Hadoop Mapreduce刮
前言
Hadoop简单介绍
File System)和MapReduce。MapReduce就是“任务的分解与结果的汇总”。HDFS为分布式计算存储提供了底层支持。
Tips
HDFS架构
HDFS採用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心server,负责管理文件系统的名字空间(namespace)以及client对文件的訪问。集群中的Datanode通常是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户可以以文件的形式在上面存储数据。从内部看。一个文件事实上被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode运行文件系统的名字空间操作,比方打开、关闭、重命名文件或文件夹。
它也负责确定数据块到详细Datanode节点的映射。Datanode负责处理文件系统client的读写请求。
在Namenode的统一调度下进行数据块的创建、删除和复制。
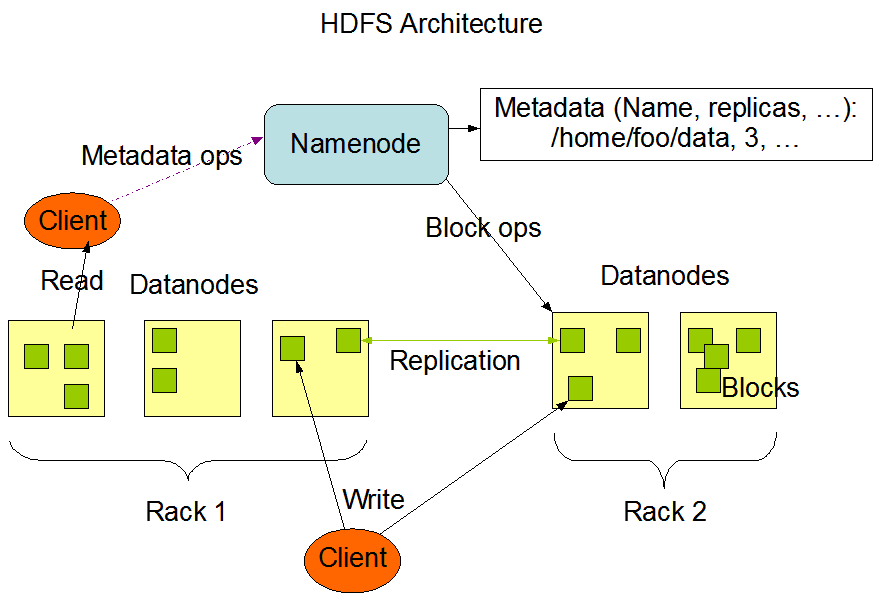
Namenode和Datanode被设计成能够在普通的商用机器上执行。这些机器一般执行着GNU/Linux操作系统(OS)。HDFS採用Java语言开发,因此不论什么支持Java的机器都能够部署Namenode或Datanode。
因为採用了可移植性极强的Java语言。使得HDFS能够部署到多种类型的机器上。
一个典型的部署场景是一台机器上仅仅执行一个Namenode实例,而集群中的其他机器分别执行一个Datanode实例。这种架构并不排斥在一台机器上执行多个Datanode。仅仅只是这种情况比較少见。集群中单一Namenode的结构大大简化了系统的架构。
Namenode是全部HDFS元数据的仲裁者和管理者。这样,用户数据永远不会流过Namenode。
MapReduce
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序可以执行在由上千个商用机器组成的大型集群上。并以一种可靠容错的方式并行处理上T级别的数据集。
一个Map/Reduce 作业(job) 一般会把输入的数据集切分为若干独立的数据块,由 map任务(task)以全然并行的方式处理它们。框架会对map的输出先进行排序, 然后把结果输入给reduce任务。
通常作业的输入和输出都会被存储在文件系统中。 整个框架负责任务的调度和监控,以及又一次运行已经失败的任务。
通常。Map/Reduce框架和分布式文件系统是执行在一组同样的节点上的,也就是说。计算节点和存储节点通常在一起。这样的配置同意框架在那些已经存好数据的节点上高效地调度任务。这能够使整个集群的网络带宽被很高效地利用。
Map/Reduce框架由一个单独的master JobTracker 和每一个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的全部任务,这些任务分布在不同的slave上,master监控它们的运行,又一次运行已经失败的任务。而slave仅负责运行由master指派的任务。
应用程序至少应该指明输入/输出的位置(路径)。并通过实现合适的接口或抽象类提供map和reduce函数。
再加上其它作业的參数,就构成了作业配置(job configuration)。然后。Hadoop的 job client提交作业(jar包/可运行程序等)和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务并监控它们的运行,同一时候提供状态和诊断信息给job-client。
尽管Hadoop框架是用JavaTM实现的。但Map/Reduce应用程序则不一定要用 Java来写 。Hadoop Streaming是一种执行作业的有用工具,它同意用户创建和执行不论什么可执行程序 (比如:Shell工具)来做为mapper和reducer。Hadoop
Pipes是一个与SWIG兼容的C++ API (没有基于JNITM技术),它也可用于实现Map/Reduce应用程序。
可能诸位看到这里也不知道MapReduce是用来干啥的,举个比較经典的样例。给若干篇文章,须要归纳出每一个单词出现的次数。用MapReduce统计是这种过程:首先对每篇文章进行处理,处理成<word, 1>的k/v对(由于对于每一个单词,出现一次就有一个word,1的键值对),经过处理后会有一张大列表,列表中的每一个元素就是一个键值对,接着进行排序,依照key的字典序进行排序。排序之后,对这个大表进行切割,切割到不同的机器上进行统计。每一个节点统计之后再merge到一起得到终于的结果。详细例如以下:
第一篇文章 I am a boy.
第二篇文章 I am a girl.
第一篇文章处理之后的列表:
I 1
am 1
a 1
boy 1
第二篇文章处理后的列表:
I 1
am 1
a 1
girl 1
这两篇文章的列表合并起来得到一个大表:
I 1
am 1
a 1
boy 1
I 1
am 1
a 1
girl 1
依照key的字典序进行排序:
a 1
a 1
am 1
am 1
boy 1
girl 1
I 1
I 1
接着将前4行和后四行分别给两个reduce。
第一个reduce统计的结果:
am 2
I 2
第二个reduce统计的结果:
a 2
boy 1
girl 1
两个reduce统计的结果merge:
a 2
am 2
boy 1
girl 1
I 2
这样就得到了终于的结果。
Hadoop部署(没有自己造轮子,在别人部署好的基础上直接使用了)
Hadoop经常使用命令
MapReduce用法
MapReduce流程

1.在client启动一个作业。
2.向JobTracker请求一个Job ID。
3.将执行作业所须要的资源文件拷贝到HDFS上,包含MapReduce程序打包的JAR文件、配置文件和client计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的目录中。
目录名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4.JobTracker接收到作业后,将其放在一个作业队列里。等待作业调度器对其进行调度(这里是不是非常像微机中的进程调度呢。呵呵),当作业调度器依据自己的调度算法调度到该作业时,会依据输入划分信息为每一个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务。TaskTracker依据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里须要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。
意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同一时候将程序JAR包拷贝到该TaskTracker上来执行,这叫“运算移动。数据不移动”。而分配reduce任务时并不考虑数据本地化。
5.TaskTracker每隔一段时间会给JobTracker发送一个心跳。告诉JobTracker它依旧在执行。同一时候心跳中还携带着非常多的信息。比方当前map任务完毕的进度等信息。当JobTracker收到作业的最后一个任务完毕信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完毕,便显示一条消息给用户。
以上是在client、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,以下我们再仔细一点,从map任务和reduce任务的层次来分析分析吧。
Map、Reduce任务中Shuffle和排序的过程

Map端:
1.每一个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默觉得64M)为一个分片,当然我们也能够设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默觉得100M,由io.sort.mb属性控制)。当该缓冲区快要溢出时(默觉得缓冲区大小的80%。由io.sort.spill.percent属性控制)。会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前。线程首先依据reduce任务的数目将数据划分为同样数目的分区,也就是一个reduce任务相应一个分区的数据。
这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到非常少数据,甚至没有分到数据的尴尬局面。
事实上分区就是对数据进行hash的过程。
然后对每一个分区中的数据进行排序,假设此时设置了Combiner。将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时。可能会有非常多的溢出文件。这时须要将这些文件合并。
合并的过程中会不断地进行排序和combia操作。目的有两个:1.尽量降低每次写入磁盘的数据量;2.尽量降低下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了降低网络传输的数据量,这里能够将数据压缩。仅仅要将mapred.compress.map.out设置为true就能够了。
4.将分区中的数据拷贝给相相应的reduce任务。有人可能会问:分区中的数据怎么知道它相应的reduce是哪个呢?事实上map任务一直和其父TaskTracker保持联系。而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。仅仅要reduce任务向JobTracker获取相应的map输出位置就ok了哦。
到这里,map端就分析完了。那究竟什么是Shuffle呢?Shuffle的中文意思是“洗牌”。假设我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务。是不是一个对数据洗牌的过程呢?呵呵。
Reduce端:
1.Reduce会接收到不同map任务传来的数据。而且每一个map传来的数据都是有序的。
假设reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制。表示用作此用途的堆空间的百分比),假设数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多。后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。事实上无论在map端还是reduce端,MapReduce都是重复地运行排序,合并操作。如今最终明确了有些人为什么会说:排序是hadoop的灵魂。
3.合并的过程中会产生很多的中间文件(写入磁盘了)。但MapReduce会让写入磁盘的数据尽可能地少,而且最后一次合并的结果并没有写入磁盘。而是直接输入到reduce函数。
MapReduce实战
streaming
比如:
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input myInputDirs \
-output myOutputDir \
-mapper /bin/cat \ 这里用/bin/cat命令当做mapper
-reducer /bin/wc 这里用/bin/wc命令当做reducer
这里我们用C++写mapper和reducer。
mapper.cc
#include <iostream>
#include <string>
using namespace std;
int main(){
string str;
while(cin>>str){
cout<<str<<" "<<"1"<<endl;
}
return 0;
}reducer.cc
#include <iostream>
#include <map> using namespace std;
int main(){
map<string, int> wordCount;
map<string, int>::iterator it;
string key;
int value;
int count;
while(cin>>key>>value) {
wordCount[key] += value;
}
for(it = wordCount.begin(); it != wordCount.end(); it++){
cout<<it->first<<" "<<it->second<<" fuck!"<<endl;
}
return 0;
}input文件内容
hello
hello
hello
world
world提交作业脚本(命令非常长,所以写成一个脚本方便点)mapreduce.sh
#!/bin/bash input="/user/serving/zhuzekun/input" #这里要保证input已经put到hadoop的/user/serving/zhuzekun/下
output="/user/serving/zhuzekun/output/" SPLIT_SIZE=1000000000
MAP_CAP=300
REDUCE_CAP=300
NUM_MAP=50
NUM_REDUCE=5 hadoop_home_path="/home/serving/hadoop_client/hadoop"
hadoop_bin="${hadoop_home_path}/bin/hadoop"
hadoop_streaming_file="${hadoop_home_path}/contrib/streaming/hadoop-streaming-1.2.0.jar" ${hadoop_bin} fs -rmr ${output}
${hadoop_bin} jar ${hadoop_streaming_file} \
-partitioner "org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner" \
-jobconf stream.num.map.output.key.fields=1 \
-jobconf num.key.fields.for.partition=1 \
-input ${input} \
-output ${output} \
-mapper "mapper" \
-file "mapper" \
-reducer "reducer" \
-file "reducer" \
-jobconf stream.map.output.field.separator=" " \
-jobconf mapred.job.map.capacity=${MAP_CAP} \
-jobconf mapred.job.reduce.capacity=${REDUCE_CAP} \
-jobconf mapred.map.tasks=${NUM_MAP} \
-jobconf mapred.reduce.tasks=${NUM_REDUCE}\
-jobconf mapred.min.split.size=${SPLIT_SIZE} \
-jobconf mapred.job.name="MP" \
-jobconf mapred.job.priority=NORMAL if [ $? -ne 0 ]; then
exit 1
fi
rm -rf /data8/zhuzekun/merge
${hadoop_bin} fs -getmerge ${output} /data8/zhuzekun/merge流程:
- g++ -o mapper mapper.cc 编译出mapper可运行文件
- g++ -o reducer reducer.cc 编译出reducer可运行文件
- sh mapreduce.sh 运行提交作业脚本
- 等运行完之后会在/data8/zhuzekun/目录下产生一个merge文件,里面保存着结果。
awk脚本与streaming
在实际工作中,经常对大量的日志进行处理,awk能方便地处理日志。awk详细解说看http://zh.wikipedia.org/wiki/AWK。上文提到streaming的mapper和reducer能够是脚本文件。awk脚本属于当中一种。两者结合能方便地处理日志。这里以统计日志中每一个ip的訪问次数为例。解说awk脚本怎样应用在MapReduce中。mapper.awk
BEGIN{
FS=" ";
} {
printf("%s %d\n", $11, 1); #日志文件的第11列是ip
} END{ }reducer.awk
BEGIN{
FS=" ";
} {
word_count[$1] += $2;
} END{
for(i in word_count){
printf("%s %d\n", i, word_count[i]);
}
}mapreduce.sh#!/bin/bash input="/user/serving/log/aries/merged/20140715.st/part-00999"
output="/user/serving/zhuzekun/output/" SPLIT_SIZE=1000000000
MAP_CAP=300
REDUCE_CAP=300
NUM_MAP=50
NUM_REDUCE=5 hadoop_home_path="/home/serving/hadoop_client/hadoop"
hadoop_bin="${hadoop_home_path}/bin/hadoop"
hadoop_streaming_file="${hadoop_home_path}/contrib/streaming/hadoop-streaming-1.2.0.jar" ${hadoop_bin} fs -rmr ${output}
${hadoop_bin} jar ${hadoop_streaming_file} \
-partitioner "org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner" \
-jobconf stream.num.map.output.key.fields=1 \
-jobconf num.key.fields.for.partition=1 \
-input ${input} \
-output ${output} \
-mapper "awk -f mapper.awk" \
-file "mapper.awk" \
-reducer "awk -f reducer.awk" \
-file "reducer.awk" \
-jobconf stream.map.output.field.separator=" " \
-jobconf mapred.job.map.capacity=${MAP_CAP} \
-jobconf mapred.job.reduce.capacity=${REDUCE_CAP} \
-jobconf mapred.map.tasks=${NUM_MAP} \
-jobconf mapred.reduce.tasks=${NUM_REDUCE}\
-jobconf mapred.min.split.size=${SPLIT_SIZE} \
-jobconf mapred.job.name="MP" \
-jobconf mapred.job.priority=NORMAL if [ $? -ne 0 ]; then
exit 1
fi
rm -rf /data8/zhuzekun/merge
${hadoop_bin} fs -getmerge ${output} /data8/zhuzekun/merge运行mapreduce脚本就能够上传统计ip次数的作业了。
小结
通过两个小demo。实现了简单的mapreduce作业。有了入门之后,剩下的都是万变不离其宗了。无非是逻辑结构、实现方式更复杂一些罢了。
版权声明:本文博客原创文章,博客,未经同意,不得转载。
Hadoop Mapreduce刮的更多相关文章
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce例子-新版API多表连接Join之模仿订单配货
文章为作者原创,未经许可,禁止转载. -Sun Yat-sen University 冯兴伟 一. 项目简介: 电子商务的发展以及电商平台的多样化,类似于京东和天猫这种拥有过亿用户的在线购 ...
- Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simpleMapReduce program for Hadoop in thePython prog ...
- Hadoop MapReduce编程学习
一直在搞spark,也没时间弄hadoop,不过Hadoop基本的编程我觉得我还是要会吧,看到一篇不错的文章,不过应该应用于hadoop2.0以前,因为代码中有 conf.set("map ...
- Hadoop MapReduce概念学习系列之mr程序组件全貌(二十)
其实啊,spilt是,控制Apache Hadoop Mapreduce的map并发任务数,详细见http://www.cnblogs.com/zlslch/p/5713652.html map,是m ...
随机推荐
- Mutex(测量)
游标共享怎样使用Mutex kks 使用mutex以便保护对于下述基于parent cursor父游标和子游标child cursor的一系列操作 对于父游标parent cursor的操作: 基于发 ...
- Trie图和Fail树
Trie图和AC自动机的区别 Trie图是AC自动机的确定化形式,即把每个结点不存在字符的next指针都补全了.这样做的好处是使得构造fail指针时不需要next指针为空而需要不断回溯. 比如构造ne ...
- php集成环境
apache+php+mysql是常见php环境,在windows下也称为WAMP,对于初学者自选版本搭建总是会遇到一些麻烦,下面是收集到的一些集成环境安装: 1.AppServ (推荐,简洁精简) ...
- 用XAML做网页!!—框架
原文:用XAML做网页!!-框架 上一篇中我进行了一下效果展示和概述,此篇开始将重现我此次尝试的步骤,我想大家通过阅读这些步骤,可以了解到XAML网页排版的方法. 下面就开始编写XAML,首先来定义一 ...
- Codeforces Round #277.5 (Div. 2)---B. BerSU Ball (贪心)
BerSU Ball time limit per test 1 second memory limit per test 256 megabytes input standard input out ...
- php如何判断用户是从指定页面跳转进来的
$_SERVER['HTTP_REFERER']下'HTTP_REFERER' 引导用户代理到当前页的前一页的地址(如果存在).由 user agent 设置决定.并不是所有的用户代理都会设置该项,有 ...
- VMware虚拟机上网络连接(network type)的三种模式--bridged、host-only、NAT
VMware虚拟机上网络连接(network type)的三种模式--bridged.host-only.NAT VMWare提供了三种工作模式,它们是bridged(桥接模式).NAT(网络地址转换 ...
- win7提示“ipconfig不是内部或外部命令”
进入windows环境变量设置->系统变量,找到path,添加C:\Windows\SysWOW64,或者c:\windows\system32
- hdu4336压缩率大方的状态DP
Card Collector Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) T ...
- .NET 单点登录
<appSettings> <!--是否启用单点登录接口--> <add key="IsStartCas" value="f ...