Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)
一、准备
1.1创建hadoop用户
$ sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
$ sudo passwd hadoop #为hadoop用户设置密码,之后需要连续输入两次密码
$ sudo adduser hadoop sudo #为hadoop用户增加管理员权限
$ su - hadoop #切换当前用户为用户hadoop
$ sudo apt-get update #更新hadoop用户的apt,方便后面的安装
1.2安装SSH,设置SSH无密码登陆
$ sudo apt-get install openssh-server #安装SSH server
$ ssh localhost #登陆SSH,第一次登陆输入yes
$ exit #退出登录的ssh localhost
$ cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
$ ssh-keygen -t rsa
输入完 $ ssh-keygen -t rsa 语句以后,需要连续敲击三次回车,如下图:

其中,第一次回车是让KEY存于默认位置,以方便后续的命令输入。第二次和第三次是确定passphrase,相关性不大。两次回车输入完毕以后,如果出现类似于下图所示的输出,即成功:
之后再输入:
$ cat ./id_rsa.pub >> ./authorized_keys #加入授权
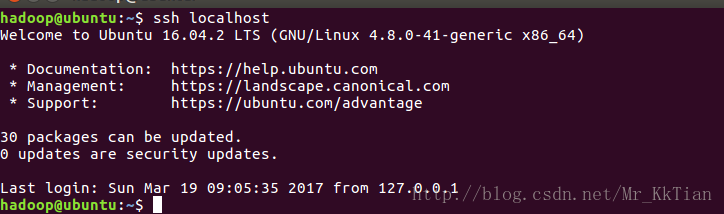
$ ssh localhost #此时已不需密码即可登录localhost,并可见下图。如果失败则可以搜索SSH免密码登录来寻求答案
二、安装jdk1.7
首先在oracle官网下载jdk1.7 http://www.oracle.com/technetwork/java/javase/downloads/index.html 接下来进行安装与环境变量配置,根据个人电脑系统选择对应版本,我选的是jdk-7u80-linux-x64.tar.gz
$ mkdir /usr/lib/jvm #创建jvm文件夹
$ sudo tar zxvf jdk-7u80-linux-x64.tar.gz -C /usr/lib #/ 解压到/usr/lib/jvm目录下
$ cd /usr/lib/jvm #进入该目录
$ mv jdk1.7.0_80 java #重命名为java
$ vi ~/.bashrc #给JDK配置环境变量
注:其中如果权限不够,无法在相关目录下创建jvm文件夹,那么可以使用 $ sudo -i 语句进入root账户来创建文件夹。
另外推荐使用vim来编辑环境变量,即最后一句使用指令
$ vim ~/.bashrc
如果没有vim,可以使用:
$sudo apt-get install vim
来进行下载。
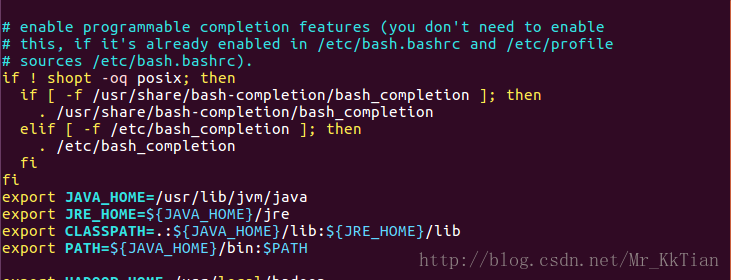
在.bashrc文件添加如下指令:
export JAVA_HOME=/usr/lib/jvm/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
在文件修改完毕以后,输入代码:
$ source ~/.bashrc #使新配置的环境变量生效
$ java -version #检测是否安装成功,查看java版本
如果出现如下图所示的内容,即为安装成功

注:如果各位不想一个一个的敲击,可以复制黏贴,但因为vim不支持系统粘贴板,所以需要先下载相关插件vim-gnome
sudo apt-get install vim-gnome
然后复制相关代码,光标移到指定位置,使用指令 "+p,即可复制,注意 " 也是需要敲击的内容,即一共有 " 、+、p 三个操作符需要敲入
三、安装hadoop-2.6.0
先下载hadoop-2.6.0.tar.gz,链接如下:
http://mirrors.hust.edu.cn/apache/hadoop/common/
下面进行安装:
$ sudo tar -zxvf hadoop-2.6.0.tar.gz -C /usr/local #解压到/usr/local目录下
$ cd /usr/local
$ sudo mv hadoop-2.6.0 hadoop #重命名为hadoop
$ sudo chown -R hadoop ./hadoop #修改文件权限
给hadoop配置环境变量,将下面代码添加到.bashrc文件:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

同样,执行source ~./bashrc使设置生效,并查看hadoop是否安装成功

四、伪分布式配置
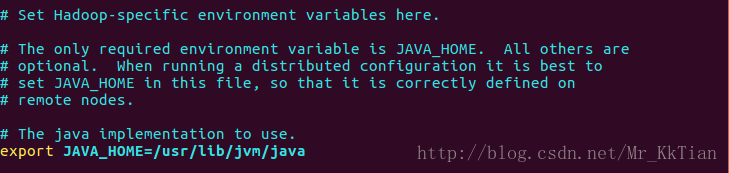
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。首先将jdk1.7的路径添(export JAVA_HOME=/usr/lib/jvm/java )加到hadoop-env.sh文件
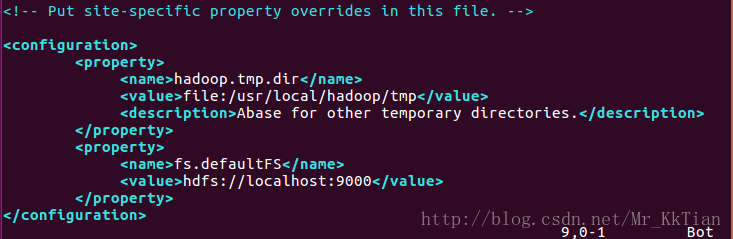
接下来修改core-site.xml文件:

<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
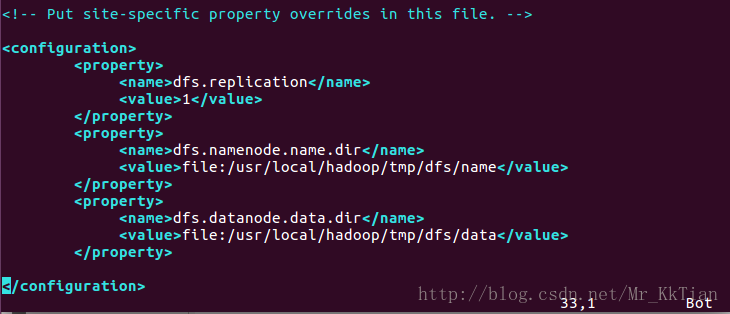
接下来修改配置文件 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(可参考官方教程),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化
$ ./bin/hdfs namenode -format
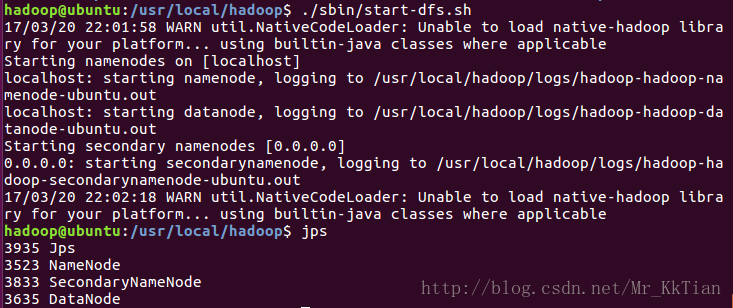
启动namenode和datanode进程,并查看启动结果
$ ./sbin/start-dfs.sh
$ jps
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”
此时也有可能出现要求输入localhost密码的情况 ,如果此时明明输入的是正确的密码却仍无法登入,其原因是由于如果不输入用户名的时候默认的是root用户,但是安全期间ssh服务默认没有开root用户的ssh权限
输入代码:
$vim /etc/ssh/sshd_config
检查PermitRootLogin 后面是否为yes,如果不是,则将该行代码 中PermitRootLogin 后面的内容删除,改为yes,保存。之后输入下列代码重启SSH服务:
$ /etc/init.d/sshd restart
即可正常登入(免密码登录参考第一章)
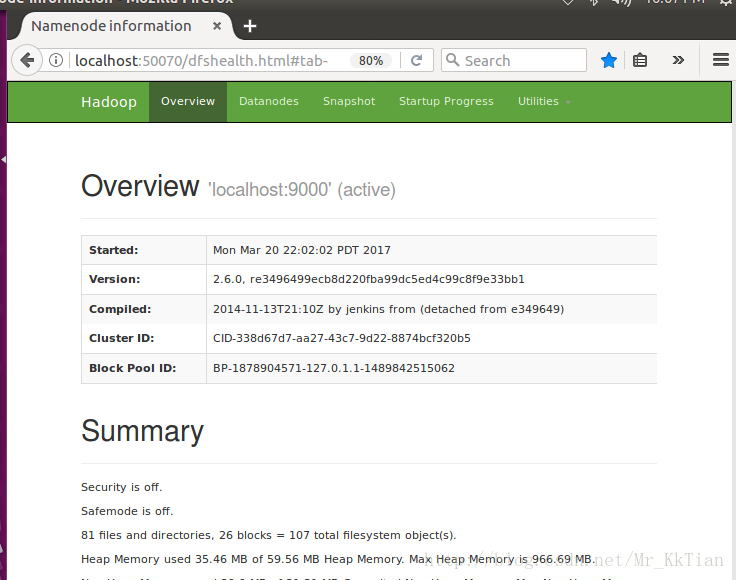
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
至此,hadoop的安装就已经完成啦!enjoy it!
from https://www.cnblogs.com/87hbteo/p/7606012.html
Ubuntu16.04 下 hadoop的安装与配置(伪分布式环境)的更多相关文章
- ubuntu16.04下sublime text3安装和配置
ubuntu16.04下sublime text3安装和配置 2018年04月20日 10:31:08 zhengqijun_ 阅读数:1482 1.安装方法 1)使用ppa安装 sudo add-a ...
- Ubuntu16.04下Kylin的安装与配置
一.系统环境 kylin的安装配置并不像官方文档中描述的那样简单,复杂的原因在于hadoop,hive,hbase,kylin的版本一定要兼容,不然就会出现各种奇怪的错误.以下各软件版本可以成功运行k ...
- Ubuntu16.04下HBase的安装与配置
一.环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : mysql : hive : hbase: -hadoop2 安装HBase前,系统 ...
- Ubuntu16.04下Hive的安装与配置
一.系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 2.6.4mysql : 5.7.21 hive : 2.1.0 在配置hive ...
- ubuntu16.04下vim的安装与配置
一.安装vim 使用命令 $ sudo apt-get install vim 来安装vim,安装后的vim需要进行一些配置,不然使用起来会有些不方便,比如不会自动缩进. 二.配置vim 使用命令 ...
- Ubuntu16.04下,erlang安装和rabbitmq安装步骤
文章来源: Ubuntu16.04下,erlang安装和rabbitmq安装步骤 准备工作,先下载erlang和rabbitmq的安装包,注意他们的版本,版本不对可能会导致rabbitmq无法启动,这 ...
- Ubuntu 14.04 下 android studio 安装 和 配置【转】
本文转载自:http://blog.csdn.net/xueshanfeihu0/article/details/52979717 Ubuntu 14.04 下 android studio 安装 和 ...
- Ubuntu16.04下Hadoop的本地安装与配置
一.系统环境 os : Ubuntu 16.04 LTS 64bit jdk : 1.8.0_161 hadoop : 2.6.4 部署时使用的用户名为hadoop,下文中需要使用用户名的地方请更改为 ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
随机推荐
- python学习笔记(一)、列表和元祖
该一系列python学习笔记都是根据<Python基础教程(第3版)>内容所记录整理的 1.通用的序列操作 有几种操作适用于所有序列,包括索引.切片.相加.相乘和成员资格检查.另外,Pyt ...
- 开源前端脚本错误监控及跟踪解决项目-BadJS 试用
BadJS 是 一个web 前端脚本错误监控及跟踪项目.此项目为鹅厂 imweb(qq群:179045421) 团队的开源项目.此项目支持单机,集群,docker.存储支持mongodb等. 官网文档 ...
- NPM测试模块之rewire教程
摘要:有了rewire模块,再也不用担心测试私有函数了. 在玩转Node.js单元测试,我介绍了3个用于编写测试代码的NPM模块:Mocha, Should以及SuperTest.为了怂恿大家写单元测 ...
- Spring之AOP的注解配置
配置过程可以简单的分为3步: 1,业务类配置 在业务类前加入,将业务类交由Spring管理 @Component("s") 这个表示,这个业务类的Bean名字为 s . 2,将切点 ...
- MySQL5.7: datetime
-- 当前日期时间 select now(); select now(3);-- 保留3位毫秒数 SELECT NOW(6); -- 保留6位毫秒数 -- 当前日期和时间 至秒 select curr ...
- doc命令大全(详细版)
doc命令大全(详细版) 1 echo 和 @回显命令@ #关闭单行回显echo off #从下一行开始关闭回显@echo ...
- leetcode-67.二进制求和
leetcode-67.二进制求和 Points 数组 数学 题意 给定两个二进制字符串,返回他们的和(用二进制表示). 输入为非空字符串且只包含数字 1 和 0. 示例 1: 输入: a = &qu ...
- mssql sqlserver 使用sql脚本检测数据表中一列数据是否连续的方法分享
原文地址:http://www.maomao365.com/?p=7335 摘要: 数据表中,有一列是自动流水号,由于各种操作异常原因(或者插入失败),此列数据会变的不连续,下文将讲述使用sql ...
- Java常用日期操作
对java中常用的日期操作进行整理. 1.日期格式化 /* * 日期格式化类(必须掌握) * API: * G Era 标志符 Text AD y 年 Year 1996; 96 M 年中的月份 Mo ...
- web前端(15)—— JavaScript的数据类型,语法规范2
Object对象 说这个对象之前,如果您对编程语言开发稍微有点了解的话,应该知道面向对象是什么意思,而js也有面向对象一说,就因为如此,js才会这么强大. 什么是面向对象 其实所有支持面向对象的编程语 ...