.Net下的分库分表帮助类——用分库的思想来分表
简介
对比
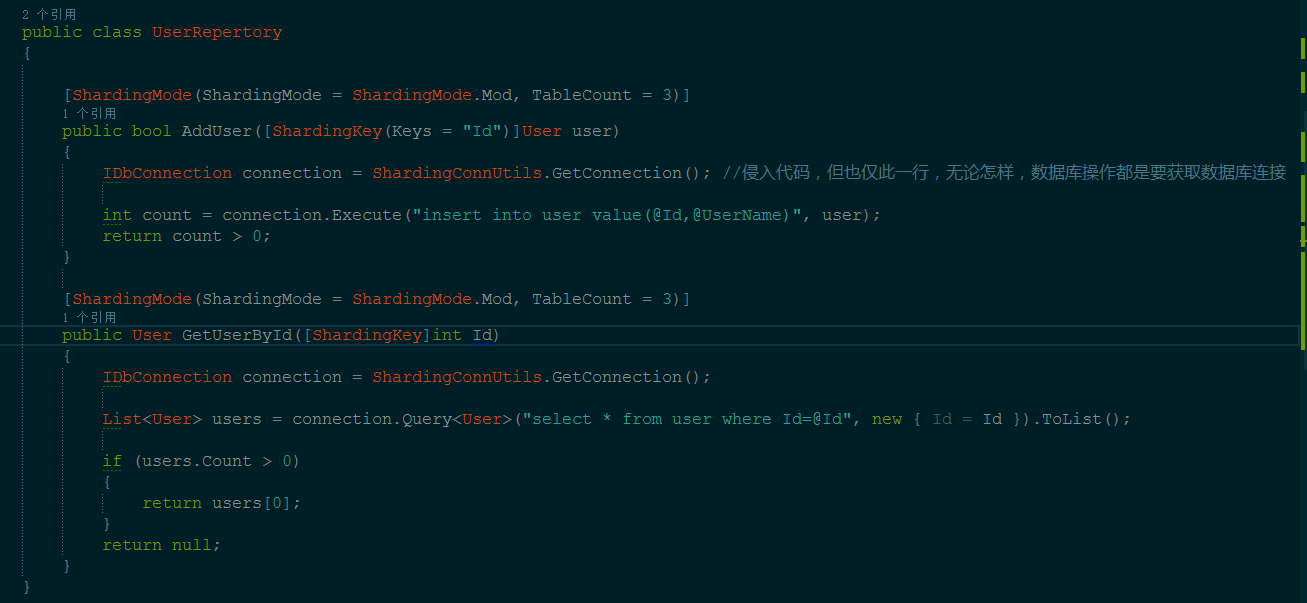
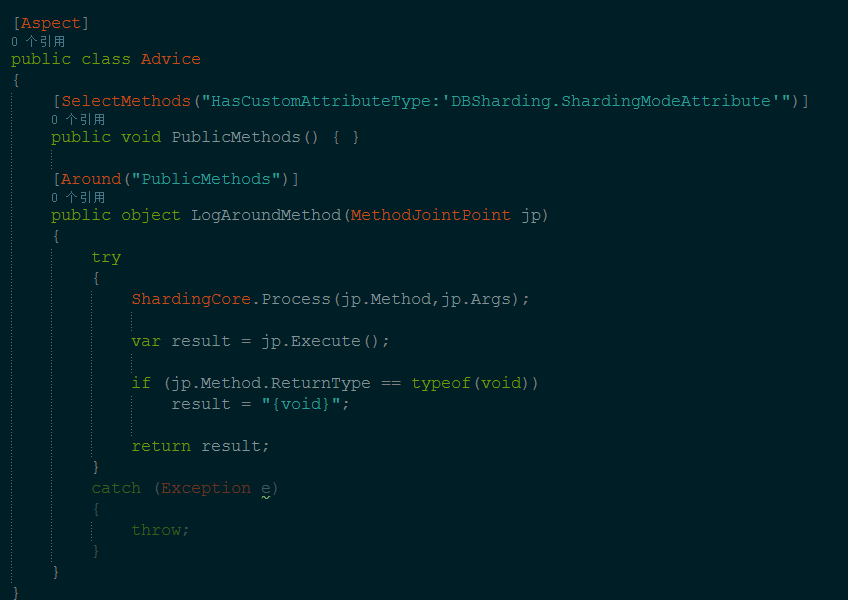
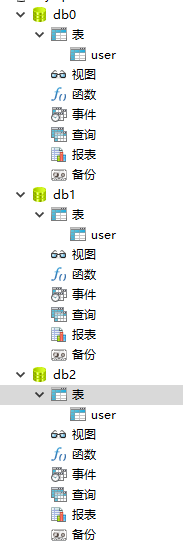
我的解决方案




后记
.Net下的分库分表帮助类——用分库的思想来分表的更多相关文章
- web(四)html表单类标签
表单类标签 操作者用于输入信息,并将信息提交给服务器的标签集合. 表单标签介绍 form标签:表单元素(其余标签)标签的容器标签 input标签:用于用户信息输入的标签. button标签:按钮标签. ...
- MySQL单机优化---分表、分区、分库
一.分表: 水平分表:根据条件把数据分为N个表(例如:商品表中有月份列,则可以按月份进行水平分表). 使用场景:一张表中数据太多,查询效率太慢. 当需要同时查询被水平分表的多张表时: 在两条SQL语句 ...
- 【Java EE 学习 77 下】【数据采集系统第九天】【使用spring实现答案水平分库】【未解决问题:分库查询问题】
之前说过,如果一个数据库中要存储的数据量整体比较小,但是其中一个表存储的数据比较多,比如日志表,这时候就要考虑分表存储了:但是如果一个数据库整体存储的容量就比较大,该怎么办呢?这时候就需要考虑分库了, ...
- ShoneSharp语言(S#)的设计和使用介绍系列(11)—“类”披炫服靓妆化成“表”
ShoneSharp语言(S#)的设计和使用介绍 系列(11)—“类”披炫服靓妆化成“表” 作者:Shone 声明:原创文章欢迎转载,但请注明出处,https://www.cnblogs.com/Sh ...
- C# 我的注册表操作类
using System; using System.Collections.Generic; using System.Text; using Microsoft.Win32; using Syst ...
- GreenDao 工具类 --- 使用 Json 快速生成 Bean、表及其结构,"炒鸡"快!
作者:林冠宏 / 指尖下的幽灵 掘金:https://juejin.im/user/587f0dfe128fe100570ce2d8 博客:http://www.cnblogs.com/linguan ...
- C#注册表操作类--完整优化版
using System; using System.Collections.Generic; using System.Text; using Microsoft.Win32; namespace ...
- PTA 邻接表存储图的广度优先遍历(20 分)
6-2 邻接表存储图的广度优先遍历(20 分) 试实现邻接表存储图的广度优先遍历. 函数接口定义: void BFS ( LGraph Graph, Vertex S, void (*Visit)(V ...
- Python的Django框架中forms表单类的使用方法详解
用户表单是Web端的一项基本功能,大而全的Django框架中自然带有现成的基础form对象,本文就Python的Django框架中forms表单类的使用方法详解. Form表单的功能 自动生成HTML ...
随机推荐
- 苹果应用商店AppStore审核中文指南
目录 1. 条款与条件2. 功能3. 元数据.评级与排名4. 位置5. 推送通知6. 游戏中心7. 广告8. 商标与商业外观9. 媒体内容10. 用户界面11. 购买与货币12. 抓取与聚合13. 设 ...
- CodeForces 629C Famil Door and Brackets
DP. 具体做法:dp[i][j]表示长度为 i 的括号串,前缀和(左括号表示1,右括号表示-1)为 j 的有几种. 状态转移很容易得到:dp[i][j]=dp[i - 1][j + 1]+dp[i ...
- (中等) POJ 1436 Horizontally Visible Segments , 线段树+区间更新。
Description There is a number of disjoint vertical line segments in the plane. We say that two segme ...
- BZOJ 2209: [Jsoi2011]括号序列 [splay 括号]
2209: [Jsoi2011]括号序列 Time Limit: 20 Sec Memory Limit: 259 MBSubmit: 1111 Solved: 541[Submit][Statu ...
- iOS正则表达式 分类: ios技术 2015-07-14 14:00 35人阅读 评论(0) 收藏
一.什么是正则表达式 正则表达式,又称正规表示法,是对字符串操作的一种逻辑公式.正则表达式可以检测给定的字符串是否符合我们定义的逻辑,也可以从字符串中获取我们想要的特定部分.它可以迅速地用极简单的方式 ...
- IOS 实现TXT文本自动识别编码的方法
from :http://kyoworkios.blog.51cto.com/878347/1344013 TXT识别编码是个复杂的问题.幸好有c/c++的一个库能识别. 库的叫uchardet,可以 ...
- MAC中使用Vim和GCC编译C程序
1.打开终端 2.输入以下命令进入vim编辑器: vim a.c 3.进入编辑器后按i进入insert模式,然后键入以下代码: #include<stdio.h> int main(){ ...
- java细节,细的你想象不到
一. 构造方法每次都是构造出新的对象,不存在多个线程同时读写同一对象中的属性的问题,所以不需要同步 . 如果父类中的某个方法使用了 synchronized关键字,而子类中也覆盖了这个方法,默认情况下 ...
- [HNOI2004]Language L语言
2777: [HNOI2004]Language L语言 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 10 Solved: 5[Submit][S ...
- Python的lambda匿名函数
lambda函数也叫匿名函数,即,函数没有具体的名称.先来看一个最简单例子: def f(x):return x**2print f(4) Python中使用lambda的话,写成这样 g = lam ...