大数据调度工具oozie详细介绍
背景
之前项目中的sqoop等离线数据迁移job都是利用shell脚本通过crontab进行定时执行,这样实现的话比较简单,但是随着多个job复杂度的提升,无论是协调工作还是任务监控都变得麻烦,我们选择使用oozie来对工作流进行调度监控。在此介绍一下oozie~
官网介绍
首先看官网首页介绍:http://oozie.apache.org

(1)Oozie是一个管理 Apache Hadoop 作业的工作流调度系统。
(2)Oozie的 workflow jobs 是由 actions 组成的 有向无环图(DAG)。
(3)Oozie的 coordinator jobs 是由时间 (频率)和数据可用性触发的重复的 workflow jobs 。
(4)Oozie与Hadoop生态圈的其他部分集成在一起,支持多种类型的Hadoop作业(如Java map-reduce、流式map-reduce、Pig、Hive、Sqoop和Distcp)以及特定于系统的工作(如Java程序和shell脚本)。
(5)Oozie是一个可伸缩、可靠和可扩展的系统。
oozie web控制台界面如下:
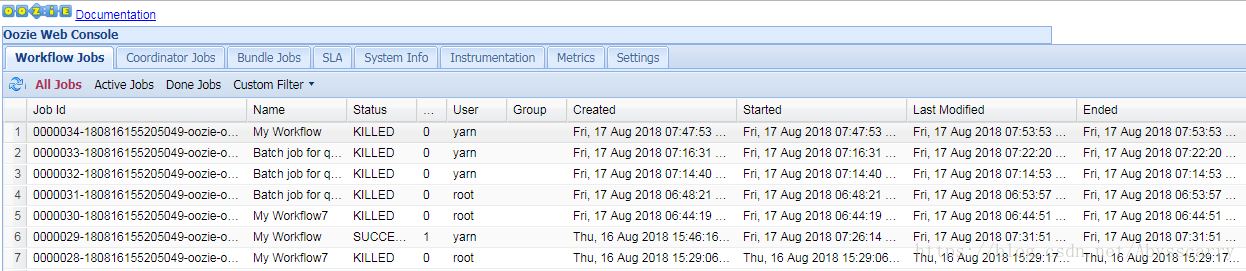
注:如果界面报错 Oozie web console is disabled,请看https://blog.csdn.net/Abysscarry/article/details/80503594
对比选型
在没有工作流调度系统之前,公司里面的任务都是通过 crontab 来定义的,时间长了后会发现很多问题:
1.大量的crontab任务需要管理
2.任务没有按时执行,各种原因失败,需要重试
3.多服务器环境下,crontab分散在很多集群上,光是查看log就很花时间
于是,出现了一些管理crontab任务的调度系统,如 CronHub、CronWeb 等。
而在大数据领域,现在市面上常用的工作流调度工具有Oozie, Azkaban,Cascading,Hamake等,
我们往往把 Oozie和Azkaban来做对比:
两者在功能方面大致相同,只是Oozie底层在提交Hadoop Spark作业是通过org.apache.hadoop的封装好的接口进行提交,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
工作流定义: Oozie是通过xml定义的而Azkaban为properties来定义。
部署过程: Oozie的部署相对困难些,同时它是从Yarn上拉任务日志。
任务检测: Azkaban中如果有任务出现失败,只要进程有效执行,那么任务就算执行成功,这是BUG,但是Oozie能有效的检测任务的成功与失败。
操作工作流: Azkaban使用Web操作。Oozie支持Web,RestApi,Java API操作。
权限控制: Oozie基本无权限控制,Azkaban有较完善的权限控制,供用户对工作流读写执行操作。
运行环境: Oozie的action主要运行在hadoop中而Azkaban的actions运行在Azkaban的服务器中。
记录workflow的状态: Azkaban将正在执行的workflow状态保存在内存中,Oozie将其保存在Mysql中。
出现失败的情况: Azkaban会丢失所有的工作流,但是Oozie可以在继续失败的工作流运行
由于我在安装公司CDH集群时已经安装好oozie了,且有对应的可视化操作工具hue,所以我们直接选择oozie进行工作流调度啦!
原理详解
主要概念:
我们在官网介绍中就注意到了,Oozie主要有三个主要概念,分别是 workflow,coordinator,bundle。
其中:
Workflow:工作流,由我们需要处理的每个工作组成,进行需求的流式处理。
Coordinator:协调器,可以理解为工作流的协调器,可以将多个工作流协调成一个工作流来进行处理。
Bundle:捆,束。将一堆的coordinator进行汇总处理。简单来说:workflow是对要进行的顺序化工作的抽象,coordinator是对要进行的顺序化的workflow的抽象,bundle是对一堆coordiantor的抽象。层级关系层层包裹。
Oozie本质是通过 launcher job 运行某个具体的Action。launcher job是一个 map-only 的MR作业,而且并不知道它将在集群的哪台机器上执行这个MR作业。oozie有很多的坑,也是因为这个 launcher job 解析job时触发的异常情况!
组件架构图:
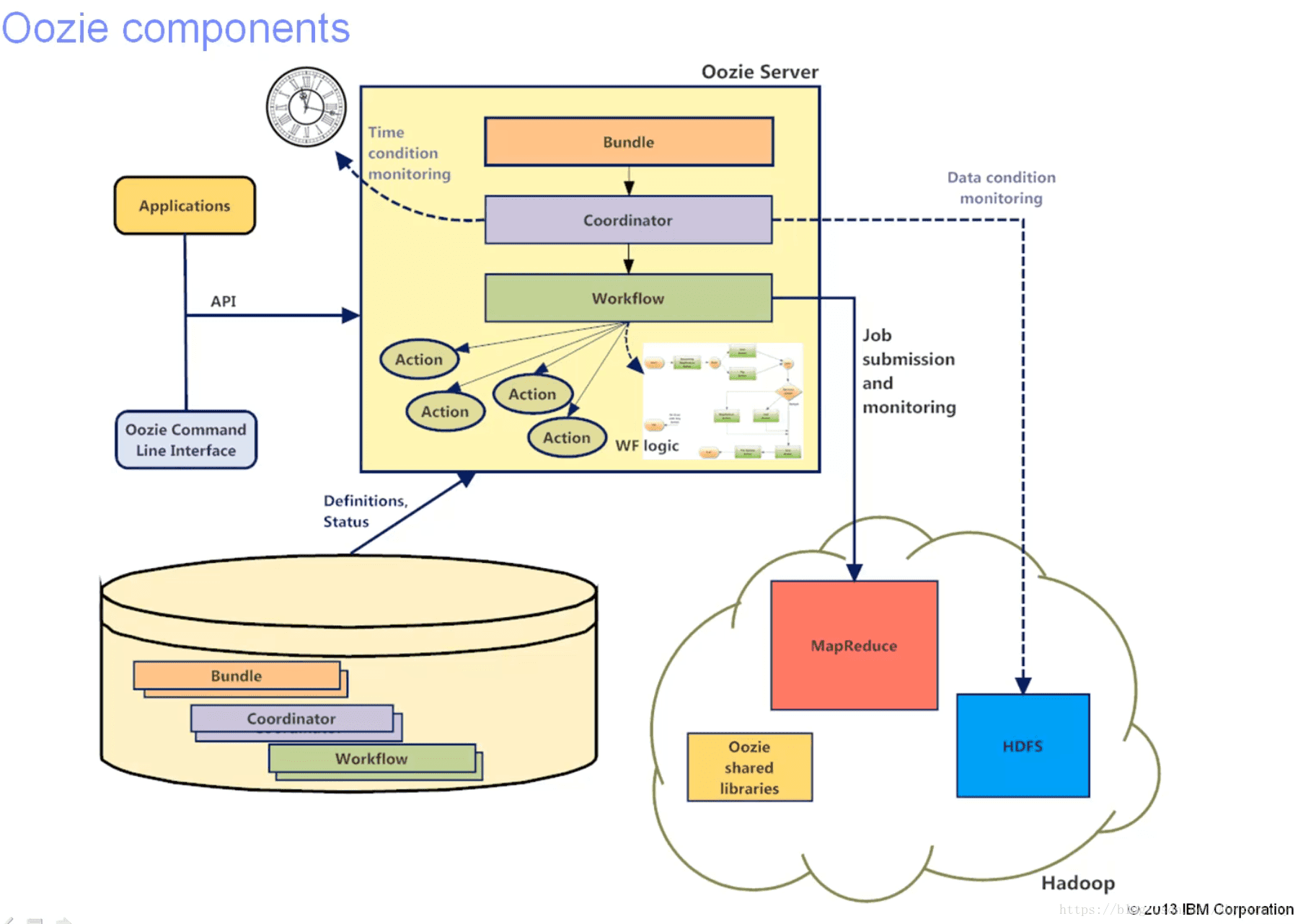
ps:这个图是google上好不容易找到的,国内基本没有或者不清晰…
相信稍微了解下oozie的具体用法后再看这个图,就一目了然了!
Job组成:
一个oozie 的 job 一般由以下文件组成:
job.properties :记录了job的属性
workflow.xml :使用hPDL 定义任务的流程和分支
lib目录:用来执行具体的任务其中:
Job.properties:
| KEY | 含义 |
|---|---|
| nameNode | HDFS地址 |
| jobTracker | jobTracker(ResourceManager)地址 |
| queueName | Oozie队列(默认填写default) |
| examplesRoot | 全局目录(默认填写examples) |
| oozie.usr.system.libpath | 是否加载用户lib目录(true/false) |
| oozie.libpath | 用户lib库所在的位置 |
| oozie.wf.application.path | Oozie流程所在hdfs地址(workflow.xml所在的地址) |
| user.name | 当前用户 |
| oozie.coord.application.path | Coordinator.xml地址(没有可以不写) |
| oozie.bundle.application.path | Bundle.xml地址(没有可以不写) |
注:
1、这个文件如果是在本地通过命令行进行任务提交的话,这个文件在本地就可以了,当然也可以放在hdfs上,与workflow.xml和lib处于同一层级。
2、nameNode,jobTracker和 workflow.xml在hdfs中的位置必须设置。
e.g:Shell节点的job.properties文件示例如下:
nameNode=hdfs://cm1:8020
jobTracker=cm1:8032
queueName=default
examplesRoot=examples
oozie.wf.application.path=${nameNode}/user/workflow/oozie/shellworkflow.xml:
这个文件是定义任务的整体流程的文件,官网wordcount例子如下:
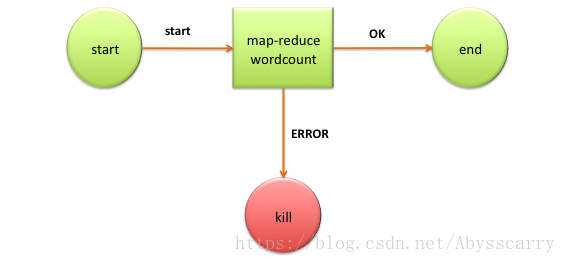
<workflow-app name='wordcount-wf' xmlns="uri:oozie:workflow:0.1">
<start to='wordcount'/>
<action name='wordcount'>
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.mapper.class</name>
<value>org.myorg.WordCount.Map</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.myorg.WordCount.Reduce</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>${inputDir}</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>${outputDir}</value>
</property>
</configuration>
</map-reduce>
<ok to='end'/>
<error to='end'/>
</action>
<kill name='kill'>
<message>Something went wrong: ${wf:errorCode('wordcount')}</message>
</kill/>
<end name='end'/>
</workflow-app>
可以看到:
**[控制流节点]:主要包括start、end、fork、join等,其中fork、join成对出现,在fork展开。分支,最后在join结点汇聚
** start
** kill
** end
**[动作节点]:包括Hadoop任务、SSH、HTTP、EMAIL、OOZIE子任务
** ok --> end
** error --> end
** 定义具体需要执行的job任务
** MapReduce、shell、hive文件需要被放在HDFS上才能被oozie调度,如果在启动需要调动MR任务,jar包同样需要在hdfs上
Lib目录:
在workflow工作流定义的同级目录下,需要有一个lib目录,在lib目录中存在java节点MapReduce使用的jar包。
需要注意的是,oozie并不是使用指定jar包的名称来启动任务的,而是通过制定主类来启动任务的。在lib包中绝对不能存在某个jar包的不同版本,不能够出现多个相同主类。
Workflow 介绍:
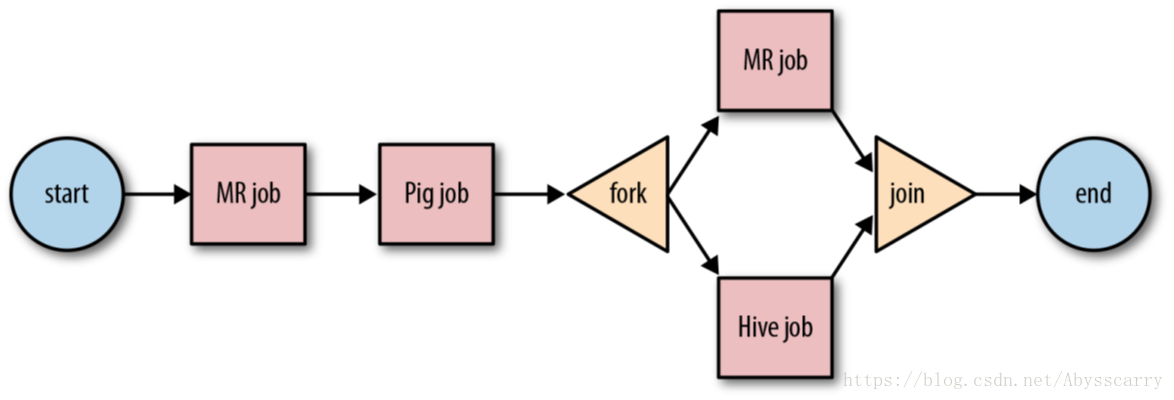
workflow 是一组 actions 集合(例如Hadoop map/reduce作业,pig作业),它被安排在一个控制依赖项DAG(Direct Acyclic Graph)中。“控制依赖”从一个action到另一个action意味着第二个action不能运行,直到第一个action完成。
Oozie Workflow 定义是用 hPDL 编写的(类似于JBOSS JBPM jPDL的XML过程定义语言)。
Oozie Workflow actions 在远程系统(如Hadoop、Pig)中启动工作。在action完成时,远程系统 回调 Oozie通知action完成,此时Oozie将继续在workflow 中进行下一步操作。
Oozie Workflow 包含控制流节点(control flow nodes)和动作节点(action nodes).
控制流节点定义workflow的开始和结束(start、end 和 fail 节点),并提供一种机制来控制workflow执行路径(decision、fork和join节点)。
action 节点是workflow触发计算/处理任务执行的机制。Oozie为不同类型的操作提供了支持:Hadoop map-reduce、Hadoop文件系统、Pig、SSH、HTTP、电子邮件和Oozie子工作流。Oozie可以扩展来支持其他类型的操作。
Oozie Workflow 可以被参数化(在工作流定义中使用诸如$inputDir之类的变量)。在提交workflow作业值时,必须提供参数。如果适当地参数化(即使用不同的输出目录),几个相同的workflow作业可以并发。
Coordinator介绍:
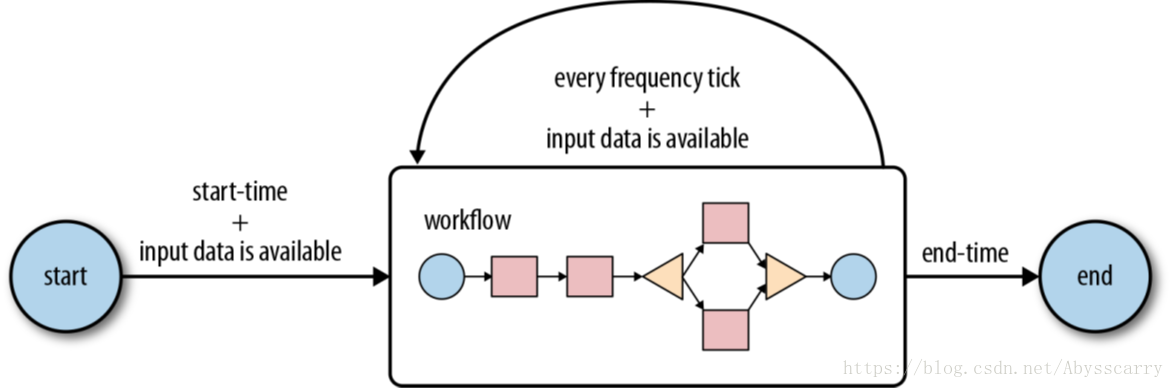
用户通常在grid上运行map-reduce、hadoop流、hdfs或pig作业。这些作业中的多个可以组合起来形成一个workflow 作业。Hadoop workflow 系统定义了一个workflow 系统来运行这样的工作。
通常,workflow 作业是基于常规的时间间隔(time intervals)和数据可用性(data availability)运行的。在某些情况下,它们可以由外部事件触发。
表示触发workflow 作业的条件可以被建模为必须满足的谓词(predicate )。workflow 作业是在谓词满足之后开始的。谓词可以引用数据、时间和/或外部事件。在将来,可以扩展模型来支持额外的事件类型。
还需要连接定期运行的workflow 作业,但在不同的时间间隔内。多个后续运行的workflow 的输出成为下一个workflow 的输入。例如,每15分钟运行一次的workflow 的4次运行的输出,就变成了每隔60分钟运行一次的workflow 的输入。将这些workflow 链接在一起会导致它被称为数据应用程序管道。
Oozie Coordinator 系统允许用户定义和执行周期性和相互依赖的workflow 作业(数据应用程序管道)。
真实世界的数据应用管道必须考虑到二次处理、后期处理、捕获、部分处理、监测、通知和SLAS。
Bundle介绍:
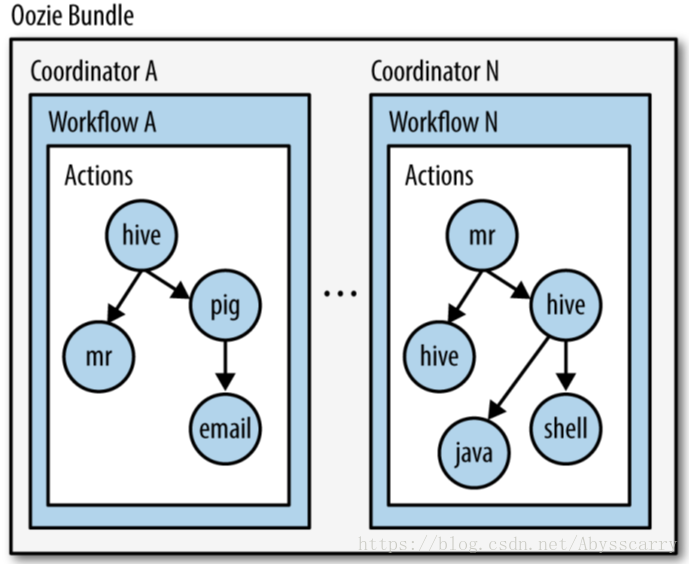
Bundle 是一个更高级的oozie抽象,它将批处理一组Coordinator应用程序。
用户将能够在bundle级别启动/停止/暂停/恢复/重新运行,从而获得更好、更容易的操作控制。
更具体地说,oozie Bundle系统允许用户定义和执行一堆通常称为数据管道的Coordinator应用程序。在Bundle中,Coordinator应用程序之间没有显式的依赖关系。然而,用户可以使用Coordinator应用程序的数据依赖来创建隐式数据应用程序管道。
大数据调度工具oozie详细介绍的更多相关文章
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- 一篇文章看懂TPCx-BB(大数据基准测试工具)源码
TPCx-BB是大数据基准测试工具,它通过模拟零售商的30个应用场景,执行30个查询来衡量基于Hadoop的大数据系统的包括硬件和软件的性能.其中一些场景还用到了机器学习算法(聚类.线性回归等).为了 ...
- CentOS6安装各种大数据软件 第九章:Hue大数据可视化工具安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 联童科技基于incubator-dolphinscheduler从0到1构建大数据调度平台之路
联童科技是一家智能化母婴童产业平台,从事母婴童行业以及互联网技术多年,拥有丰富的母婴门店运营和系统开发经验,在会员经营和商品经营方面,能够围绕会员需求,深入场景,更贴近合作伙伴和消费者,提供最优服务产 ...
- 3款大数据bi工具,让企业数据分析更简单
企业数据可视化的髙速发展趋势让互联网时代的数据分析及可视化拥有全新的面貌.企业针对信息内容的数据分析及可视化,的要求在日益严格,那么有哪些在企业数据分析方面做得好的大数据bi工具呢? 一.大数据bi ...
- 百亿级别数据量,又需要秒级响应的案例,需要什么系统支持呢?下面介绍下大数据实时分析工具Yonghong Z-Suite
Yonghong Z-Suite 除了提供优秀的前端BI工具之外,Yonghong Z-Suite让用户可以选购分布式数据集市来支持实时大数据分析. 对于这种百亿级的大数据案例,Yonghong Z- ...
- Hadoop和大数据:60款顶级大数据开源工具
一.Hadoop相关工具 1. Hadoop Apache的Hadoop项目已几乎与大数据划上了等号.它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算. 支持的操作系统: ...
- 【转载】Hadoop和大数据:60款顶级大数据开源工具
一.Hadoop相关工具 1. Hadoop Apache的Hadoop项目已几乎与大数据划上了等号.它不断壮大起来,已成为一个完整的生态系统,众多开源工具面向高度扩展的分布式计算. 支持的操作系统: ...
- 数据层交换和高性能并发处理(开源ETL大数据治理工具--KETTLE使用及二次开发 )
ETL是什么?为什么要使用ETL?KETTLE是什么?为什么要学KETTLE? ETL是数据的抽取清洗转换加载的过程,是数据进入数据仓库进行大数据分析的载入过程,目前流行的数据进入仓库的 ...
随机推荐
- 【Gamma】Scrum Meeting 8
前言 会议定点:大运村公寓 会议时间:2019/6/7 会议目的:分配任务,准备宣传 一.任务进度 组员 上周任务进度 下阶段任务 大娃 辅助做好引导录屏 优化辅助模型 二娃 撰写会议博客 撰写会议博 ...
- 浅谈设计模式-visitor访问者模式
先看一个和visitor无关的案例.假设你现在有一个书架,这个书架有两种操作,1添加书籍2阅读每一本书籍的简介. //书架public class Bookcase { List<Book> ...
- Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- Mysql常见注意事项小记
1. 排序问题 正常如果按照某字段升序排列,空值会排到有值的前面;如果逆序排序空值排在最后. 有时候我们需要该字段为空的行数据要排到最后面去,这时只需要: order by second_parent ...
- idea 跳转提示多个实现类
- Visual Studio pro key license 2019
仅供学习交流使用,勿用作其他用途!!!! Visual Studio 2019 Enterprise BF8Y8-GN2QH-T84XB-QVY3B-RC4DF Visual Studio 201 ...
- golang --rune
rune 是int32的别名类型,专用于存储Unicode编码的单个字符 我们可以用5种方式来表示一个rune字面量: 该rune字面量所对应的字符,如'a'必须是Unicode编码规范所支持的 使用 ...
- Elasticsearch常见用法-入门
前台启动 默认是只有本地可以访问 ./bin/elasticsearch 远程访问 修改elasticsearch.yml,把network.host(注意配置文件格式不是以 # 开头的要空一格, : ...
- 入门-windows下安装ETH挖矿
对刚入门的区块链开发者来说,刚开始可以在windows本地搭建私有链,便于操作,毕竟,要想真正挖到币还是有难度的,下面以ETH为例,在windows环境下安装并实现挖矿. 步骤一.安装geth环境.下 ...
- C的温习-开头篇1
编译运行C语言可以用很多软件MicrosoftVisualC++.MicrosoftVisualStudio.DEVC++.Code::Blocks.BorlandC++.WaTComC++.Borl ...