Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient报错,问题排查
背景
最近在整合pyspark与hive,新安装spark-2.3.3以客户端的方式访问hive数据,运行方式使用spark on yarn,但是在配置spark读取hive数据的时候,这里直接把hive下的hive-site.xml复制到spark目录下,启动了一次spark,上面的问题就出现了。
网上的说法:
hive元数据问题,需要重新初始化hive的元数据
但是这个方法肯定不适合我,因为仓库里的表不能受影响,上千张表呢,如果初始化了,所有表都要重新创建。
排查过程
* 首先查看服务器上/tmp/${user}/hive.log文件,这个是公司服务器当时配置的详细的hive执行日志。
在日志中,有一段报错:
2019-07-06T10:01:53,737 ERROR [370c0a81-c922-4c61-8315-264c39b372c3 main] metastore.RetryingHMSHandler: MetaException(message:Hive Schema version 3.1.0 does not match metastore's schema version 1.2.0 Metastore is not upgraded or corrupt)
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:9063)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:9027)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
这里的意思是,hive的版本是3.1.0,但是元数据中的版本信息是1.2.0,因此报错。
* 到hive的元数据库里查了下version表里的数据,确实版本是1.2.0
问题原因
这里猜测,spark在读取hive元数据的时候,因为spark是直接从官网上下载的,可能官网上的spark是用hive1.2.0版本编译的,所以,它默认使用的1.2.0,导致在启动的时候,修改了hive的元数据
但是具体的原因还不知道
下面会拿官网上的spark源码手动编译测试一下
解决办法
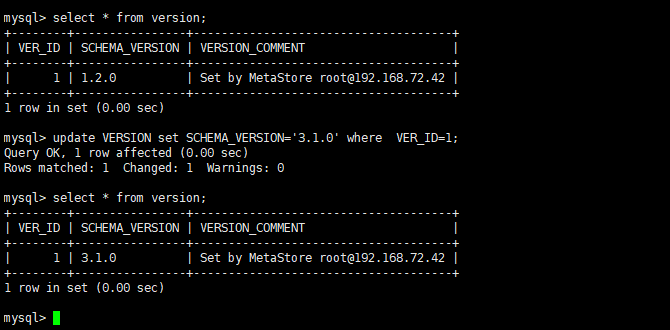
- 直接修改version表的数据
select * from version;
update VERSION set SCHEMA_VERSION='2.1.1' where VER_ID=1;
2、在hvie-site.xml中关闭版本验证
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
深入研究
在spark官网上查看了相关的资料,发现,在官网上下载的spark安装包,默认编译的hive版本是1.2.1的,所以每次启动spark的时候,会检查hive的版本。如果采用hive的默认配置,如果不一样,
就会修改version

一开始尝试着下载spark源码重新编译spark安装包,编译执行hive的版本为3.1.1,但是,发现每次指定hive的版本,maven下载依赖的时候,都会报错。
报错信息如下:
后来想了个折中的办法,spark还是使用原始版本,但是修改一下hive-site.xml文件。
注意:这里修改的是spark的conf下的hive-site.xml,原始的hive里的不需要修改
<property>
<name>hive.metastore.schema.verification</name>
<value>true</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<property>
<name>hive.metastore.schema.verification.record.version</name>
<value>false</value>
<description>
When true the current MS version is recorded in the VERSION table. If this is disabled and verification is
enabled the MS will be unusable.
</description>
</property>
这两个配置,hive.metastore.schema.verification如果设置为true,那么每次启动hive或者spark的时候,都会检查hive的版本。为false,则会告警
hive.metastore.schema.verification.record.version如果设置为true,每次启动spark的时候,如果检查了hive的版本和spark编译的版本不一致,那么就会修改hive的元数据
这里的修改需要设置hive.metastore.schema.verification=false 且hive.metastore.schema.verification.record.version=false
如过这两个都为true,那么spark会修改hive元数据
如果hive.metastore.schema.verification=true,并且hive.metastore.schema.verification.record.version=false,这时候启动spark就会报错:
Caused by: MetaException(message:Hive Schema version 1.2.0 does not match metastore's schema version 3.1.0 Metastore is not upgraded or corrupt)
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:6679)
at org.apache.hadoop.hive.metastore.ObjectStore.verifySchema(ObjectStore.java:6645)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
如果设置hive.metastore.schema.verification=false 且hive.metastore.schema.verification.record.version=true,spark还是会修改hive的元数据


所以,只要设置hive.metastore.schema.verification.record.version=false就可以了,但是为了保险起见,我两个都设置成false了
Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient报错,问题排查的更多相关文章
- Hive之FAILED: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient异常
一.场景 Hive启动不报错,当使用show functions;或create table...时报:FAILED: SemanticException org.apache.hadoop.hive ...
- hive Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
Exception in thread "main" java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata. ...
- Hive2:Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
[root@node1 ~]# hive which: no hbase in (/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bi ...
- hive 2以上版本启动异常 Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
hive2.0以上的版本启动时 抛出 “Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreCli ...
- Have启动报错:java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
错误日志如下: [hadoop@master hive1.0.0]$ bin/hive Logging initialized using configuration in file:/opt/mod ...
- Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
1.今天在进行hive测试的时候,发现hive一直进不去,并且报了这个错误. Unable to instantiate org.apache.hadoop.hive.ql.metadata.Sess ...
- Hive启动后show tables报错:Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
错误详情: FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive ...
- Hive 报错:java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
在配置好hive后启动报错信息如下: [walloce@bigdata-study- hive--cdh5.3.6]$ bin/hive Logging initialized using confi ...
- java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
1.启动hive的时候出现这个问题,报错如下所示: [hadoop@slaver1 conf]$ hive Logging initialized -cdh5.-cdh5.3.6.jar!/hive- ...
随机推荐
- 剑指offer:和为S的连续正数序列
题目描述: 小明很喜欢数学,有一天他在做数学作业时,要求计算出9~16的和,他马上就写出了正确答案是100.但是他并不满足于此,他在想究竟有多少种连续的正数序列的和为100(至少包括两个数).没多久, ...
- SpringBoot dev-tools vjtools dozer热启动类加载器不相同问题
最近使用唯品会的vjtools的BeanMapper进行对象的深度克隆转换DTO/VO这种操作,Spring Boot的dev-tools热启动,需要把vjtools和dozer包都放到spring- ...
- Phpoffice 已经弃用
Package phpoffice/phpexcel is abandoned, you should avoid using it. Use phpoffice/phpspreadsheet i ...
- IDEA版本控制忽略文件或目录
写在前面 废话不多说了, 新创建了个helloworld, 见图: 这谁受得了啊 修改配置 在上图红框内部的后面添加: *.iml;*.idea;*.gitignore;*.sh;*.classpat ...
- python 上下文管理器contextlib.ContextManager
1 模块简介 在数年前,Python 2.5 加入了一个非常特殊的关键字,就是with.with语句允许开发者创建上下文管理器.什么是上下文管理器?上下文管理器就是允许你可以自动地开始和结束一些事情. ...
- phpexcel中文手册(转)
首先到phpexcel官网上下载最新的phpexcel类,下周解压缩一个classes文件夹,里面包含了PHPExcel.php和PHPExcel的文件夹,这个类文件和文件夹是我们需要的,把class ...
- [LeetCode] 555. Split Concatenated Strings 分割串联字符串
Given a list of strings, you could concatenate these strings together into a loop, where for each st ...
- java面试 (六)
1 String.split(String regex), 传入的参数是正则表达式,有一些特殊字符(比如.[]()\| 等)需要转义. 2 关于枚举类型,一般用作常量,理想情况下,枚举中的属性字段是 ...
- python爬虫2
学习任务 获取去哪儿网的出发地列表 获取旅游景点列表 获取景点产品列表 存储数据 1 获取出发地站点 (1)访问touch.qunar.com (2)按F12,单击自由行,在自由行页面点击搜索框 (3 ...
- ATSC/DVB/ISDB三大标准比较
一.引言 众所周知,模拟电视有NTSC.PAL和SECAM三种标准.目前,数字电视也陷入这种局面,美国.欧洲和日本各自形成三种不同的数字电视标准.美国的标准是ATSC(Advanced Televi ...