爬虫_拉勾网(selenium)
使用selenium进行翻页获取职位链接,再对链接进行解析
会爬取到部分空列表,感觉是网速太慢了,加了time.sleep()还是会有空列表
- from selenium import webdriver
- import requests
- import re
- from lxml import etree
- import time
- from selenium.webdriver.support.ui import WebDriverWait
- from selenium.webdriver.support import expected_conditions as EC
- from selenium.webdriver.common.by import By
- class LagouSpider(object):
- def __init__(self):
- opt = webdriver.ChromeOptions()
- # 把chrome设置成无界面模式
- opt.set_headless()
- self.driver = webdriver.Chrome(options=opt)
- self.url = 'https://www.lagou.com/jobs/list_爬虫?px=default&city=北京'
- self.headers = {
- 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
- }
- def run(self):
- self.driver.get(self.url)
- while True:
- html = ''
- links = []
- html = self.driver.page_source
- links = self.get_one_page_links(html)
- for link in links:
- print('\n' + link+'\n')
- self.parse_detail_page(link)
- WebDriverWait(self.driver, 10).until(
- EC.presence_of_element_located((By.CLASS_NAME, 'pager_next')))
- next_page_btn = self.driver.find_element_by_class_name('pager_next')
- if 'pager_next_disabled' in next_page_btn.get_attribute('class'):
- break
- else:
- next_page_btn.click()
- time.sleep(1)
- def get_one_page_links(self, html):
- links = []
- hrefs = self.driver.find_elements_by_xpath('//a[@class="position_link"]')
- for href in hrefs:
- links.append(href.get_attribute('href'))
- return links
- def parse_detail_page(self, url):
- job_information = {}
- response = requests.get(url, headers=self.headers)
- time.sleep(2)
- html = response.text
- html_element = etree.HTML(html)
- job_name = html_element.xpath('//div[@class="job-name"]/@title')
- job_description = html_element.xpath('//dd[@class="job_bt"]//p//text()')
- for index, i in enumerate(job_description):
- job_description[index] = re.sub('\xa0', '', i)
- job_address = html_element.xpath('//div[@class="work_addr"]/a/text()')
- job_salary = html_element.xpath('//span[@class="salary"]/text()')
- # 字符串处理去掉不必要的信息
- for index, i in enumerate(job_address):
- job_address[index] = re.sub('查看地图', '', i)
- while '' in job_address:
- job_address.remove('')
- job_information['job_name'] = job_name
- job_information['job_description'] = job_description
- job_information['job_address'] = job_address
- job_information['job_salary'] = job_salary
- print(job_information)
- def main():
- spider = LagouSpider()
- spider.run()
- if __name__ == '__main__':
- main()
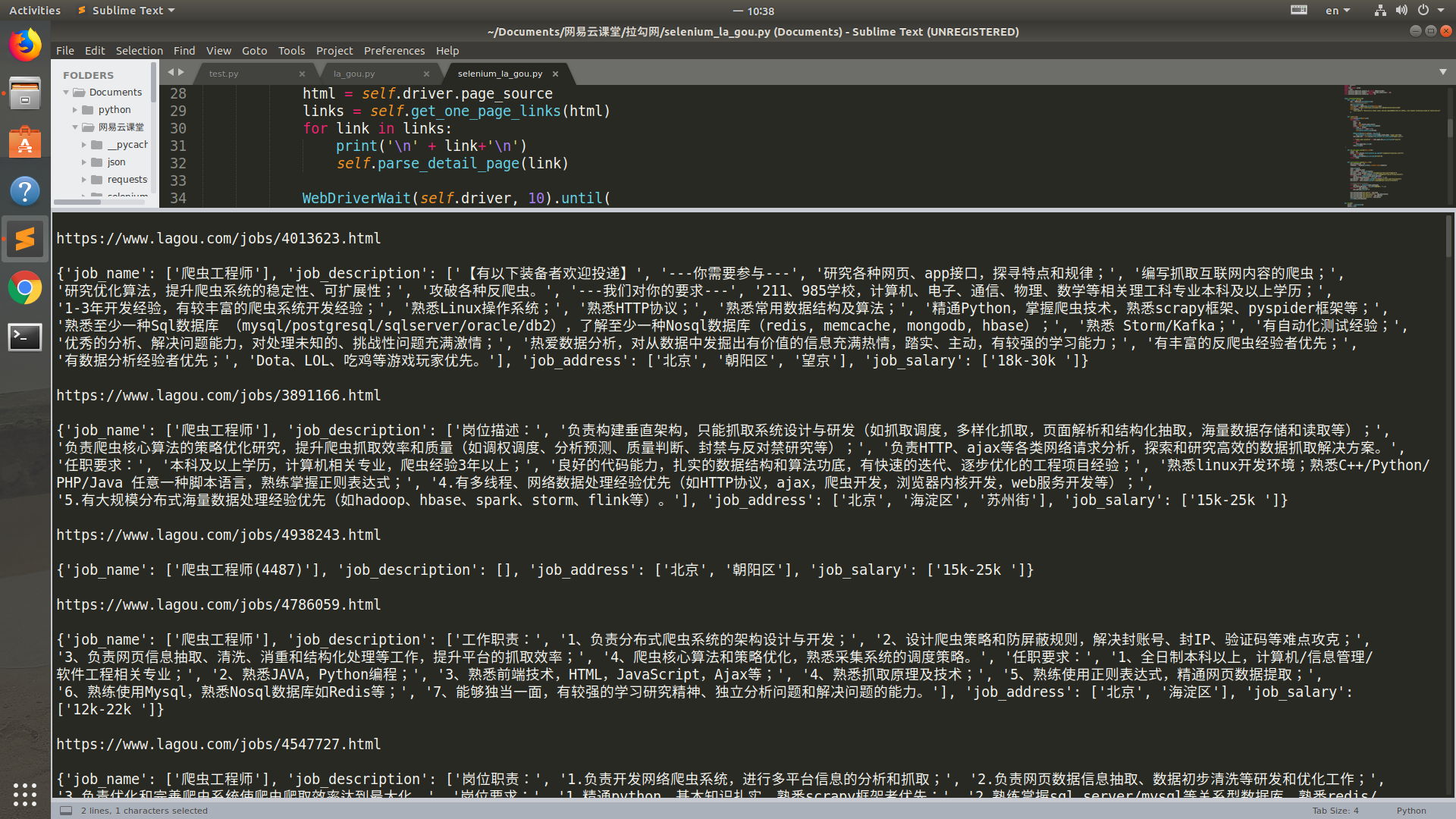
运行结果
爬虫_拉勾网(selenium)的更多相关文章
- 爬虫_拉勾网(解析ajax)
拉勾网反爬虫做的比较严,请求头多添加几个参数才能不被网站识别 找到真正的请求网址,返回的是一个json串,解析这个json串即可,而且注意是post传值 通过改变data中pn的值来控制翻页 job_ ...
- python爬虫动态html selenium.webdriver
python爬虫:利用selenium.webdriver获取渲染之后的页面代码! 1 首先要下载浏览器驱动: 常用的是chromedriver 和phantomjs chromedirver下载地址 ...
- scrapy爬虫框架和selenium的配合使用
scrapy框架的请求流程 scrapy框架? Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架.因此Scrapy使用了一种非阻塞(又名异步)的 ...
- Python爬虫之设置selenium webdriver等待
Python爬虫之设置selenium webdriver等待 ajax技术出现使异步加载方式呈现数据的网站越来越多,当浏览器在加载页面时,页面上的元素可能并不是同时被加载完成,这给定位元素的定位增加 ...
- # Python3微博爬虫[requests+pyquery+selenium+mongodb]
目录 Python3微博爬虫[requests+pyquery+selenium+mongodb] 主要技术 站点分析 程序流程图 编程实现 数据库选择 代理IP测试 模拟登录 获取用户详细信息 获取 ...
- 爬虫_淘宝(selenium)
总体来说代码还不是太完美 实现了js渲染网页的解析的一种思路 主要是这个下拉操作,不能一下拉到底,数据是在中间加载进来的, 具体过程都有写注释 from selenium import webdriv ...
- 爬虫基础(三)-----selenium模块应用程序
摆脱穷人思维 <三> : 培养"目标导向"的思维: 好项目永远比钱少,只要目标正确,钱总有办法解决. 一 selenium模块 什么是selenium?seleni ...
- PYTHON 爬虫笔记七:Selenium库基础用法
知识点一:Selenium库详解及其基本使用 什么是Selenium selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium ...
- python3[爬虫实战] 使用selenium,xpath爬取京东手机
使用selenium ,可能感觉用的并不是很深刻吧,可能是用scrapy用多了的缘故吧.不过selenium确实强大,很多反爬虫的都可以用selenium来解决掉吧. 思路: 入口: 关键字搜索入口 ...
随机推荐
- UVA -580 组合数学
#include<iostream> #include<stdio.h> #include<string.h> #include<algorithm> ...
- 小小知识点(二)——如何修改win10 的C盘中用户下的文件夹名称
1.以管理员身份登录计算机 在win10桌面的开始界面处有个用户头像,点击在里面找到administrator: 如果没有,则需进行如下设置: (1)右键计算机,双击管理,找到如下所示的用户中的adm ...
- Python_架构、同一台电脑上两个py文件通信、两台电脑如何通信、几十台电脑如何通信、更多电脑之间的通信、库、端口号
1.架构 C/S架构(鼻祖) C:client 客户端 S:server 服务器 早期使用的一种架构,目前的各种app使用的就是这种架构,它的表现形式就是拥有专门的app. B/S架构(隶属于C/ ...
- JavaScript修改DOM节点时,样式优先级的问题
通过element.style.xxx设置或者读取的xxx样式属性,都是属于行间样式(<p style="color=red"></p>),并不是 使用li ...
- git [command line] fatal: Authentication failed for
fatal: Authentication failed for https://www.jianshu.com/p/8a7f257e07b8 git.exe fetch -v --progress ...
- PHP优化与提升
一.十个不错的建议 1.使用 ip2long() 和 long2ip() 函数来把 IP 地址转化成整型存储到数据库里.这种方法把存储空间降到了接近四分之一(char(15) 的 15 个字节对整形的 ...
- [转帖]浅谈程序中的text段、data段和bss段
作者:百问科技链接:https://zhuanlan.zhihu.com/p/28659560来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 一般情况,一个程序本质上都 ...
- Laravel渴求式加载(比较容易理解理解load与with关系)
渴求式加载 当以属性方式访问 Eloquent关联关系的时候,关联关系数据是「懒惰式加载」的,这意味着关联关系数据直到第一次访问的时候才被加载.不过,Eloquent 还可以在查询父级模型的同时「渴求 ...
- 在layui中使用ajax不起作用
又是一个坑,坑了我一个下午.在layui插件中使用jquery的ajax请求,一点反应都没有,不管是改成get还是post请求,后台毫无反应,前端谷歌调试也没有报半点错. js代码如下: layui. ...
- C++中String类的字符串分割实现
最近笔试,经常遇到需要对字符串进行快速分割的情景,主要是在处理输入的时候,而以前练习算法题或笔试,很多时候不用花啥时间考虑测试用例输入的问题.可是C++标准库里面没有像java的String类中提供的 ...