Java抓取网页数据(原来的页面+Javascript返回数据)
转载请注明出处!
原文链接:http://blog.csdn.net/zgyulongfei/article/details/7909006
有时候因为种种原因,我们须要採集某个站点的数据,但因为不同站点对数据的显示方式略有不同。
本文就用Java给大家演示怎样抓取站点的数据:(1)抓取原网页数据;(2)抓取网页Javascript返回的数据。
一、抓取原网页。
这个样例我们准备从http://ip.chinaz.com上抓取ip查询的结果:
第一步:打开这个网页。然后输入IP:111.142.55.73。点击查询button。就能够看到网页显示的结果:

第二步:查看网页源代码。我们看到源代码中有这么一段:

从这里能够看出。查询的结果,是又一次请求一个网页之后显示的。
再看看查询之后的网页地址:
也就是说。我们仅仅要訪问形如这种网址。就能够得到ip查询的结果,接下来看代码:
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?
IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("查询结果[");
int endIx = buf.indexOf("上面四项依次显示的是");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()的结果:\n" + result);
}
使用HttpURLConnection连接站点,用bufReader保存网页返回的数据,然后通过自己定义的一个解析方式将结果显示出来。
这里我仅仅是随便的解析了一下,要解析的很准确的话自己需再处理。
解析结果例如以下:
captureHtml()的结果:
查询结果[1]: 111.142.55.73 ==>> 1871591241 ==>> 福建省漳州市 移动</strong><br />
二、抓取网页JavaScript返回的结果。
有时候站点为了保护自己的数据。并没有把数据直接放在网页源代码中返回。而是採用异步的方式,用JS返回数据,这样能够避免搜索引擎等工具对站点数据的抓取。
首先看一下这个网页:
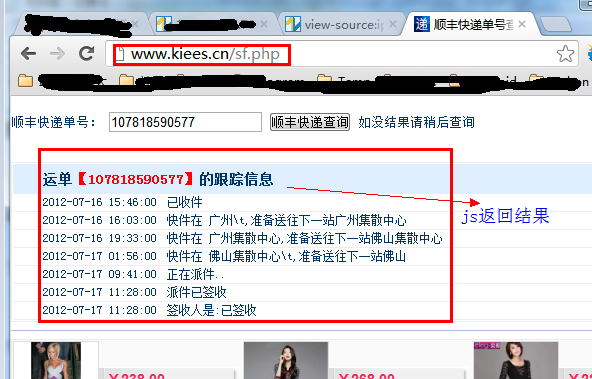
用第一种方式查看该网页的源代码。却没有发现该运单的跟踪信息,由于它是通过JS的方式获取结果的。
但有时候我们非常须要获取到JS的数据,这个时候要怎么办呢?
这个时候我们须要用到一个工具:HTTP Analyzer,这个工具能够截获Http的交互内容,我们通过这个工具来达到我们的目的。
首先点击Startbutton之后,它就開始监听网页的交互行为了。
我们打开网页:http://www.kiees.cn/sf.php ,能够看到HTTP Analyzer列出了全部该网页的请求数据以及结果:
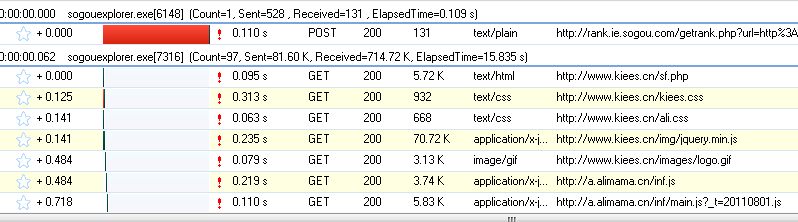
为了更方便的查看JS的结果。我们先清空这些数据,然后再网页中输入快递单号:107818590577。点击查询button,然后查看HTTP Analyzer的结果:

这个就是点击查询button之后。HTTP Analyzer的结果,我们继续查看:
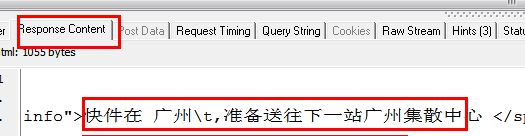
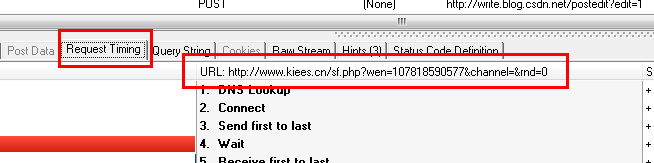
从上面两幅图中能够看出,HTTP Analyzer能够截获JS返回的数据,并在Response Content中显示,同一时候能够看到JS请求的网页地址。
既然如此,我们仅仅要分析HTTP Analyzer的结果,然后模拟JS的行为就可获取到数据。即我们仅仅要訪问JS请求的网页地址来获取数据,当然前提是这些数据是没有经过加密的,我们记下JS请求的URL:http://www.kiees.cn/sf.php?
wen=107818590577&channel=&rnd=0
然后让程序去请求这个网页的结果就可以!
以下是代码:
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?
wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());
}
看到了吧,抓取JS的方式和前面抓取原网页的代码一模一样,我们仅仅只是做了一个分析JS的过程。
以下是程序运行的结果:
captureJavascript()的结果:
<div class="results"><div id="ali-itu-wl-result" class="ali-itu-wl-result"><h2 class="logisTitle">运单<span class="mail-no">【107818590577】</span>的跟踪信息</h2><div class="trace_result"><ul><li><span
class="time">2012-07-16 15:46:00</span><span class="info">已收件 </span></li><li><span class="time">2012-07-16 16:03:00</span><span class="info">快件在 广州\t,准备送往下一站广州集散中心 </span></li><li><span class="time">2012-07-16 19:33:00</span><span class="info">快件在 广州集散中心,准备送往下一站佛山集散中心
</span></li><li><span class="time">2012-07-17 01:56:00</span><span class="info">快件在 佛山集散中心\t,准备送往下一站佛山 </span></li><li><span class="time">2012-07-17 09:41:00</span><span class="info">正在派件.. </span></li><li><span class="time">2012-07-17 11:28:00</span><span
class="info">派件已签收 </span></li><li><span class="time">2012-07-17 11:28:00</span><span class="info">签收人是:已签收 </span></li></ul><div></div></div></div> </div>
这些数据就是JS返回的结果了,我们的目的达到了!
我希望这能成为一个小朋友需要帮助,需要程序的源代码,点击这里下载!
Java抓取网页数据(原来的页面+Javascript返回数据)的更多相关文章
- java抓取网页数据,登录之后抓取数据。
最近做了一个从网络上抓取数据的一个小程序.主要关于信贷方面,收集的一些黑名单网站,从该网站上抓取到自己系统中. 也找了一些资料,觉得没有一个很好的,全面的例子.因此在这里做个笔记提醒自己. 首先需要一 ...
- Java抓取网页数据(原网页+Javascript返回数据)
有时候由于种种原因,我们需要采集某个网站的数据,但由于不同网站对数据的显示方式略有不同! 本文就用Java给大家演示如何抓取网站的数据:(1)抓取原网页数据:(2)抓取网页Javascript返回的数 ...
- 使用JAVA抓取网页数据
一.使用 HttpClient 抓取网页数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ...
- Java 抓取网页中的内容【持续更新】
背景:前几天复习Java的时候看到URL类,当时就想写个小程序试试,迫于考试没有动手,今天写了下,感觉还不错 内容1. 抓取网页中的URL 知识点:Java URL+ 正则表达式 import jav ...
- java 抓取网页图片
import java.io.File; import java.io.FileOutputStream; import java.io.InputStream; import java.io.Out ...
- Java抓取网页数据
http://ayang1588.github.io/blog/2013/04/08/catchdata/ 最近处于离职状态,正赶清闲,开始着手自己的毕业设计,课题定的是JavaWeb购物平台,打算用 ...
- 走过路过不要错过~教你用java抓取网页中你想要的东东~~
学习了正则之后,打算用java玩一玩,所以就决定用它来实现一个好玩的idea import java.io.BufferedReader; import java.io.IOException; im ...
- java抓取网页或者文件的邮箱号码
抓文件的 package reg; import java.io.BufferedReader; import java.io.FileNotFoundException; import java.i ...
- Jsoup一个简短的引论——采用Java抓取网页数据
转载请注明出处:http://blog.csdn.net/allen315410/article/details/40115479 概述 jsoup 是一款Java 的HTML解析器,可直接解析某个U ...
随机推荐
- CuSparse 第一章
(部分翻译) 第一章 介绍 1. 命名惯例 CUSPARSE 包含了一系列处理稀疏矩阵的基本的线性代数子程式.是cuda函数库的一部分,从C,C++中调用. 该库例程可以分为四类: 第一层:在稠密向量 ...
- 怎样建立一个bower私库
本教程适用于centos 安装之前 检查nodejs 假设没安装nodejs依照下面步骤安装 $ su - $ yum install openssl-devel $ cd /usr/local/sr ...
- 读TIJ -2 一切都是对象
<第2 章一切都是对象> 1.一切都是对象.不是Bruce Eckel说的,而是Alan Kay 总结的Smalltalk 五大基本特征的第一条. 从程序设计者或源码的角度,我觉得:&qu ...
- 基于JSP+SERVLET的新闻发布系统(二)
接下来讲解的是通过AJAX验证用户名是否已经添加 用户名: <input type="text" name="userName" id="use ...
- Ch03 视图基础
3.1 视图简介 3.1.1 选择待渲染视图 3.1.2 重写视图名 3.2 给视图传递数据 3.2.1 ViewDataDictionary 3.2.2 ViewBag 3.2.3 带 ...
- Objective-C中的SEL、IMP和Class类型
1.SEL类型 例子: SEL say; SEL skin; Objective-C 在编译的时候, 会根据方法的名字(包括参数序列),生成一个用 来区分这个方法的唯一的一个 ID,这个 ...
- Silverlight技术调查(1)——Html向Silverlight传参
原文 Silverlight技术调查(1)——Html向Silverlight传参 近几日项目研究一个很牛的富文档编辑器DXperience RichEdit组件,调查环境为Silverlight4. ...
- 菜鸟级springmvc+spring+mybatis整合开发用户登录功能(下)
昨天介绍了mybatis与spring的整合,今天我们完成剩下的springmvc的整合工作. 要整合springmvc首先得在web.xml中配置springmvc的前端控制器DispatcherS ...
- Boost::Thread 多线程的基础知识
Boost.Thread可以使用多线程执行可移植C++代码中的共享数据.它提供了一些类和函数来管理线程本身,还有其它一些为了实现在线程之间同步数据或者提供针对特定单个线程的数据拷贝.头文件:#incl ...
- u盘安装ubuntu10.04 server.txt
10.04 先将 ubuntu server 的 iso 放到优盘上,然后在提示无法找到光驱时,按 alt+f2 打开一个新的 console 窗口,将 iso mount 上,具体操作如下: ls ...