爬取 豆瓣电影Top250
目标
学习爬虫,爬豆瓣榜单,获取爬取静态页面信息的能力
豆瓣电影 Top 250 https://movie.douban.com/top250
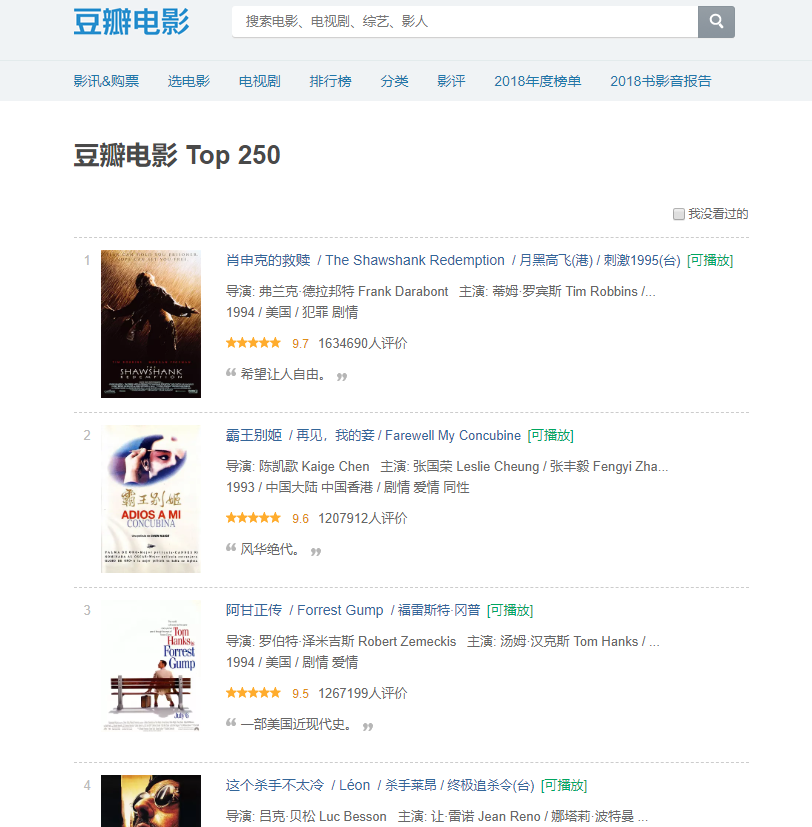
代码
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常' if __name__ == '__main__':
i = 0
urls = ['https://movie.douban.com/top250?start='+str(n)+'&filter=' for n in range(0,250,25)]
for url in urls:
r = getHTMLText(url)
soup = BeautifulSoup(r,'html.parser')
titles = soup.select('div.hd a')
rates = soup.select('span.rating_num')
pics = soup.select('img[width="100"]')
for title,rate,pic in zip(titles,rates,pics):
data={'title':list(title.stripped_strings),
'rate':rate.get_text(),
'pic':pic.get('src')}
i+=1
fileName=str(i)+'_'+data['title'][0]+' '+data['rate']+'分.jpg'
pic1 = requests.get(data['pic'])
with open('G:\\test\\'+fileName,'wb') as photo:
photo.write(pic1.content)
print(data)
爬取结果
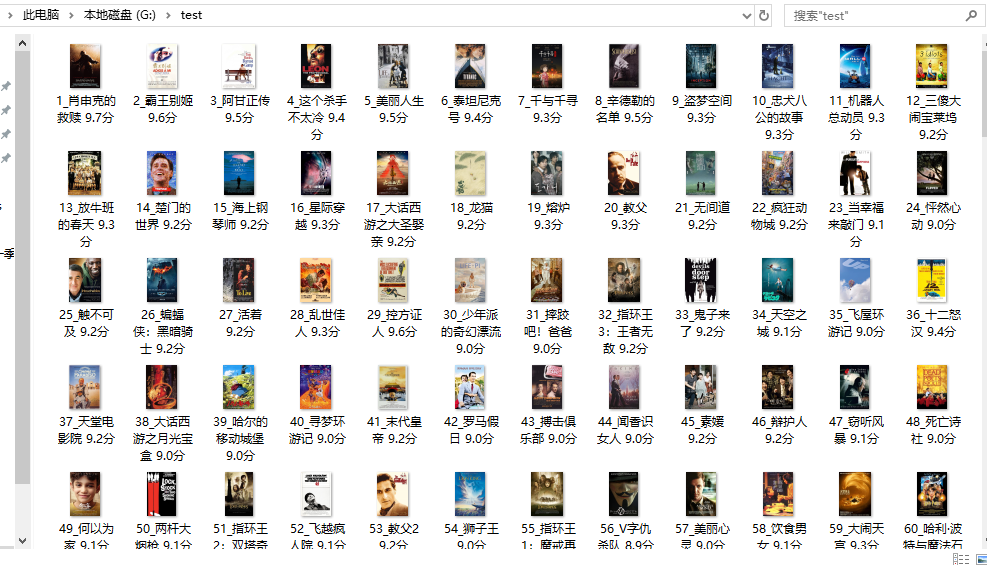
爬取 豆瓣电影Top250的更多相关文章
- urllib+BeautifulSoup无登录模式爬取豆瓣电影Top250
对于简单的爬虫任务,尤其对于初学者,urllib+BeautifulSoup足以满足大部分的任务. 1.urllib是Python3自带的库,不需要安装,但是BeautifulSoup却是需要安装的. ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- Scrapy爬虫(4)爬取豆瓣电影Top250图片
在用Python的urllib和BeautifulSoup写过了很多爬虫之后,本人决定尝试著名的Python爬虫框架--Scrapy. 本次分享将详细讲述如何利用Scrapy来下载豆瓣电影To ...
随机推荐
- .Net反射-两种方式获取Enum中的值
public enum EJobType { 客服 = , 业务员 = , 财务 = , 经理 = } Type jobType = typeof(EJobType); 方式1: Array enum ...
- 清北学堂(2019 5 2) part 5
今天讲图论,顺便搞一搞之前没弄完的前向星dij 1.图的基本概念(课件原话): G (图)= (V(点); E(边)) 一般来说,图的存储难度主要在记录边的信息 无向图的存储中,只需要将一条无向边拆成 ...
- [LeetCode] 307. Range Sum Query - Mutable 区域和检索 - 可变
Given an integer array nums, find the sum of the elements between indices i and j (i ≤ j), inclusive ...
- 关于Windows自动化卸载软件的思路
思路 关于控制面板“卸载”关联到的exe是这样的: 注册表:HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Uninstall ...
- 官方入门教程和文档 | Visual Studio
Visual Studio 2017 概述 | Microsoft Docs(直接教你用vs) https://docs.microsoft.com/zh-cn/visualstudio/ide/vi ...
- 第02组 Alpha冲刺(6/6)
队名:無駄無駄 组长博客 作业博客 组员情况 张越洋 过去两天完成了哪些任务 准备"Alpha事后诸葛亮" 提交记录(全组共用) 接下来的计划 完善接口文档 调动组员积极性 还剩下 ...
- RICOH C4502彩色打印机取消双面打印功能
参考下面步骤:
- [数据库] SQL 语法之基础篇
一.什么是 SQL ? SQL 是 Structured Query Language(结构化查询语言)的缩写,是一种专门用来与数据库沟通的语言.与其他语言(如英语或 C.C++.Java 这样的编程 ...
- SDK-基于Windows环境搭建
SDK安装配置 前言:相信很多小伙伴还不会搭SDK,近日一位前同事询问我SDK怎么搭建了?不妨看看吧,小编是基于appium. 1.下载SDK:http://tools.android-studio. ...
- SQLserver 存储过程游标使用
ALTER PROCEDURE [dbo].[p_DeleteStretchData] ) , ) AS BEGIN ) ) declare @stretch_cursor cursor -- 声明游 ...