一脸懵逼搭建Zookeeper分布式集群
1:首先将http://zookeeper.apache.org/
下载好的zookeeper-3.4.5.tar.gz上传到三台虚拟机上,之前博客搭建好的(安装Zookeeper之前记得安装好你的jdk哦)。
2:然后对zookeeper-3.4.5.tar.gz进行解压缩操作:
[hadoop@master ~]$ tar -zxvf zookeeper-3.4.5.tar.gz

3:然后进入conf目录(将zoo_sample.cfg修改为zoo.cfg):
mv修改名称或者cp一个,老的作为样本:

4:然后打开zoo.cfg文件:

修改一些配置:
tickTime=2000 心跳间隔
initLimit=10 初始容忍的心跳数
syncLimit=5 等待最大容忍的心跳数
dataDir=/tmp/zookeeper 本地保存数据的目录,tmp存放的临时数据,可以修改为自己的目录;
clientPort=2181 客户端默认端口号
如果有需要,我感觉加上日志很有必要,如果出错了,还有地方可以去查找:
dataLogDir=/home/hadoop/zookeeper/log

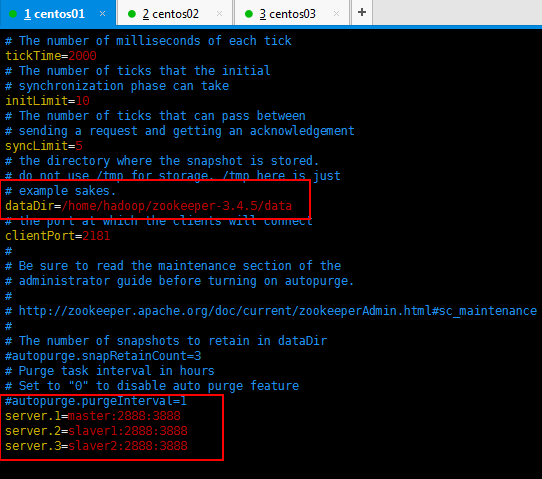
修改后的如下所示(红色圈起来的是修改的):
server.1=master:2888:3888 (主机名, 心跳端口、数据端口)
server.2=slave1:2888:3888
server.3=slave2:2888:3888
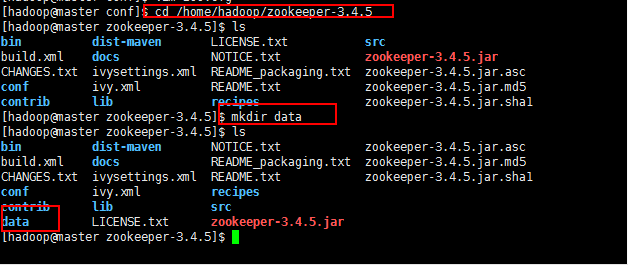
5:由于需要事先创建好data目录,所以现在创建data目录:
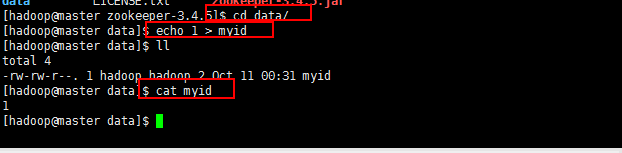
然后在data目录创建一个文件myid,里面写一个1,如下所示:
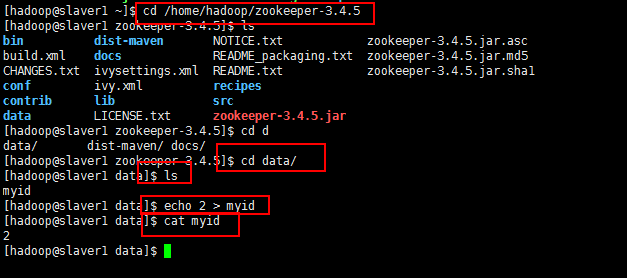
5:然后将修改好的复制到slaver1和slaver2上面


然后分别将slaver1和slaver2的myid修改为2和3,如下所示:
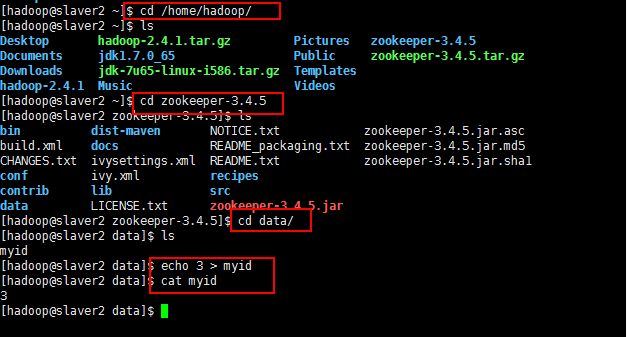
6:至此Zookeeper搭建结束,下面开始启动Zookeeper,分别启动:
如果你不想切换到Zookeeper目录启动,可以配置环境变量:
vi /etc/profile(修改文件)
export ZOOKEEPER_HOME=/home/hadoop/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
重新编译文件:
source /etc/profile
注意:3台zookeeper都需要修改
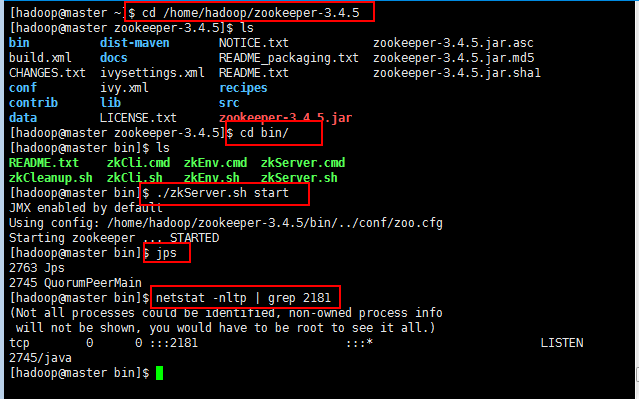
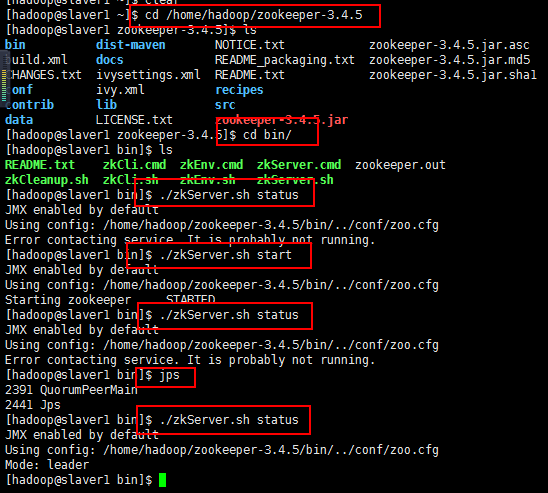
少于三台不会正常工作的,可以通过命令查询状态:

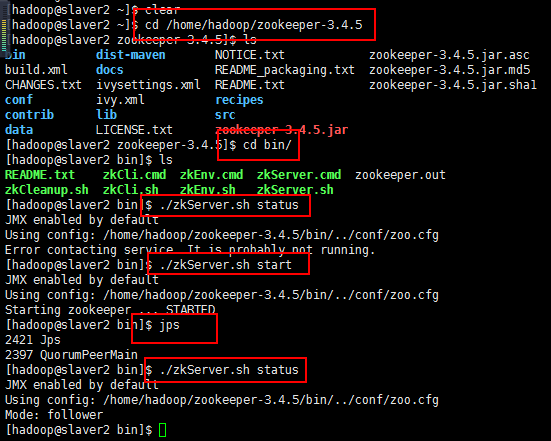
7:接下来启动slaver1和slaver2的服务:

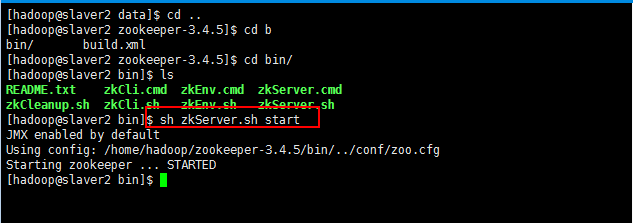
三台机器启动完成以后,可以查看其状态,开始报这个错,就是启动不了Zookeeper,然后百度呗,百度很多方法,还存在版本问题,新生事物永远在争议中成长,name百度的也没帮助我解决,最后重启三台机器,问题解决:
2018/4/8,记录,如果重启没有解决问题,可以将自己建的data目录下面的zookeeper_server.pid文件删除后重新启动。记住关闭防火墙。
JMX enabled by default//
Using config: /home/hadoop/zookeeper-3.4./bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
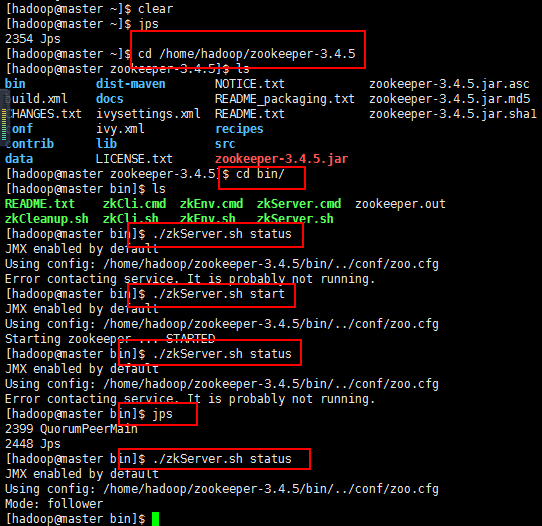
上面的是master节点的,下面的是slaver1节点和slaver2节点的(对于出现这个启动不了的问题,我是这样想的,如果百度的方法不行,就重启一下,
重启以后我开始启动master节点的,然后查看状态,肯定没启动起来,正常,查看一下进程jps,
然后启动slaver1节点的,然后查看状态,肯定没启动起来,正常,查看一下进程jps,
然后启动slaver2节点的,然后查看状态,肯定启动起来,正常,查看一下进程jps,正常,
如果没启动起来,估计问题不好弄了都,我的就解决到这里吧!):
8:至此,Zookerper集群就启动起来了,然后就可以通过java的api往里面写数据,注入分布式应用让Zookerper协调的数据,或者使用命令行的客户端zkCli.sh模式,zkCli.sh连到集群上面去访问数据,可以用来做测试(不带参数连接到本节点上面去):

Connecting to localhost:2181
2017-10-11 02:39:39,035 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.5-1392090, built on 09/30/2012 17:52 GMT
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:host.name=slaver2
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.7.0_65
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/home/hadoop/jdk1.7.0_65/jre
2017-10-11 02:39:39,040 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/home/hadoop/zookeeper-3.4.5/bin/../build/classes:/home/hadoop/zookeeper-3.4.5/bin/../build/lib/*.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/slf4j-log4j12-1.6.1.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/slf4j-api-1.6.1.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/netty-3.2.2.Final.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/log4j-1.2.15.jar:/home/hadoop/zookeeper-3.4.5/bin/../lib/jline-0.9.94.jar:/home/hadoop/zookeeper-3.4.5/bin/../zookeeper-3.4.5.jar:/home/hadoop/zookeeper-3.4.5/bin/../src/java/lib/*.jar:/home/hadoop/zookeeper-3.4.5/bin/../conf:
2017-10-11 02:39:39,041 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/i386:/lib:/usr/lib
2017-10-11 02:39:39,041 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2017-10-11 02:39:39,041 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA>
2017-10-11 02:39:39,044 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2017-10-11 02:39:39,044 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=i386
2017-10-11 02:39:39,044 [myid:] - INFO [main:Environment@100] - Client environment:os.version=2.6.32-358.el6.i686
2017-10-11 02:39:39,044 [myid:] - INFO [main:Environment@100] - Client environment:user.name=hadoop
2017-10-11 02:39:39,045 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/home/hadoop
2017-10-11 02:39:39,046 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/home/hadoop/zookeeper-3.4.5/bin
2017-10-11 02:39:39,047 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@1a685ae
Welcome to ZooKeeper!
2017-10-11 02:39:39,096 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@966] - Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (unknown error)
JLine support is enabled
2017-10-11 02:39:39,111 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@849] - Socket connection established to localhost/0:0:0:0:0:0:0:1:2181, initiating session
2017-10-11 02:39:39,241 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1207] - Session establishment complete on server localhost/0:0:0:0:0:0:0:1:2181, sessionid = 0x35f0ac132690000, negotiated timeout = 30000WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
连接到本节点的2181端口之后向集群里面写任何数据,在另外两个节点都可以看到(Zookerper管理客户所存放的数据采用的是类似于文件树的结构):
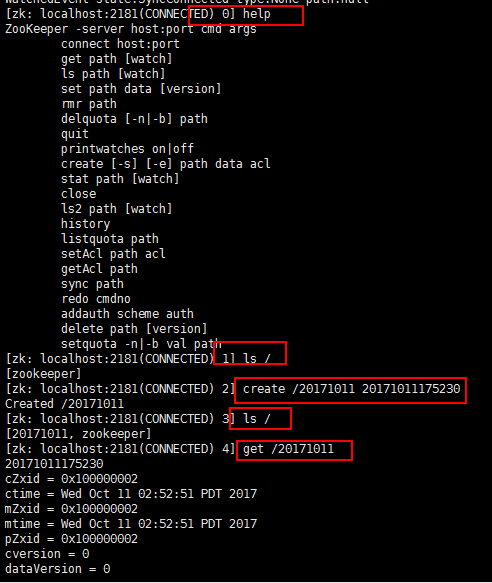
在其他节点也可以看到的:

9:ssh远程开启Zookeeper服务:
[root@master bin]# ssh slaver2 "source /etc/profile;/home/hadoop/soft/zookeeper-3.4.5/bin/zkServer.sh start"
10:Zookeeper启动自动化脚本:
#export a= 定义的变量,会对自己所在的sheel进程及其子进程生效。
#a= 定义的变量,只对自己所在的sheel进行生效。
#在script.sh中定义的变量,在当前登陆的sheel进行中,source script.sh时,脚本中定义的变量也会进入当前登陆的进程 #!/bin/bash
echo "start zkServer..."
for i in
do
ssh slaver$i "source /etc/profile;/home/hadoop/soft/zookeeper-3.4.5/bin/zkServer.sh start"
done
个人配置自动化脚本执行的操作步骤:
首先在我个人喜欢的目录下面/home/hadoop目录下面创建一个叫做脚本的文件夹,script,然后将自动化脚本拷贝到新建的startzk.sh文件中,然后配置环境变量:
export JAVA_HOME=/home/hadoop/soft/jdk1..0_65 export ZOOKEEPER_HOME=/home/hadoop/soft/zookeeper-3.4. #自动化脚本的目录
export SCRIPT=/home/hadoop/script #添加到全局环境变量中即可。
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$SCRIPT
然后在任意目录,执行startzk.sh就可以启动三台Zookeeper了。
但是呢,如果上面你都弄好了,自动化脚本写好了,环境变量配置好了,使用的使用,出现如下问题:
bash: /home/hadoop/script/startzk.sh: Permission denied
上面问题,老司机一眼就明白要干嘛了,那么现在使用chmod 777 startzk.sh命令和chmod 777 stopzk.sh命令赋予你的脚本执行权限即可。
注意:配置好自动化脚本,按tab键不自动弹出,可能是不可以执行的问题,可以赋予文件相应执行权限即可。
待续.....
一脸懵逼搭建Zookeeper分布式集群的更多相关文章
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- Zookeeper分布式集群搭建
实验条件:3台安装linux的机子,配置好Java环境. 步骤1:下载并分别解包到每台机子的/home/iHge2k目录下,附上下载地址:http://mirrors.cnnic.cn/apache/ ...
- Storm环境搭建(分布式集群)
作为流计算的开篇,笔者首先给出storm的安装和部署,storm的第二篇,笔者将详细的介绍storm的工作原理.下边直接上干货,跟笔者的步伐一块儿安装storm. 原文链接:Storm环境搭建(分布式 ...
- 在 Linux 多节点安装配置 Apache Zookeeper 分布式集群
规划: 三台物理服务器就形成了(法定人数).对于高可用性集群,您可以使用高于3的任何奇数.例如,如果设置5台服务器,则集群可以处理两个故障节点等. 物理服务器需要开启的端口 2888 , 3888 和 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- 虚拟机搭建Zookeeper服务器集群完整笔记
虚拟机搭建Zookeeper服务器集群完整笔记 本笔记主要记录自己搭建Zookeeper服务器的全过程,默认已经安装部署好Centos7. 一.虚拟机下Centos无法联网解决方案 1.首先调整虚拟机 ...
- 搭建zookeeper+kafka集群
搭建zookeeper+kafka集群 一.环境及准备 集群环境: 软件版本: 部署前操作: 关闭防火墙,关闭selinux(生产环境按需关闭或打开) 同步服务器时间,选择公网ntpd服务器或 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
随机推荐
- Delaunay triangulation
1,先花个圆: detail模式执行. #define XY 0x00 #define XZ 0x01 #define YZ 0x02 #define pi 3.1415926 #define clo ...
- HTTP协议04-返回状态码
状态码职责是在客户端向服务器端发送请求时候,描述返回的请求结果.借助状态码,用户可以知道服务器是否正常处理了请求,还是出错了. 状态码的类别 类别 原因短语 1XX Informational(信 ...
- Flask组件
组件踩坑记录 : 先注册组件在使用配置(...) flask-script Flask Script扩展提供向Flask插入外部脚本的功能,包括运行一个开发用的服务器,一个定制的Python shel ...
- QTableWidget
1.QTableWidget继承自QTableView. QSqlTableModel能与QTableView绑定,但不能于QTableWidget绑定. QTableWidget是QTableVi ...
- web@css盒模型详解
Margin(外边距) - 清除边框外的区域,外边距是透明的./*上 右 下 左*/ 上 左右 下 /*上下 左右*/ 四方 /Border(边框) - 围绕在内边距和内容外的边框. 可以用 ...
- ansible笔记(10):初识ansible playbook
ansible笔记():初识ansible playbook 假设,我们想要在test70主机上安装nginx并启动,我们可以在ansible主机中执行如下3条命令 ansible test70 -m ...
- android SDK与ADT版本更新问题
android SDK与ADT版本更新问题 问题:This Android SDK requires Android Developer Toolkit version 14.0.0 or above ...
- Cropper.js使用笔记
官网:https://fengyuanchen.github.io/cropperjs/ github:https://github.com/fengyuanchen/cropperjs 由于文档不好 ...
- boolalpha的作用
#include <iostream>using namespace std;int main(){ bool b=true; cout << &q ...
- STM32L476应用开发之六:电池SOC检测
便携式设备由于使用需求而配备了锂电池,但使用过程中需要掌握电源的状态才能保证设备正常运行.而且在电池充放电的过程中,监控电池的充放电状态也是保证设备安全的需要. 1.硬件设计 电池SOC检测是一个难题 ...