Resouce Pool的理解
本篇文章从现象到本质再到具象去理解 , 从理论到实战再到源码回顾去深化。
1.在开发中,无处不在的池。
eg
网络通信连接池:
HttpClient连接池
HttpClient通过PoolingHttpClientConnectionManager类来管理连接池
数据库连接池:Java中常用的数据库连接池有:
DBCP 、C3P0、BoneCP、Proxool、DBPool、XAPool、Primrose、SmartPool、MiniConnectionPoolManager及Druid
端上的连接池
APP中连接池 anroid binder连接池,OKhttp
线程池
java线程池ThreadPoolExecutor,Tomcat线程池
内存池
JVM中 常量池
对象池
以上池化技术共同点实现的原理都是类似的,通过对连接或线程的复用,并对复用的数量、时间等进行控制,从而使系统的性能和资源消耗达到最优的状态。实际项目中,我们可以考虑使用池化技术来解决程序性能的瓶颈
2.对于共享资源,有一个很著名的设计模式:资源池(Resource Pool)
引自原文链接:http://sourcemaking.com/design_patterns/object_pool
Intent
Object pooling can offer a significant performance boost; it is most effective in situations where the cost of initializing a class instance is high, the rate of instantiation of a class is high, and the number of instantiations in use at any one time is low.
Problem
Object pools (otherwise known as resource pools) are used to manage the object caching. A client with access to a Object pool can avoid creating a new Objects by simply asking the pool for one that has already been instantiated instead. Generally the pool will be a growing pool, i.e. the pool itself will create new objects if the pool is empty, or we can have a pool, which restricts the number of objects created.
It is desirable to keep all Reusable objects that are not currently in use in the same object pool so that they can be managed by one coherent policy. To achieve this, the Reusable Pool class is designed to be a singleton class.
Discussion
The Object Pool lets others "check out" objects from its pool, when those objects are no longer needed by their processes, they are returned to the pool in order to be reused.
However, we don't want a process to have to wait for a particular object to be released, so the Object Pool also instantiates new objects as they are required, but must also implement a facility to clean up unused objects periodically.
Structure
The general idea for the Connection Pool pattern is that if instances of a class can be reused, you avoid creating instances of the class by reusing them.

Reusable- Instances of classes in this role collaborate with other objects for a limited amount of time, then they are no longer needed for that collaboration.Client- Instances of classes in this role use Reusable objects.ReusablePool- Instances of classes in this role manage Reusable objects for use by Client objects.
Usually, it is desirable to keep all Reusable objects that are not currently in use in the same object pool so that they can be managed by one coherent policy. To achieve this, theReusablePool class is designed to be a singleton class. Its constructor(s) are private, which forces other classes to call its getInstance method to get the one instance of the ReusablePoolclass.
A Client object calls a ReusablePool object's acquireReusable method when it needs aReusable object. A ReusablePool object maintains a collection of Reusable objects. It uses the collection of Reusable objects to contain a pool of Reusable objects that are not currently in use.
If there are any Reusable objects in the pool when the acquireReusable method is called, it removes a Reusable object from the pool and returns it. If the pool is empty, then theacquireReusable method creates a Reusable object if it can. If the acquireReusable method cannot create a new Reusable object, then it waits until a Reusable object is returned to the collection.
Client objects pass a Reusable object to a ReusablePool object's releaseReusable method when they are finished with the object. The releaseReusable method returns a Reusableobject to the pool of Reusable objects that are not in use.
In many applications of the Object Pool pattern, there are reasons for limiting the total number of Reusable objects that may exist. In such cases, the ReusablePool object that creates Reusable objects is responsible for not creating more than a specified maximum number of Reusable objects. If ReusablePool objects are responsible for limiting the number of objects they will create, then the ReusablePool class will have a method for specifying the maximum number of objects to be created. That method is indicated in the above diagram as setMaxPoolSize.
Example
Do you like bowling? If you do, you probably know that you should change your shoes when you getting the bowling club. Shoe shelf is wonderful example of Object Pool. Once you want to play, you'll get your pair (aquireReusable) from it. After the game, you'll return shoes back to the shelf (releaseReusable).
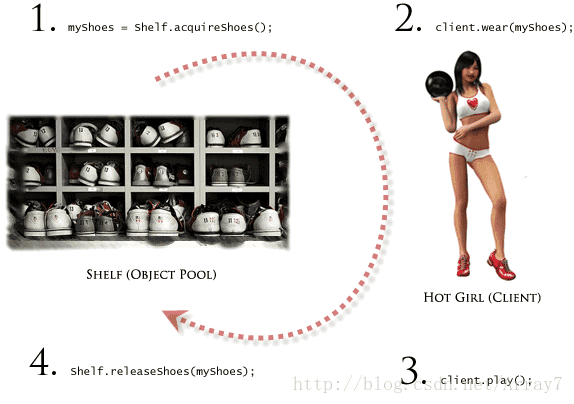
Check list
- Create
ObjectPoolclass with private array ofObjects inside - Create
acquareandreleasemethods in ObjectPool class - Make sure that your ObjectPool is Singleton
Rules of thumb
- The Factory Method pattern can be used to encapsulate the creation logic for objects. However, it does not manage them after their creation, the object pool pattern keeps track of the objects it creates.
- Object Pools are usually implemented as Singletons.
3.资源池实例 :资源池的简单实现
public interface ICommonPool<T> {
T borrowObject() throws Exception;
void returnObject(T object) throws Exception;
}
/**
* 对象池配置
*/
public class PoolConfig { // 池中最大对象
private int maxTotal = 8;
//初始化对象数
private int minTotal = 0; public int getMaxTotal() {
return maxTotal;
} public void setMaxTotal(int maxTotal) {
this.maxTotal = maxTotal;
} public int getMinTotal() {
return minTotal;
} public void setMinTotal(int minTotal) {
this.minTotal = minTotal;
}
}
package com.shoshana.poolDemo.commonPool; /**
* 负责创建、销毁对象
* @param <T>
*/
public interface PoolFactory<T> { /**
* 创建对象
* @return
*/
T makeObject(); /**
* 销毁对象
*/
void destroyObject(T t);
}
import java.util.concurrent.LinkedBlockingQueue;
public class BaseCommonPool<T> implements ICommonPool<T> {
private LinkedBlockingQueue<T> pool;
private PoolConfig poolConfig;
private PoolFactory<T> poolFactory;
public BaseCommonPool(PoolConfig poolConfig, PoolFactory<T> poolFactory) {
this.poolConfig = poolConfig;
this.poolFactory = poolFactory;
initCommonPool();
}
private void initCommonPool() {
pool = new LinkedBlockingQueue<T>(poolConfig.getMaxTotal());
while (poolConfig.getMinTotal() > pool.size()) {
T obj = poolFactory.makeObject();
pool.offer(obj);
}
}
@Override
public T borrowObject() throws Exception {
T obj = pool.poll();
if (obj != null) {
return obj;
}
return poolFactory.makeObject();
}
@Override
public void returnObject(T object) throws Exception {
if (!pool.offer(object)) {
poolFactory.destroyObject(object);
}
}
}
4.资源池总结:
4.1 什么是资源池?
eg:
对象池化的基本思路是:将用过的对象保存起来,等下一次需要这种对象的时候,再拿出来重复使用,从而在一定程度上减少频繁创建对象所造成的开销。用于充当保存对象的“容器”的对象,被称为“对象池”(Object Pool,或简称Pool)。
数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。我们可以通过设定连接池最大连接数来防止系统无尽的与数据库连接。更为重要的是我们可以通过连接池的管理机制监视数据库的连接的数量﹑使用情况,为系统开发﹑测试及性能调整提供依据。
4.2 为什么要引入资源池技术:该模式正是为了解决资源的频繁分配﹑释放所造成的问题
恰当地使用对象池化技术,可以有效地减少对象生成和初始化时的消耗,提高系统的运行效率。
4.3 什么场景适合,不适合池化:
并非所有对象都适合拿来池化——因为维护对象池也要造成一定开销。对生成时开销不大的对象进行池化,反而可能会出现“维护对象池的开销”大于“生成新对象的开销”
什么场景不适合?
Dr. Cliff Click在JavaOne 2003上发表的《Performance Myths Exposed》中,给出了一组其它条件都相同时,使用与不使用对象池化技术的实际性能的比较结果。他的实测结果表明:
对于类似Point这样的轻量级对象,进行池化处理后,性能反而下降,因此不宜池化;
对于类似Hashtable这样的中量级对象,进行池化处理后,性能基本不变,一般不必池化(池化会使代码变复杂,增大维护的难度);
对于类似JPanel这样的重量级对象,进行池化处理后,性能有所上升,可以考虑池化。
对于有状态和无状态的对象重复使用前的不同处理:
对于没有状态的对象(例如String),在重复使用之前,无需进行任何处理;
对于有状态的对象(例如StringBuffer),在重复使用之前,就需要把它们恢复到等同于刚刚生成时的状态。
什么场景适合?
只在重复生成某种对象的操作成为影响性能的关键因素的时候,才适合进行对象池化。如果进行池化所能带来的性能提高并不重要的话,还是不采用对象池化技术,以保持代码的简明,而使用更好的硬件和更棒的虚拟机来提高性能为佳。
eg
当获取资源的成本较高的时候
当请求资源的频率很高且使用资源总数较低的时候
当面对性能问题,涉及到处理时间延迟的时候
4.4 资源池关键问题分析
并发问题
为了使连接管理服务具有最大的通用性,必须考虑多线程环境,即并发问题。这个问题相对比较好解决,因为各个语言自身提供了对并发管理的支持像java,c#等等,使用synchronized(java)lock(C#)关键字即可确保线程是同步的。使用方法可以参考,相关文献。
事务处理
我们知道,事务具有原子性,此时要求对数据库的操作符合“ALL-ALL-NOTHING”原则,即对于一组SQL语句要么全做,要么全不做。
我们知道当2个线程公用一个连接Connection对象,而且各自都有自己的事务要处理时候,对于连接池是一个很头疼的问题,因为即使Connection类提供了相应的事务支持,可是我们仍然不能确定那个数据库操作是对应那个事务的,这是由于我们有2个线程都在进行事务操作而引起的。为此我们可以使用每一个事务独占一个连接来实现,虽然这种方法有点浪费连接池资源但是可以大大降低事务管理的复杂性。
连接池的分配与释放
连接池的分配与释放,对系统的性能有很大的影响。合理的分配与释放,可以提高连接的复用度,从而降低建立新连接的开销,同时还可以加快用户的访问速度。
对于连接的管理可使用一个List。即把已经创建的连接都放入List中去统一管理。每当用户请求一个连接时,系统检查这个List中有没有可以分配的连接。如果有就把那个最合适的连接分配给他(如何能找到最合适的连接文章将在关键议题中指出);如果没有就抛出一个异常给用户,List中连接是否可以被分配由一个线程来专门管理捎后我会介绍这个线程的具体实现。
连接池的配置与维护
连接池中到底应该放置多少连接,才能使系统的性能最佳?系统可采取设置最小连接数(minConnection)和最大连接数(maxConnection)等参数来控制连接池中的连接。比方说,最小连接数是系统启动时连接池所创建的连接数。如果创建过多,则系统启动就慢,但创建后系统的响应速度会很快;如果创建过少,则系统启动的很快,响应起来却慢。这样,可以在开发时,设置较小的最小连接数,开发起来会快,而在系统实际使用时设置较大的,因为这样对访问客户来说速度会快些。最大连接数是连接池中允许连接的最大数目,具体设置多少,要看系统的访问量,可通过软件需求上得到。
如何确保连接池中的最小连接数呢?有动态和静态两种策略。动态即每隔一定时间就对连接池进行检测,如果发现连接数量小于最小连接数,则补充相应数量的新连接,以保证连接池的正常运转。静态是发现空闲连接不够时再去检查。
关键议题
- 引用记数
在分配、释放策略对于有效复用连接非常重要,我们采用的方法也是采用了一个很有名的设计模式:Reference Counting(引用记数)。该模式在复用资源方面用的非常广泛,我们把该方法运用到对于连接的分配释放上。每一个数据库连接,保留一个引用记数,用来记录该连接的使用者的个数。具体的实现上,我们对Connection类进行进一步包装来实现引用记数。被包装的Connection类我们提供2个方法来实现引用记数的操作,一个是Repeat(被分配出去)Remove(被释放回来);然后利用RepeatNow属性来确定当前被引用多少,具体是哪个用户引用了该连接将在连接池中登记;最后提供IsRepeat属性来确定该连接是否可以使用引用记数技术。一旦一个连接被分配出去,那么就会对该连接的申请者进行登记,并且增加引用记数,当被释放回来时候就删除他已经登记的信息,同时减少一次引用记数。
这样做有一个很大的好处,使得我们可以高效的使用连接,因为一旦所有连接都被分配出去,我们就可以根据相应的策略从使用池中挑选出一个已经正在使用的连接用来复用,而不是随意拿出一个连接去复用。
4.5 资源池的优点
连接池的主要优点有以下三个方面。
第一、减少创建时间。连接池中的连接是已准备好的、可重复使用的,获取后可以直接访问数据库,因此减少了连接创建的次数和时间。
第二、简化的编程模式。当使用连接池时,每一个单独的线程能够像创建一个自己的JDBC连接一样操作,允许用户直接使用JDBC编程技术。
第三、控制资源的使用。如果不使用连接池,每次访问数据库都需要创建一个连接,这样系统的稳定性受系统连接需求影响很大,很容易产生资源浪费和高负载异常。连接池能够使性能最大化,将资源利用控制在一定的水平之下。连接池能控制池中的连接数量,增强了系统在大量用户应用时的稳定性。
4.6 资源池的工作原理
连接池的工作原理主要由三部分组成,分别为连接池的建立、连接池中连接的使用管理、连接池的关闭。
第一、连接池的建立。一般在系统初始化时,连接池会根据系统配置建立,并在池中创建了几个连接对象,以便使用时能从连接池中获取。连接池中的连接不能随意创建和关闭,这样避免了连接随意建立和关闭造成的系统开销。Java中提供了很多容器类可以方便的构建连接池,例如Vector、Stack等。
第二、连接池的管理。连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其管理策略是:
当客户请求数据库连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户。
当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过就从连接池中删除该连接,否则保留为其他客户服务。
该策略保证了数据库连接的有效复用,避免频繁的建立、释放连接所带来的系统资源开销。
第三、连接池的关闭。当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反。
5. 友链:有兴趣可以动手写各个连接池的实现,文章就不作扩展了。
资源池-数据库连接池简单实现-JAVA版本 https://www.jianshu.com/p/381c86bdbff6
java设计思想-池化-手写数据库连接池 https://blog.csdn.net/qq_16038125/article/details/80180941
对象池的JAVA实现
资源对象的池化, java极简实现,close资源时,自动回收 https://www.cnblogs.com/piepie/p/10498953.html
6.后记,看完资源池,底层原理是不是很简单? 再去看各种资源池的具体实现就非常容易理解了。
Resouce Pool的理解的更多相关文章
- 数据库连接池dataesoruce pool深入理解
8.数据库连接池的connection都是长连接的,以方便多次调用,多人连续使用.dataSourcePool9.数据库连接池中的连接,是在你用完之后,返回给数据库连接池的,并不是close()掉,而 ...
- shoshana-技术文集
20190422 全球最厉害的 14 位程序员,请收下我的膝 20190423 观察者模式(Observer)和发布(Publish/订阅模式(Subscribe) 2019042 ...
- Apache Commons Pool 故事一则
Apache Commons Pool 故事一则 最近工作中遇到一个由于对commons-pool的使用不当而引发的问题,习得正确的使用姿势后,写下这个简单的故事,帮助理解Apache Commons ...
- 数据库连接池和connection的理解
数据库连接池Data Source Pool的理解 1.数据库连接池允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个连接,避免了每个方法里new connection的耗费资源和时间. ...
- Apache Commons Pool 故事一则 专题
Apache Commons Pool 故事一则 最近工作中遇到一个由于对commons-pool的使用不当而引发的问题,习得正确的使用姿势后,写下这个简单的故事,帮助理解Apache Commons ...
- 1-MySQL DBA笔记-理解MySQL
第一部分 入门篇 本篇首先介绍MySQL的应用领域.基础架构和版本,然后介绍MySQL的基础知识,如查询的执行过程.权限机制.连接.存储引擎,最后阐述一些基础概念. 第1章 理解MySQL 本章将介绍 ...
- commons-pool 解析
首先抛出个常见的长连接问题: 1 都知道连接MySQL的应用中大多会使用框架例如 c3p0 ,dbcp proxool 等来管理数据库连接池. 数据库连接池毫无疑问都是采用长连接方式. 那么MySQ ...
- Spark源码分析 -- SchedulableBuilder
SchedulableBuilder就是对Scheduleable tree的封装, 在Pool层面(中间节点), 完成对TaskSet的调度(FIFO, FAIR) 在TaskSetManager ...
- Ambari和YARN的Capacity调度器,安装过程
用Spark测试YARN的资源池,测试过程中发现很多时候爆资源不够: 于是添加机器,专门用于跑spark:首先是ssh不通,原来错把71的id_psa.put文件拷贝到64上面:后来ssh通了,amb ...
随机推荐
- 第04组alpha冲刺(2/4)
队名:斗地组 组长博客:地址 作业博客:Alpha冲刺(2/4) 各组员情况 林涛(组长) 过去两天完成了哪些任务: 1.收集各个组员的进度 2.写博客 展示GitHub当日代码/文档签入记录: 接下 ...
- java基础之 clone
参考文档:深拷贝&浅拷贝:http://blog.csdn.net/cws1214/article/details/52193341 克隆的分类: (1)浅克隆(shallow clone) ...
- JS字符串转换为JSON的四种方法
转自:https://www.cnblogs.com/hgmyz/p/7451461.html 1.jQuery插件支持的转换方式: 示例: $.parseJSON( jsonstr ); //jQ ...
- Gamma阶段第二次scrum meeting
每日任务内容 队员 昨日完成任务 明日要完成的任务 张圆宁 #91 用户体验与优化https://github.com/rRetr0Git/rateMyCourse/issues/91(持续完成) # ...
- systemctl enable rc-local.service error
/******************************************************************************* * systemctl enable ...
- dd命令笔记
dd命令 用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换 参数 if=FILE 指定输入源文件, 缺省为标准输入, < if=input file > iflag=FLAGS 指 ...
- Linux的tmpfs和ramfs
tmpfs tmpfs是一种虚拟内存文件系统, 它的存储空间在VM里面,现在大多数操作系统都采用了虚拟内存管理机制, VM(Virtual Memory) 是由Linux内核里面的VM子系统管理. V ...
- 【FPGA】always (*) 后代码全部显示注释字体的颜色之解决方法
2015年08月26日 09:44:05 风雨也无晴 阅读数:1289 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/scottly1/art ...
- [转]Oracle左连接、右连接、全外连接以及(+)号用法
原文地址:https://www.cnblogs.com/hehaiyang/p/4745897.html 阅读目录 1.准备工作 2.左外连接(LEFT OUTER JOIN/ LEFT JOIN) ...
- CentOS7静默安装Oracle 18g数据库(无图形化界面)
说明: 因为是静默安装,所以我们不需要安装图形界面 准备:下载Oracle软件 官方网站:http://www.oracle.com/technetwork/database/enterprise-e ...