9.XML文件解析
一.XML简介
XML(EXtensible Markup Language),可扩展标记语言
特点:XML与操作系统、编程语言的开发平台无关 实现不同系统之间的数据交换
作用:数据交互 配置应用程序和网站 Ajax基石
二.XML标签
XML文档内容由一系列标签元素组成


语法:
(1)属性值用双引号包裹
(2)一个元素可以有多个属性
(3)属性值中不能直接包含<、“、&(不建议:‘、>)
三.XML编写注意事项
标签编写注意事项
(1)所有XML元素都必须有结束标签
(2)XML标签对大小写敏感
(3)XML必须正确的嵌套
(4)同级标签以缩进对齐
(5)元素名称可以包含字母、数字或其他的字符
(6)元素名称不能以数字或者标点符号开始
(7)元素名称中不能含空格
四.转义符
XML中的转义符列表
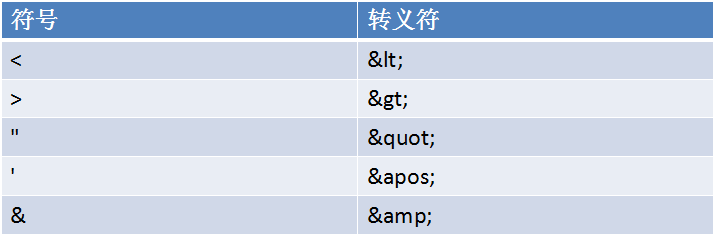
当元素中出现很多特殊字符时,可以使用CDATA节,如: <description> <![CDATA[讲解了元素<title>以及</title>的使用]]> </description>
五.XML解析器
解析器类型
(1)非验证解析器:检查文档格式是否良好
(2)验证解析器:使用DTD检查文档的有效性
六.解析XML技术

七.xml文件的引入
7.1 创建Student.java类
package com.entity;
/**
* 1.创建学生类
* @author pc
*
*/
public class Student {
private int id;
private String name;
private String course;
private int score; public Student() {
}
public Student(int id, String name, String course, int score) {
this.id = id;
this.name = name;
this.course = course;
this.score = score;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCourse() {
return course;
}
public void setCourse(String course) {
this.course = course;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student [course=" + course + ", id=" + id + ", name=" + name
+ ", score=" + score + "]";
} }
Student.java
7.2 创建测试类Test.java
package com.entity;
public class Test {
/**
* @param args
*/
public static void main(String[] args) {
Student mengmeng=new Student(1, "许萌", "java", 98);
Student zhangfujun=new Student(2, "张福军", "java", 98);
System.out.println(mengmeng);
System.out.println(zhangfujun);
}
}
Test.java
7.3 对象映射到xml文件Student.xml
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student id="1">
<name>许萌</name>
<course>java</course>
<score>98</score>
</student>
<student id="2">
<name>张福军</name>
<course>mysql</course>
<score>98</score>
</student>
</students>
Student.xml
八.DtD的创建
(1)声明DTD:<!DOCTYPE 根元素 [定义内容]>
(2)定义dtd元素标签节点:<!ELEMENT 标签名 元素类型>
(3)定义dtd元素标签属性:<!ATTLIST 元素名称 属性名称 属性类型 属性默认值>
(4)ELEMENT 定义标签节点
(5)ATTLIST 定义标签属性
(6)PCDATA 表示属性类型是字符数据
(7)#REQUIRED 属性值是必须的
(8)#IMPLIED 属性值不是必须的
(9)#FIXED 属性值是固定的
(10)(|)给元素分组
(11)A|B 必须选择A或B
(12)A,B 表示A和B按照顺序出现
(13)A* 表示A出现0到n次
(14)A? 表示A出现0到1次
(15)A+ 表示A出现一次或n次
8.1 案例:创建school.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE 学校[
<!ELEMENT 学校 (班级+)>
<!ELEMENT 班级 (名称?,教师+)>
<!ELEMENT 名称 (#PCDATA)>
<!ELEMENT 教师 (#PCDATA)>
]>
<学校>
<班级>
<名称>淘宝31</名称>
<教师>徐娟</教师>
<教师>Holly</教师>
</班级>
</学校>
school.xml
九.DOM解析xml文件

9.1 案例使用DOM读取xml文件
9.1.1 在项目根目录下创建book.xml
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="bk1001">
<title>三国演义</title>
<author>罗贯中</author>
<price>30元</price>
</book>
</books>
book.xml
9.1.2 在com.dom包下下创建DomTest.java
package com.dom; import java.io.IOException; import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException; import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException; /**
* 1.使用dom读取xml文件=解析xml文件
* @author pc
*
*/
public class DomTest {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
//1.得到DOM解析器工厂实例
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
//2.从DOM解析器工厂获取DOM解析器
DocumentBuilder db=dbf.newDocumentBuilder();
//3.读取book.xml文件,转换DOM树(book.xml文件必须放在项目根目录下)
Document doc=db.parse("book.xml");
//4.从DOM树中获取所有根节点列表
NodeList allbooks=doc.getChildNodes();
//5.获取图书节点books
Node booksNode=allbooks.item(0);
//6.获取的books图书节点下的所有子节点列表book
NodeList books=booksNode.getChildNodes();
//7.循环遍历子节点列表信息
for (int i = 0; i < books.getLength(); i++) {
//7.1获取第i个book节点元素
Node book =books.item(i);
//7.2获取book节点下的所有元素节点
NodeList items=book.getChildNodes();
//7.3循环遍历book节点下的所有元素节点
for (int j = 0; j < items.getLength(); j++) {
//7.3.1 获取book节点下的某个元素节点
Node node=items.item(j);
//7.3.2 获取元素节点的名称
String nodeName=node.getNodeName();
//7.3.3 获取元素节点的内容
String nodeConent=node.getTextContent();
//7.3.4判断节点名称获取对应的节点内容
if(nodeName.equals("title")){
System.out.println("书名:"+nodeConent);
}else if(nodeName.equals("author")){
System.out.println("作者:"+nodeConent);
}else if(nodeName.equals("price")){
System.out.println("价格:"+nodeConent);
} } } } }
DomTest.java
9.2 案例使用DOM对xml文件增删改查
9.2.1 在项目根目录下创建student.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<students>
<student id="1">
<name>许萌</name>
<course>java</course>
<score>98</score>
</student>
<student id="2">
<name>张福军</name>
<course>mysql</course>
<score>98</score>
</student>
</students>
Student.xml
9.2.2 在com.dom包下下创建DomTest2.java
package com.dom; import java.io.FileOutputStream;
import java.io.IOException; import javax.print.Doc;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException; /**
* dom4j对xml文件全套增删改查
*
* @author pc
*
*/
public class DomTest2 {
public static void main(String[] args) throws ParserConfigurationException,
SAXException, IOException, TransformerException {
//add();
update();
delete();
select(); } private static void select() throws ParserConfigurationException,
SAXException, IOException {
// 1.创建dom解析器工厂
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 2.从dom工厂获取DOM解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 3.读取student.xml文件,转换为DOM数,该文在必须在项目根目录
Document doc = db.parse("Student.xml");
// 4.从DOM中获取所有根节点列表students
NodeList studentsList = doc.getChildNodes();
// 5.获取第一个根节点studens
Node studentsNode = studentsList.item(0);
// 6.从第一个根节点下获取所有的student子节点列表
NodeList studentList = studentsNode.getChildNodes();
// 7.循环遍历student子节点
for (int i = 0; i < studentList.getLength(); i++) {
// 7.1 获取某个student节点
Node student = studentList.item(i);
// 7.2 获取student节点下所有元素节点列表(name,course,score)
NodeList items = student.getChildNodes();
// 7.3 循环student节点下的所有元素节点
for (int j = 0; j < items.getLength(); j++) {
// 7.3.1 获取某个元素节点(name,course,score)
Node node = items.item(j);
// 7.3.2 获取某个元素节点名称
String nodeName = node.getNodeName();
// 7.3.3 获取某个元素节点的内容
String nodeContent = node.getTextContent();
// 7.3.4 判断根据元素节点名称获取对应元素节点内容
if (nodeName.equals("name")) {
System.out.println("姓名:" + nodeContent);
} else if (nodeName.equals("course")) {
System.out.println("课程:" + nodeContent);
} else if (nodeName.equals("score")) {
System.out.println("成绩:" + nodeContent);
}
} } } private static void add() throws ParserConfigurationException,
SAXException, IOException, TransformerException {
// 1.创建dom解析器工厂
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 2.从dom工厂获取DOM解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 3.读取student.xml文件,转换为DOM数,该文在必须在项目根目录
Document doc = db.parse("Student.xml");
// 4.创建Student节点
Element studentElement = doc.createElement("student");
// 5.为Student节点设置属性
studentElement.setAttribute("id", "3");
// 6.创建name元素节点
Element nameElement = doc.createElement("name");
// 7.为name元素节点添加内容
nameElement.setTextContent("陈金锋");
// 8.将name元素节点放入Student节点
studentElement.appendChild(nameElement);
// 9.创建course元素节点
Element courseElement=doc.createElement("course");
// 10.为course元素节点添加内容
courseElement.setTextContent("JSP");
// 11.将course元素节点添加到Student节点内
studentElement.appendChild(courseElement);
// 12.创建score元素节点
Element scoreElement=doc.createElement("score");
// 13.为score元素节点添加内容
scoreElement.setTextContent("90");
// 14.将score元素节点添加到Student节点内
studentElement.appendChild(scoreElement);
// 15.获取Students根节点(根据节点名获取整个节点)
Element studentsElement=(Element) doc.getElementsByTagName("students").item(0);
// 16.将student节点放入Students根节点中
studentsElement.appendChild(studentElement);
// 17.创建添加节点工厂对象
TransformerFactory transformerFactory=TransformerFactory.newInstance();
// 18.根据添加节点工厂对象创建添加节点对象
Transformer transformer=transformerFactory.newTransformer();
// 19.将整个节点放入内存
DOMSource domSource=new DOMSource(doc);
// 20.设置编码类型
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
// 21.创建输出流对象,并执行写入路径
StreamResult result=new StreamResult(new FileOutputStream("Student.xml"));
// 22.添加节点对象将内存中dom写入文件
transformer.transform(domSource, result);
System.out.println("添加成功!!");
} private static void update() throws ParserConfigurationException, SAXException, IOException, TransformerException {
//1.获取dom解析器工厂对象
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
//2.从DOM解析器工厂获取dom解析器
DocumentBuilder db=dbf.newDocumentBuilder();
//3.读取Student.xml,生成DOM树
Document doc=db.parse("Student.xml");
//4.找到修改的节点所在集合
NodeList studentList=doc.getElementsByTagName("student");
//5.循环遍历修改节点所在集合
for (int i = 0; i < studentList.getLength(); i++) {
//5.1.获取某个student节点
Element studentElement=(Element) studentList.item(i);
//5.2 获取Student节点的id属性值
String studentId=studentElement.getAttribute("id");
//5.3判断Student节点的id值是否是要修改的id为3的节点
if(studentId.equals("3")){
//5.3.1 获取修改的Student节点下的Score元素节点
Element scoreElement=(Element) studentElement
.getElementsByTagName("score").item(0);
//5.3.2 修改score节点文本内容
scoreElement.setTextContent("60");
System.out.println("update is success!");
}
}
//6.创建添加节点工厂对象
TransformerFactory transformerFactory=TransformerFactory.newInstance();
//7.根据添加节点工厂对象创建添加节点对象
Transformer transformer=transformerFactory.newTransformer();
//8.将dom放入内存中
DOMSource domSource=new DOMSource(doc);
//9.设置编码类型
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//10.创建输出流并指定写入路径
StreamResult result=new StreamResult(new FileOutputStream("Student.xml"));
//11.根据添加节点对象将内存中dom树,写入xml文件
transformer.transform(domSource, result);
} private static void delete() throws ParserConfigurationException, SAXException, IOException, TransformerException {
//1.创建dom解析器工厂
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
//2.根据dom解析器工厂创建dom解析器
DocumentBuilder db=dbf.newDocumentBuilder();
//3.读取xml文件,并生成dom树
Document doc=db.parse("Student.xml");
//4.找到所有的student节点集合
NodeList studentList=doc.getElementsByTagName("student");
//5.循环找出要删除的student节点
for (int i = 0; i < studentList.getLength(); i++) {
//5.1 获取某个student节点
Element studentElement=(Element) studentList.item(i);
//5.2 获取某个student节点的id属性
String studentid=studentElement.getAttribute("id");
//5.3 判断id属性值是否是我们要找的id值
if(studentid.equals("3")){
//5.3.1 删除student的id为某个值的整个student节点
studentElement.getParentNode()
.removeChild(studentElement);
System.out.println("delete is success!!");
} }
//6.创建添加节点工厂对象
TransformerFactory transformerFactory=TransformerFactory.newInstance();
//7.根据添加节点工厂对象创建添加节点对象
Transformer transformer=transformerFactory.newTransformer();
//8.将dom放入内存中
DOMSource domSource=new DOMSource(doc);
//9.设置编码类型
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//10.创建输出流并指定写入路径
StreamResult result=new StreamResult(new FileOutputStream("Student.xml"));
//11.根据添加节点对象将内存中dom树,写入xml文件
transformer.transform(domSource, result); } }
DomTest2.java
十.使用DOM4j操作xml文件
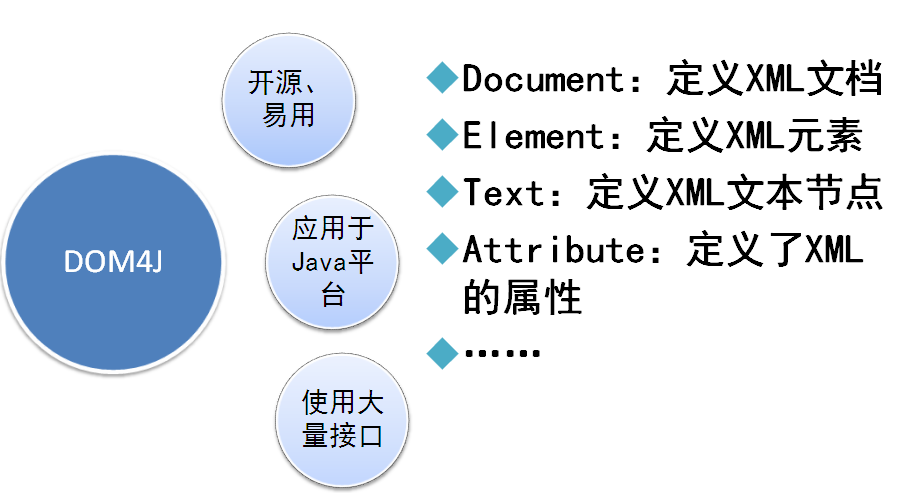
10.1.2 在com.dom4j包下下创建DOM4jParse.java
package com.dom4j; import java.io.File;
import java.util.HashMap;
import java.util.Iterator; import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader; /**
* 使用DOM4j解析xml文件
* @author Holly老师
*
*/
public class DOM4jParse {
public static void main(String[] args) throws DocumentException {
//1.创建HashMap集合,存放解析后的内容
HashMap<String, String> hashMap=new HashMap<String, String>();
//2.获取xml文件所在的路径(System.getProperty("user.dir")=项目真实路径)
String xmlPath=System.getProperty("user.dir")+"\\Student.xml";
/*3.解析xml文件内容到map集合
*(参数分为输入参数和输出参数,)
*输入参数可以是任意类型,
*输出参数只能是引用类型
*/
dom4jParseXml(xmlPath,hashMap);
//4.循环遍历map集合打印内容
for (int i = 0; i < hashMap.size(); i+=3) {
int j=i/3; //第一个student节点
System.out.print(hashMap.get("name"+j)+"\t");
System.out.print(hashMap.get("course"+j)+"\t");
System.out.println(hashMap.get("score"+j)+"\t");
} }
/**
*
* @param xmlPath xml文件路径
* @param hashMap
* @throws DocumentException
*/
private static void dom4jParseXml(String xmlPath,
HashMap<String, String> hashMap) throws DocumentException {
//1.创建读取xml文件的对象(xml输入流对象)
SAXReader saxReader=new SAXReader();
//2.创建文件流指定读取路径
File file=new File(xmlPath);
//3.在指定路径中读取xml文件并转换为dom树
Document document =saxReader.read(file);
//4.获取xml文档的根节点
Element root=document.getRootElement();
//5.定义用于记录学生编号的变量
int num=-1;
//6.获取根元素students下的所有的student放入迭代器集合
Iterator studentList=root.elementIterator();
//7.循环student标签集合
while(studentList.hasNext()){
//获取某个student节点标签
Element studentElement=(Element) studentList.next();
num++;
//获取student标签下的所有元素节点的集合
Iterator studentContentList=studentElement.elementIterator();
//循环获取student标签下元素节点内容
while(studentContentList.hasNext()){
//获取student标签下的某个元素节点
Element studentContent=(Element) studentContentList.next();
//循环将读取到的元素节点内容放入hashmap中(getName()获取标签名,getText()标签文本内容)
hashMap.put(studentContent.getName()+num, studentContent.getText());
}
} } }
DOM4jParse.java
9.XML文件解析的更多相关文章
- 通过正则表达式实现简单xml文件解析
这是我通过正则表达式实现的xml文件解析工具,有些XHTML文件中包含特殊符号,暂时还无法正常使用. 设计思路:常见的xml文件都是单根树结构,工具的目的是通过递归的方式将整个文档树装载进一个Node ...
- 八、Android学习第七天——XML文件解析方法(转)
(转自:http://wenku.baidu.com/view/af39b3164431b90d6c85c72f.html) 八.Android学习第七天——XML文件解析方法 XML文件:exten ...
- android基础知识13:AndroidManifest.xml文件解析
注:本文转载于:http://blog.csdn.net/xianming01/article/details/7526987 AndroidManifest.xml文件解析. 1.重要性 Andro ...
- Android之AndroidManifest.xml文件解析
转自:Android学习笔记之AndroidManifest.xml文件解析 一.关于AndroidManifest.xml AndroidManifest.xml 是每个android程序中必须的文 ...
- Python实现XML文件解析
1. XML简介 XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据,已经日趋成为当前许多新生技术的核心,在不同的领域都有着不同的应用.它是web ...
- Python3将xml文件解析为Python对象
一.说明 从最开始写javascript开始,我就很烦感使用getElementById()等函数来获取节点的方法,获取了一个节点要访问其子孙节点要么child半天要么就再来一个getElementB ...
- XML文件解析-DOM4J方式和SAX方式
最近遇到的工作内容都是和xml内容解析相关的. 1图片数据以base64编码的方式保存在xml的一个标签中,xml文件通过接口的方式发送给我,然后我去解析出图片数据,对图片进行进一步处理. 2.xml ...
- java基础之概谈xml文件解析
XML已经成为一种非常通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便. 诸多web应用框架,其可配置的编程方式,给我们的开发带来了非常大程度的便捷,但细细 ...
- XML文件解析之JDOM解析
1.JDOM介绍 JDOM的官方网站是http://www.jdom.org/,JDOM解析用到的jar包可以在http://www.jdom.org/dist/binary/中下载,最新的JDOM2 ...
随机推荐
- .NET MVC4 实训记录之六(利用ModelMetadata实现资源的自主访问)
上一篇我们已经实现自定义资源文件的访问,该篇我们使用它配合ModelMetadata实现资源文件的自主访问.这样做是为了我们能更简单的用MVC原生的方式使用资源文件.由于我的文章旨在记录MVC项目的实 ...
- C++ builder 中AnsiString的字符串转换方法大全
C++ builder 中AnsiString的字符串转换方法大全 //Ansistring 转 charvoid __fastcall TForm1::Button1Click(TObject *S ...
- 【推荐分享】Python电子书,视频教程(Let's Python系列视频教程等)(百度网盘)
资源都放在百度网盘里了. Python视频教程(Python Django视频教程全集—台湾辅仁大学):http://pan.baidu.com/s/1dDgiWIt Python视频教程(let's ...
- EntityFramework中支持BulkInsert扩展
EntityFramework中支持BulkInsert扩展 本文为 Dennis Gao 原创技术文章,发表于博客园博客,未经作者本人允许禁止任何形式的转载. 前言 很显然,你应该不至于使用 Ent ...
- 重构 ORM 中的 Sql 生成
Rafy 领域实体框架设计 - 重构 ORM 中的 Sql 生成 前言 Rafy 领域实体框架作为一个使用领域驱动设计作为指导思想的开发框架,必然要处理领域实体到数据库表之间的映射,即包含了 OR ...
- 基于python的《Hadoop权威指南》一书中气象数据下载和map reduce化数据处理及其可视化
文档内容: 1:下载<hadoop权威指南>中的气象数据 2:对下载的气象数据归档整理并读取数据 3:对气象数据进行map reduce进行处理 关键词:<Hadoop权威指南> ...
- Push Notification总结系列之移动客户端定位服务
Push Notification系列概括: 1.Push Notification简介和证书说明及生成配置 2.Push Notification的iOS处理代码和Provider详解 3.Push ...
- c/c++操作访问数据,是堆中的数据快还是栈中的数据快
这里的问题其实问的是对堆与栈的数据访问有什么不同. 观察如下代码: #include<stdio.h> #include<iostream> using namespace s ...
- js框架漫谈
现在实际项目中可供选择的javascript框架很多,热门的有jquery,dojo,mootools,ext等.这些框架按照不同的标准有不同的分类方法,比如按照扩展方式便可分为prototype式的 ...
- 设计师和开发人员更快完成工作需求的20个惊人的jqury插件教程(上)
[转] 设计师和开发人员更快完成工作需求的20个惊人的jqury插件教程(上) jquery的功能总是那么的强大,用他可以开发任何web和移动框架,在浏览器市场,他一直是占有重要的份额,今天,就给大家 ...