关于python的一次性能调优过程
问题
这两天在公司帮老大写一个程序功能,要求抓取从elasticsearch和kibana服务器上返回的数据,统计所有hits的数据字段ret_code为0的hit,并计算其占有率等一些功能。
功能倒是写完交差和合并主分支了,但是后来试运行却发现统计完所有response的数据并且发送报警邮件的整个过程居然要两个小时之久!我想虽然python的性能是比不上java但是也没有这么差劲吧。后来调试发现,原来的程序运行只有六七分钟,我开始怀疑我写的代码巨烂。后来经过调试比对,发现并不是我加进去的代码有问题,而是之前同事写的代码欠缺一部分性能和扩展性的考虑。以下是我的分析过程。
分析过程
打开pycharm run菜单下的profile选项,利用profile工具对程序运行的性能指标进行计算和分析。
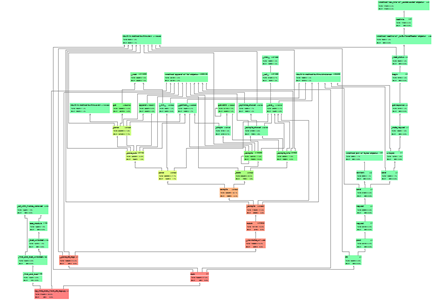
得到的函数调用时间占比图的大体结果如下,我们可以得到每个函数(方框)运行的时间及其在它所调用的其他函数。红色即代表该函数占用整体运行时间的比率太高,说明该函数是整个程序运行的性能瓶颈。反而颜色越绿占比就越小。
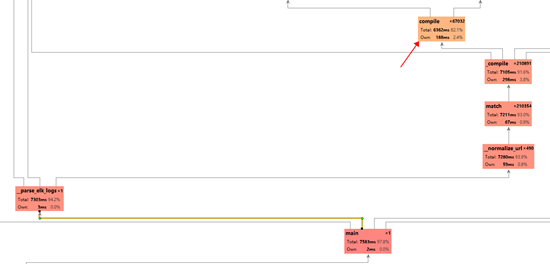
我们放大其中红色的部分,我们可以发现所调用的我们自己写的函数__normalize_url函数占用了大部分的运行时间。从函数名知道这是一个对url正则化的函数,其中用到了re模块的match和_compile函数,而最终程序所浪费的时间的关键就在于最后的re中的compile函数。
def __normalize_url(url):norm_url = re.sub('\?.*$', '', url) if '?' in url else urlfor mapping in url_normalization_mappings:if re.match(mapping[0], norm_url):return mapping[1]return norm_url
这段代码调用的re.compile()函数看似没有问题,但其中存在一些不足。我们点开re模块的match函数的实现。是对pattern正则字符串进行编译成正则化对象,再对目标string进行匹配。
def match(pattern, string, flags=0):"""Try to apply the pattern at the start of the string, returninga match object, or None if no match was found."""return _compile(pattern, flags).match(string)
再来看_compile函数
_cache = {}_pattern_type = type(sre_compile.compile("", 0))_MAXCACHE = 512def _compile(pattern, flags):# internal: compile patterntry:p, loc = _cache[type(pattern), pattern, flags]if loc is None or loc == _locale.setlocale(_locale.LC_CTYPE):return pexcept KeyError:passif isinstance(pattern, _pattern_type):if flags:raise ValueError("cannot process flags argument with a compiled pattern")return patternif not sre_compile.isstring(pattern):raise TypeError("first argument must be string or compiled pattern")p = sre_compile.compile(pattern, flags)if not (flags & DEBUG):if len(_cache) >= _MAXCACHE:_cache.clear()if p.flags & LOCALE:if not _locale:return ploc = _locale.setlocale(_locale.LC_CTYPE)else:loc = None_cache[type(pattern), pattern, flags] = p, locreturn p
我们发现,_compile函数会设置一个缓存,保存编译过的正则化对象,这样以后我们再想对相同的正则规则字符串进行编译时就可以直接取该对象而不用花时间来重复编译它。而这个缓存对象的个数限制就为_MAXCACHE 即原代码中设置的512。
而原来我们写的程序要匹配的url有496个,而经过后来接口的增加,url增加到了516个,正好突破了缓存的个数限制!然后缓存居然清空了!(如下)
if len(_cache) >= _MAXCACHE:_cache.clear()
也就是说,当我们匹配每一个url时,如果缓存溢出了都要重新编译所有的正则化对象,这无形中浪费了大量的时间。更何况我们要匹配接近十万条的url,这也难怪要要花费两个多小时的时间来运行了,几乎都浪费在了编译正则化对象上。
改进
原本我们可以手动更改_MAXCACHE的大小,但是要跨平台运行,所以我们可以手动自己造一个简单的缓存。
# 缓存器_url_patterns_max_cache=512 if len(url_patterns)<=512 else (len(url_patterns)/256+1)*256_url_patterns_cache={}for url_pattern in url_patterns:if len(_url_patterns_cache)>_url_patterns_max_cache):_url_patterns_cache.clear()url_patterns_cache.update({url_pattern:re.compile(url_pattern)})# 直接从缓存中取值进行匹配for url_pattern_key in _url_patterns_cache:if _url_patterns_cache.get(url_pattern_key).match(url):return url_pattern_key
最后我们只用缓存中的编译好的对象直接进行匹配即可,整个过程每一个规则只用编译一次,极大的节省了时间。~以下是经过优化后的性能表现。总花时382233 ms约为6.37 minutes ,完美解决!

感想
说一点感想,这是我实习第一次要做的任务,虽然没啥难度,也可让我抓耳挠腮了一阵子了。本来都做好了,偏偏又出了这个性能问题,花了我一两天时间排查和改进,其中我还学习了profile工具。不得不说,我还是太年轻了。人生还需要不断地学习和巩固知识。
关于python的一次性能调优过程的更多相关文章
- 记一次数据库调优过程(IIS发过来SQLSERVER 的FETCH API_CURSOR语句是神马?)
记一次数据库调优过程(IIS发过来SQLSERVER 的FETCH API_CURSOR语句是神马?) 前几天帮客户优化一个数据库,那个数据库的大小是6G 这麽小的数据库按道理不会有太大的性能问题的, ...
- OpenTSDB/HBase的调优过程整理
背景 过年前,寂寞哥给我三台机器,说搞个新的openTSDB集群.机器硬件是8核16G内存.3个146G磁盘做数据盘. 我说这太抠了,寂寞哥说之前的TSDB集群运行了两年,4台同样配置的机器,目前hd ...
- 一次jvm调优过程
jvm调优实战 前端时间把公司的一个分布式定时调度的系统弄上了容器云,部署在kubernetes,在容器运行的动不动就出现问题,特别容易jvm溢出,导致程序不可用,终端无法进入,日志一直在刷错误,ku ...
- jvm参数解析(含调优过程)
前阵 对底层账单系统进行了压测调优,调优的最后一步--jvm启动参数中,减小了线程的堆栈空间:-XX:ThreadStackSize=256K,缩减至原来的四分之一,效果明显,不过并没有调 ...
- 一个简单web系统的接口性能分析及调优过程
在测试一个简单系统接口性能压力时,压到一定数量,程序总是崩溃,查看相关机器相关数据时,CPU.内存.IO占用均不高,问题自然出现在其它地方先介绍下系统部件架构 Resin版本为:[root@local ...
- 数据库调优过程(一):SqlServer批量复制(bcp)[C#SqlBulkCopy]性能极低问题
背景 最近一段给xx做项目,这边最头疼的事情就是数据库入库瓶颈问题. 环境 服务器环境:虚拟机,分配32CPU,磁盘1.4T,4T,5T,6T几台服务器不等同(转速都是7200r),内存64G. 排查 ...
- 从oracle往greenplum迁移,查询性能不满足要求的定位以及调优过程
一.前言 在一次对比oracle和greenplum查询性能过程中,由于greenplum查询性能不理想,因此进行定位分析,提升greenplum的查询性能 二.环境信息 初始情况下,搭建一个小的集群 ...
- 数据库调优过程(二):找到IO不存在问题,而是sqlserver单表写入IO瓶颈
物理机上测试IO是否为瓶颈: 使用一个死循环insert into测试数据库最大写入速度: use [iTest]; declare @index int; ; begin ; INSERT into ...
- 一次mysql调优过程
由于经常被抓取文章内容,在此附上博客文章网址:,偶尔会更新某些出错的数据或文字,建议到我博客地址 : --> 点击这里 前几天进行了一个数据库查询,比较缓慢,便查询了一下,在这里记录一下,方便 ...
随机推荐
- JWT签名算法
JWT签名算法 JWT签名算法中,一般有两个选择,一个采用HS256,另外一个就是采用RS256. 签名实际上是一个加密的过程,生成一段标识(也是JWT的一部分)作为接收方验证信息是否被篡改的依据. ...
- Column 'status' specified twice
字段写了两次, 检查下sql语句, 删除一个就好了.
- longitudinal models | 纵向研究 | mixed model
A longitudinal study refers to an investigation where participant outcomes and possibly treatments o ...
- 常见的医学基因筛查检测 | genetic testing | 相癌症早筛 | 液体活检
NIPT, Non-invasive Prenatal Testing - 无创产前基因检测 (学术名词) NIFTY,胎儿染色体异常无创产前基因检测 (注册商标)华大的明显产品 新生儿耳聋基因检测 ...
- chrome 等浏览器不支持本地ajax请求,的问题
XMLHttpRequest cannot load file:///D:/WWW/angularlx/ui-router-test/template/content.html. Cross orig ...
- CentOS上安装GlassFish4.0
1. 安装jdk 2. 下载并安装glassfish4 [root@linuxidc ~]# mv glassfish-4.0-ml.zip /usr/share/glassfish-4.0-ml. ...
- 【Java】Spring之控制反转(IoC)(二)
控制反转(IoC) IoC:Inverse of Control(控制反转) 读作“反转控制”,更好理解,不是什么技术,而是一种设计思想,就是将原本在程序中手动创建对象的控制权,交由Spring框架来 ...
- [转]Microsoft VS Code 改变默认文字编码
概要:文件->首选项->设置 输入: "files.autoGuessEncoding": true, 然后勾上. 链接地址:https://jingyan.baidu ...
- C# 获取或设置指定 config 文件的值
ExeConfigurationFileMap 这个类提供了修改.获取指定 config 的功能:新建一个 ExeConfigurationFileMap 的实例 ecf :并设置 ExeConfig ...
- CountDownLatch和CyclicBarrier使用上的区别
一.CountDownLatchDemo package com.duchong.concurrent; import java.util.Map; import java.util.concurre ...