RAdam VS Adam
论文解读:Radam:ON THE VARIANCE OF THE ADAPTIVE LEARNING RATE AND BEYOND
1,目的
想找到一个比较好的优化器,能够在收敛速度和收敛的效果上都比较号。
目前sgd收敛较好,但是慢。
adam收敛快,但是容易收敛到局部解。
常用解决adam收敛问题的方法是,自适应启动方法。
2,adam方法的问题
adam在训练的初期,学习率的方差较大。
根本原因是因为缺少数据,导致方差大。
学习率的方差大,本质上自适应率的方差大。
可以控制自适应率的方差来改变效果。
3,Radam,控制自适应率的方差
一堆数学公式估计出自适应率的最大值和变化过程。
提出了Radam的优化过程
4,实验结论
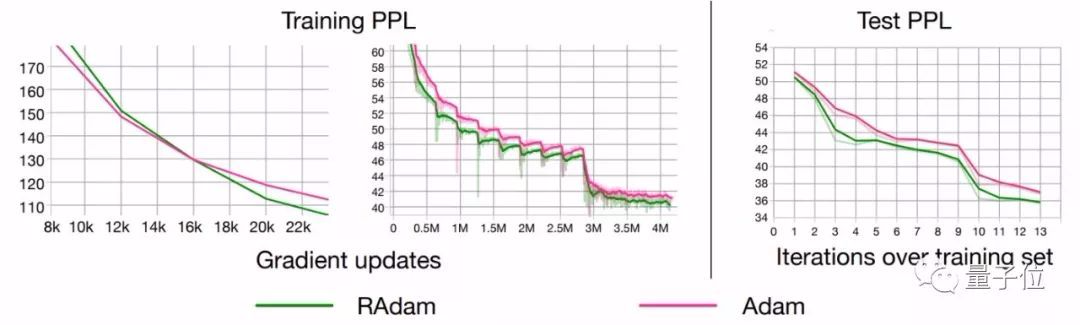
前几个周期内整流项使得RAdam比Adam方法慢,但是在后期的收敛速度是比Adam要更快的。
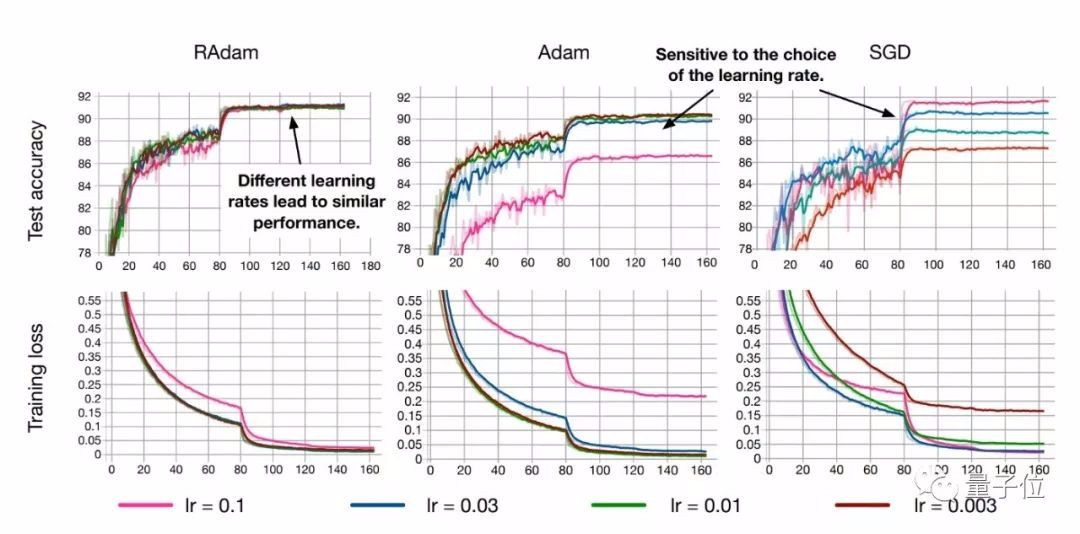
尽管RAdam在测试精度方面未能超越SGD,但它可以带来更好的训练性能。
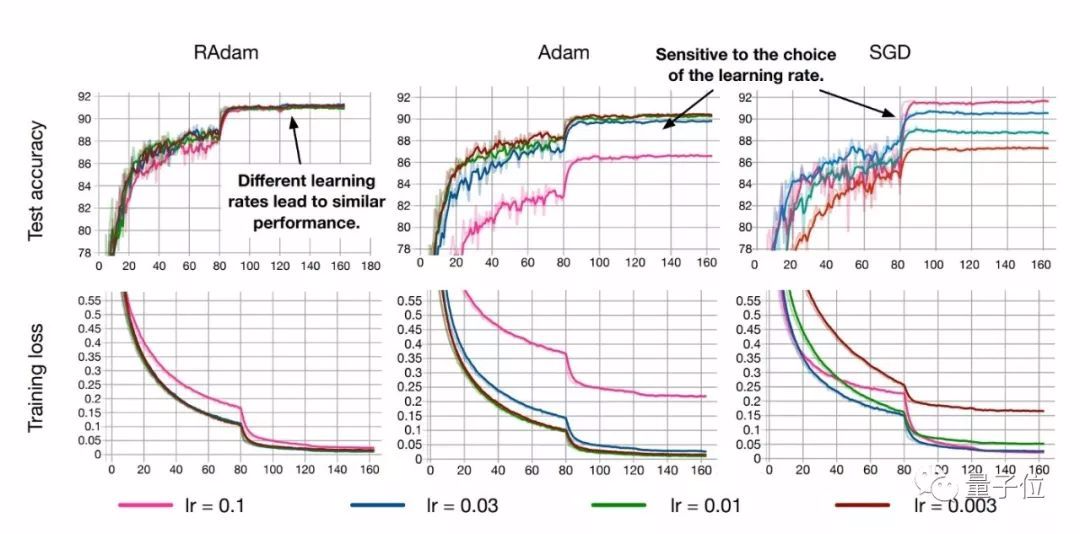
RAdam算法对初始学习率是具有鲁棒性的,可以适应更宽范围内的变化。在从0.003到0.1一个很宽的范围内,RAdam表现出了一致的性能,训练曲线末端高度重合
如果你以为RAdam只能处理较小数据集上的训练,或者只有在CNN上有较好的表现就大错特错了。即使大道有几十亿个单词的数据集的LSTM模型,RAdam依然有比Adam更好的表现。
5,个人理解
优势:鲁棒性强,这个优势很强,而且适合任何模型的初期的实验,也对新手比较友好;不用调试学习率,这个优势也很强;自适应启动的方式会增加超参数,不适合初期的实验。
缺点:论文也提出,他的收敛效果不一定是所有里面最好的。所以在实验的后期,对于老手,可以采用更加精细的学习率控制策略试试会不会拿到另一个好的结果。
==============================================================================
找到一种快速稳定的优化算法,是所有AI研究人员的目标。
但是鱼和熊掌不可兼得。Adam、RMSProp这些算法虽然收敛速度很快,当往往会掉入局部最优解的“陷阱”;原始的SGD方法虽然能收敛到更好的结果,但是训练速度太慢。
最近,一位来自UIUC的中国博士生Liyuan Liu提出了一个新的优化器RAdam。
它兼有Adam和SGD两者的优点,既能保证收敛速度快,也不容易掉入局部最优解,而且收敛结果对学习率的初始值非常不敏感。在较大学习率的情况下,RAdam效果甚至还优于SGD。
RAdam意思是“整流版的Adam”(Rectified Adam),它能根据方差分散度,动态地打开或者关闭自适应学习率,并且提供了一种不需要可调参数学习率预热的方法。
一位Medium网友Less Wright在测试完RAdam算法后,给予了很高的评价:
RAdam可以说是最先进的AI优化器,可以永远取代原来的Adam算法了。
目前论文作者已将RAdam开源,FastAI现在已经集成了RAdam,只需几行代码即可直接调用。
补众家之短
想造出更强的优化器,就要知道前辈们的问题出在哪:
像Adam这样的优化器,的确可以快速收敛,也因此得到了广泛的应用。
但有个重大的缺点是不够鲁棒,常常会收敛到不太好的局部最优解 (Local Optima) ,这就要靠预热 (Warmup)来解决——
最初几次迭代,都用很小的学习率,以此来缓解收敛问题。
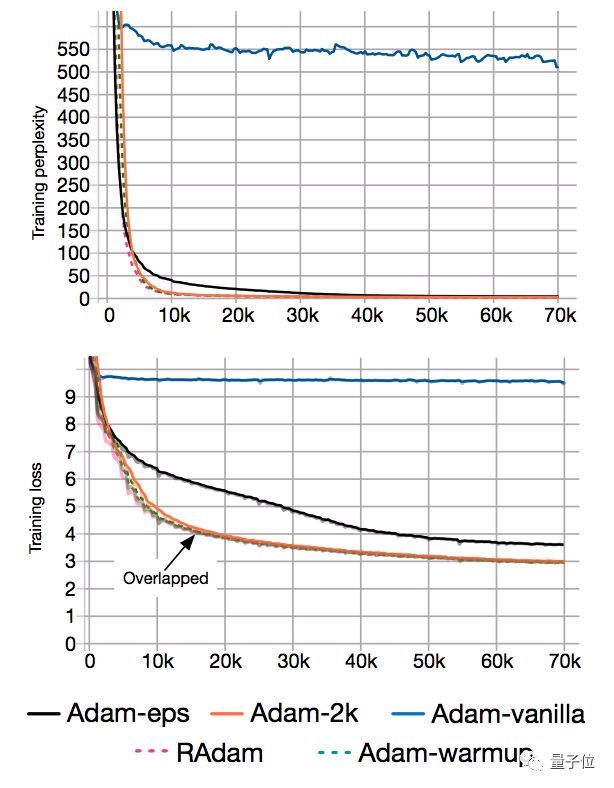
为了证明预热存在的道理,团队在IWSLT’14德英数据集上,测试了原始Adam和带预热的Adam。
结果发现,一把预热拿掉,Transformer语言模型的训练复杂度 (Perplexity) ,就从10增到了500。
另外,BERT预训练也是差不多的情况。
为什么预热、不预热差距这样大?团队又设计了两个变种来分析:
缺乏样本,是问题根源
一个变种是Adam-2k:
在前2000次迭代里,只有自适应学习率是一直更新的,而动量 (Momentum) 和参数都是固定的。除此之外,都沿袭了原始Adam算法。
实验表明,在给它2000个额外的样本来估计自适应学习率之后,收敛问题就消失了:
另外,足够多的样本可以避免梯度分布变扭曲 (Distorted) :
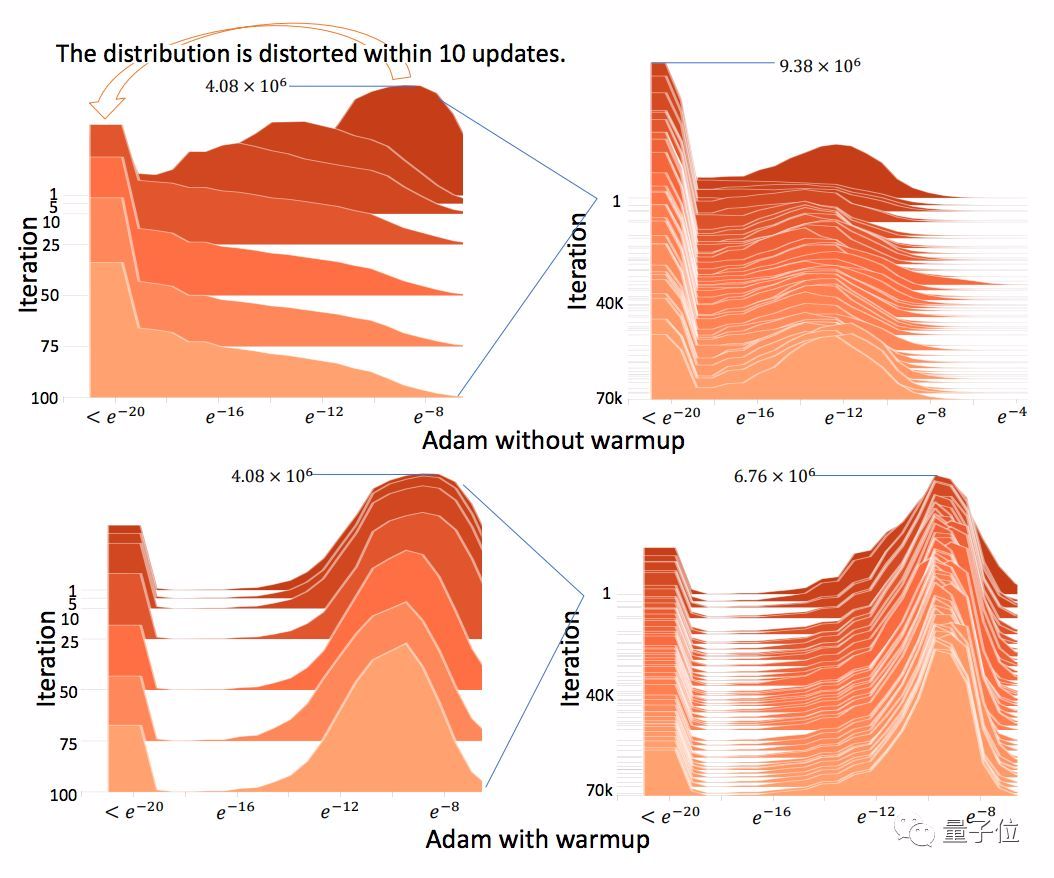
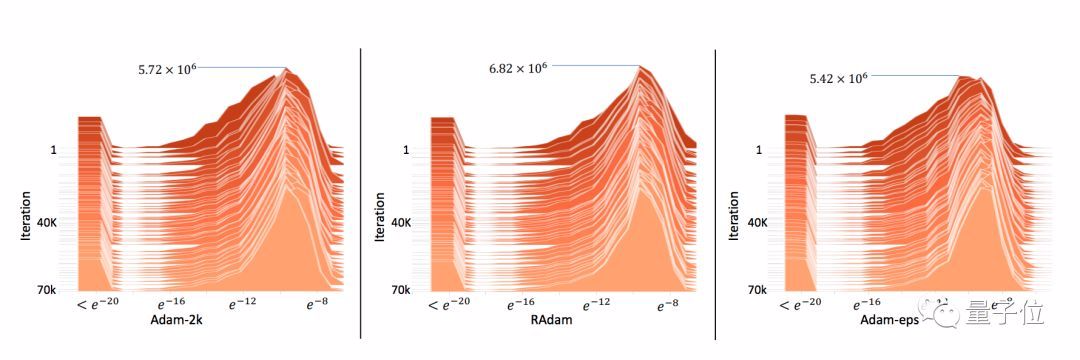
这些发现证明了一点:早期缺乏足够数据样本,就是收敛问题的根源。
下面就要证明,可以通过降低自适应学习率的方差来弥补这个缺陷。
降低方差,可解决问题
一个直接的办法就是:
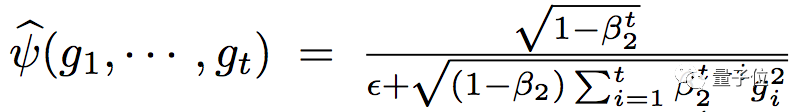
把ψ-cap里面的ϵ增加。假设ψ-cap(. ) 是均匀分布,方差就是1/12ϵ^2。
这样就有了另一个变种Adam-eps。开始把ϵ设成一个可以忽略的1×10^-8,慢慢增加,到不可忽略的1×10^-4。
从实验结果看,它已经没有Adam原本的收敛问题了:

这就证明了,真的可以通过控制方差来解决问题。另外,它和Adam-2k差不多,也可以避免梯度分布扭曲。
然而,这个模型表现比Adam-2k和带预热的Adam差很多。
推测是因为ϵ太大,会给自适应学习率带来重大的偏差 (Bias) ,也会减慢优化的过程。
所以,就需要一个更加严格的方法,来控制自适应学习率。
论文中提出,要通过估算自由度ρ来实现量化分析。
RAdam定义
RAdam算法的输入有:步长αt;衰减率{β1, β2},用于计算移动平均值和它的二阶矩。
输出为θt。

首先,将移动量的一阶矩和二阶矩初始化为m0,v0,计算出简单移动平均值(SMA)的最大长度ρ∞←2/(1-β2)-1。
然后按照以下的迭代公式计算出:第t步时的梯度gt,移动量的二阶矩vt,移动量的一阶矩mt,移动偏差的修正和SMA的最大值ρt。

如果ρ∞大于4,那么,计算移动量二阶矩的修正值和方差修正范围:

如果ρ∞小于等于4,则使用非自适应动量更新参数:
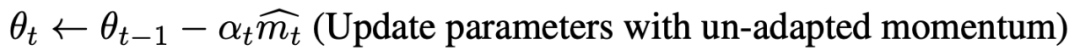
以上步骤都完成后,得出T步骤后的参数θT。
测试结果
RAdam在图像分类任务CIFAR-10和ImageNet上测试的结果如下:
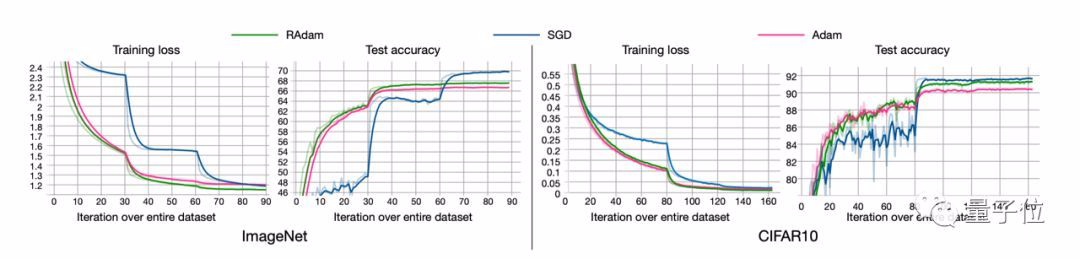
尽管在前几个周期内整流项使得RAdam比Adam方法慢,但是在后期的收敛速度是比Adam要更快的。
尽管RAdam在测试精度方面未能超越SGD,但它可以带来更好的训练性能。
此外,RAdam算法对初始学习率是具有鲁棒性的,可以适应更宽范围内的变化。在从0.003到0.1一个很宽的范围内,RAdam表现出了一致的性能,训练曲线末端高度重合。
亲测过的网友Less Wright说,RAdam和他今年测试的许多其它论文都不一样。
其他方法常常是在特定数据集上有良好的效果,但是放在新的数据集上往往表现不佳。
而RAdam在图像分类、语言建模,以及机器翻译等等许多任务上,都证明有效。
(也侧面说明,机器学习的各类任务里,广泛存在着方差的问题。)
Less Wright在ImageNette上进行了测试,取得了相当不错的效果(注:ImageNette是从ImageNet上抽取的包含10类图像的子集)。在5个epoch后,RAdam已经将准确率快速收敛到86%。
如果你以为RAdam只能处理较小数据集上的训练,或者只有在CNN上有较好的表现就大错特错了。即使大道有几十亿个单词的数据集的LSTM模型,RAdam依然有比Adam更好的表现。
总之,RAdam有望提供更好的收敛性、训练稳定性,以及几乎对所有AI应用都用更好的通用性。
RAdam VS Adam的更多相关文章
- Unity Adam特性整理
1.Wind 小工具,一个绘制箭头Gizmos的脚本 2.TubeLight柱形光照 蛮NB的技术,实现动态柱状光照,但相机必须挂上PostProcessing 默认场景拖出来之后是这样的,然后给相机 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- 深度学习优化算法Momentum RMSprop Adam
一.Momentum 1. 计算dw.db. 2. 定义v_db.v_dw \[ v_{dw}=\beta v_{dw}+(1-\beta)dw \] \[ v_{db}=\beta v_{db}+( ...
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 【深度学习】深入理解优化器Optimizer算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- Heroku创始人Adam Wiggins发布十二要素应用宣言
Heroku是业内知名的云应用平台,从对外提供服务以来,他们已经有上百万应用的托管和运营经验.前不久,创始人Adam Wiggins根据这些经验,发布了一个“十二要素应用宣言(The Twelve-F ...
- TensorFlow之DNN(二):全连接神经网络的加速技巧(Xavier初始化、Adam、Batch Norm、学习率衰减与梯度截断)
在上一篇博客<TensorFlow之DNN(一):构建“裸机版”全连接神经网络>中,我整理了一个用TensorFlow实现的简单全连接神经网络模型,没有运用加速技巧(小批量梯度下降不算哦) ...
- (五) Keras Adam优化器以及CNN应用于手写识别
视频学习来源 https://www.bilibili.com/video/av40787141?from=search&seid=17003307842787199553 笔记 Adam,常 ...
- 【DeepLearning】优化算法:SGD、GD、mini-batch GD、Moment、RMSprob、Adam
优化算法 1 GD/SGD/mini-batch GD GD:Gradient Descent,就是传统意义上的梯度下降,也叫batch GD. SGD:随机梯度下降.一次只随机选择一个样本进行训练和 ...
随机推荐
- 掌握算法&数据结构的正确方式
- 【转载】 C#中ArrayList使用GetRange方法获取某一段集合数据
在C#的编程开发中,ArrayList集合是一个常用的非泛型类集合,可以使用GetRange方法来获取集合中指定索引位置开始的一整段集合数据组成一个新的集合,GetRange方法的签名为virtual ...
- vim巧妙用法
1. 块复制 按ctrl+v键,编辑框最下方将出现"可视 块"字样 使用方向键移动光标,选择矩形区域内的文字 y 键复制文本: d 键剪切文本:p 键粘贴文本 按shift+v键, ...
- RabbitMQ基本概念(一)-RabbitMQ的优劣势及产生背景
本篇并没有直接讲到技术,例如没有先写个Helloword.我想在选择了解或者学习一门技术之前先要明白为什么要现在这个技术而不是其他的,以免到最后发现自己学错了.同时如果已经确定就是他,最好先要了解下技 ...
- Django之DRF源码分析(四)---频率认证组件
核心源码 def check_throttles(self, request): """ Check if request should be throttled. Ra ...
- 浅谈flask源码之请求过程
更新时间:2018年07月26日 09:51:36 作者:Dear. 我要评论 这篇文章主要介绍了浅谈flask源码之请求过程,小编觉得挺不错的,现在分享给大家,也给大家做个参考.一起跟随 ...
- 模型融合---为什么说bagging是减少variance,而boosting是减少bias?
1.bagging减少variance Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均.由于子样本集的相似性以及使用的是同种模型,因此各模型有近似相等的bias和var ...
- python中pop()与split()的用法
imglist = ['11.jpg','12.jpg','13.jpg','14.jpg','2.jpg','1.jpg',] print(str(imglist)) a = str(imglist ...
- Java8新特性(1)—— Stream集合运算流入门学习
废话,写在前面 好久没写博客了,懒了,以后自觉写写博客,每周两三篇吧! 简单记录自己的学习经历,算是对自己的一点小小的督促! Java8的新特性很多,比如流处理在工作中看到很多的地方都在用,是时候扔掉 ...
- spring Boot + MyBatis + Maven 项目,日志开启打印 sql
在 spring Boot + MyBatis + Maven 项目中,日志开启打印 sql 的最简单方法,就是在文件 application.properties 中新增: logging.leve ...