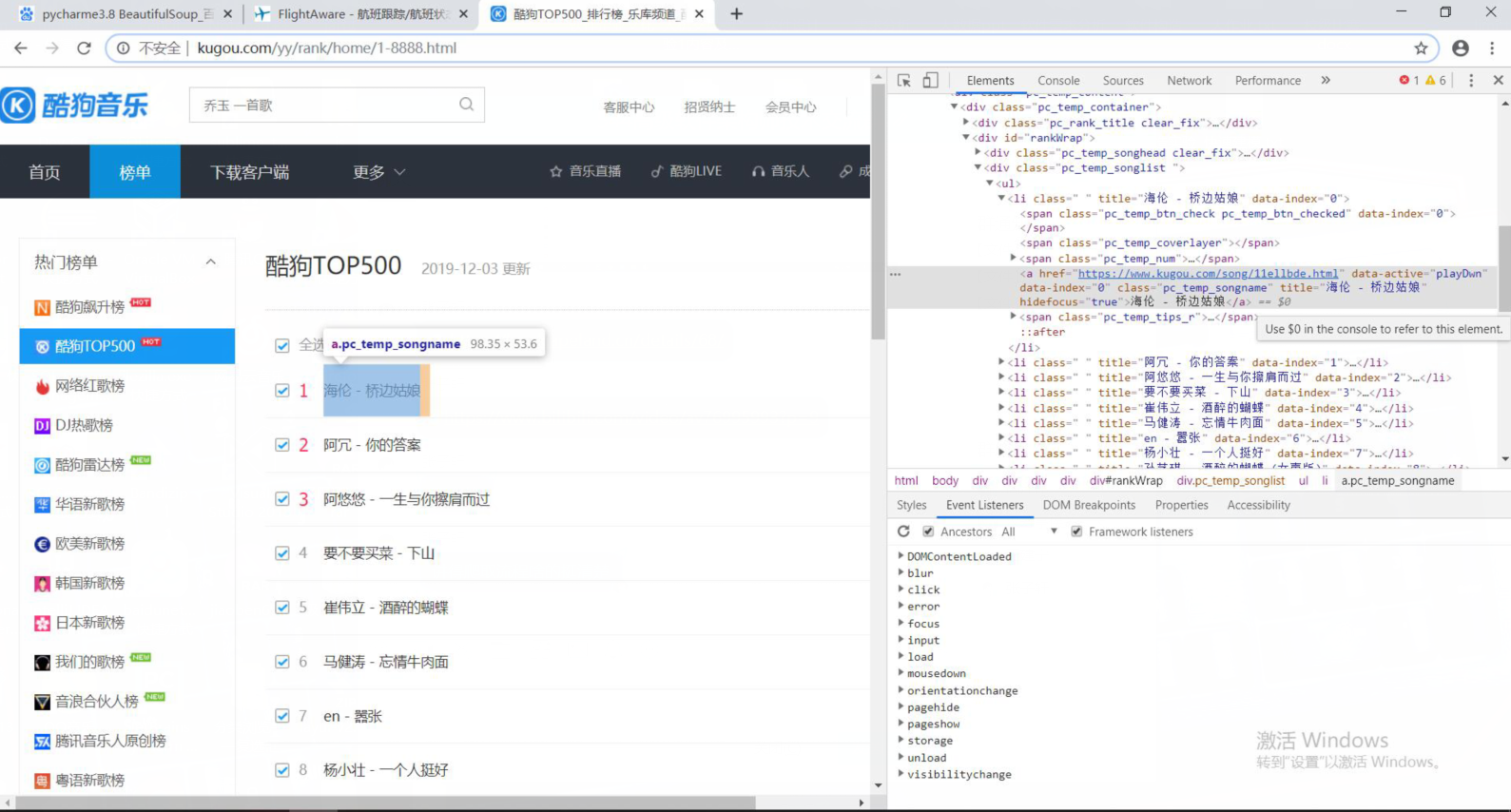
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank,title,time in zip(ranks,titles,times):
data = {
'rank':rank.get_text().strip(),
'singer':title.get_text().split('-')[0],
'song':title.get_text().split('-')[0],#通过split获取歌手和歌曲信息
'time':time.get_text().strip()#get_text()获取文本内容
}
writer.writerow((rank.get_text().strip(),title.get_text().split('-')[0],title.get_text().split('-')[0],time.get_text().strip()))
# 获取爬取信息并按字典格式打印
#print(data) #程序主入口
if __name__ == '__main__':
urls = ['http://www.kugou.com/yy/rank/home/{}-8888.html'.format(str(i)) for i in range(1,4)]#构造多页url
for url in urls:
get_info(url)#循环调用
time.sleep(1)#每循环一次,睡眠1秒,防止网页浏览频率过快导致爬虫失败
爬虫实例
浏览器:Chrome
请求头获取方法:
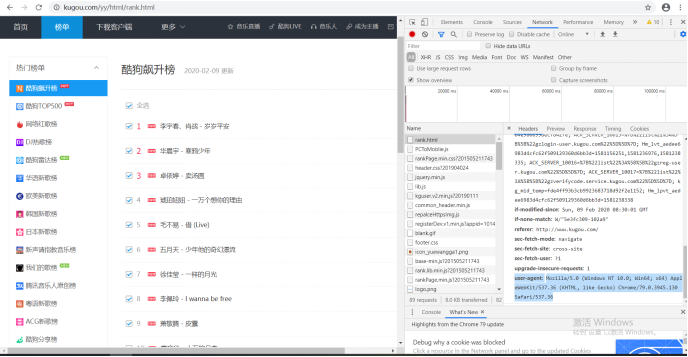
网站爬取:
python爬虫实例——爬取歌单的更多相关文章
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- python爬虫项目-爬取雪球网金融数据(关注、持续更新)
(一)python金融数据爬虫项目 爬取目标:雪球网(起始url:https://xueqiu.com/hq#exchange=CN&firstName=1&secondName=1_ ...
- Python 2.7_爬取CSDN单页面博客文章及url(二)_xpath提取_20170118
上次用的是正则匹配文章title 和文章url,因为最近在看Scrapy框架爬虫 需要了解xpath语法 学习了下拿这个例子练手 1.爬取的单页面还是这个rooturl:http://blog.csd ...
- Python 2.7_爬取CSDN单页面利用正则提取博客文章及url_20170114
年前有点忙,没来的及更博,最近看爬虫正则的部分 巩固下 1.爬取的单页面:http://blog.csdn.net/column/details/why-bug.html 2.过程 解析url获得网站 ...
随机推荐
- Pandas操作excel
读取excel:Pandas库read_excel()参数详解 pandas.read_excel(io,sheet_name = 0,header = 0,names = None,index_co ...
- 《 .NET并发编程实战》阅读指南 - 第3章
先发表生成URL以印在书里面.等书籍正式出版销售后会公开内容.
- Java实习生入职测试
网络上一度流行的Java实习生入职测试题,可以看看. 1.String类为什么是final的. 2.JDK8的HashMap的源码,实现原理,底层结构 3.反射中,Class.forName和clas ...
- 阿里OSS前端直传
第一次写博客,如有错误请多多指教. 先上代码吧: ossUpload = function (file, fun, funParameter) { //第一此请求后台服务器获取认证请求 $.ajax( ...
- DatetimeHelper类的编写
公共类 DAtaTimeHelper类的编写 public class Appointment { public DateTime StartDate { get; set; } public Dat ...
- Asp.Net页面刷新防止跳转到其他浏览器或新的选项卡
前端页面js代码: <head> <script> window.name = "PremaritalCheckup_ManSocietyAgreeForm" ...
- 使用Docker之镜像的拉取、查询、删除
1:查看镜像列表 2:拉取镜像 通过命令可以从镜像仓库中拉取镜像,默认从Docker Hub 获取. 命令格式: docker image pull <repository>:< ...
- C#/.Net操作MongoDBHelper类
先 NuGet两个程序集 1:MongoDB.Driver. 2:MongoDB.Bson namespace ConsoleApp1{ /// <summary> /// Mongo ...
- Python: 把txt文件转换成csv
最近在项目上需要批量把txt文件转成成csv文件格式,以前是手动打开excel文件,然后导入txt来生产csv文件,由于这已经变成每周需要做的事情,决定用python自动化脚本来实现,思路: 读取文件 ...
- 使用Nginx反向代理Docker的Asp.Net Core项目的请求
承接上文的对Kestrel的思考 上一篇介绍了如何一下在docker中发布Asp.Net Core项目(传送门)在最后尝试从外网访问网站的时候发现请求的响应头中包含了这个信息Server:Kestre ...