kafka与zookeeper
kafka简介
kafka (官网地址:http://kafka.apache.org)是一款分布式消息发布和订阅的系统,具有高性能和高吞吐率。
下载地址:http://kafka.apache.org/downloads
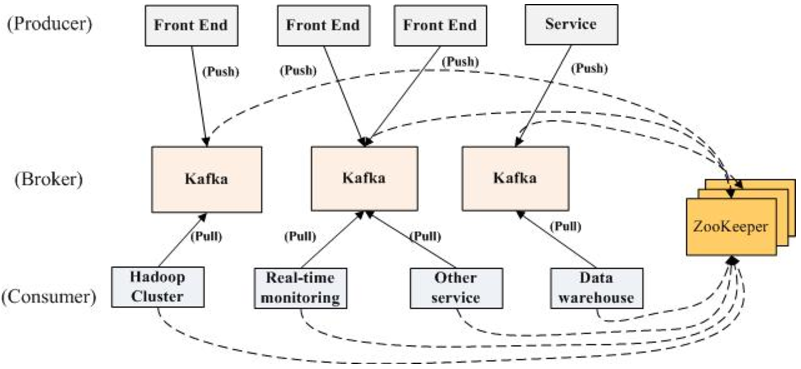
- 消息的发布(publish)称作producer,消息的订阅(subscribe)称作consumer,中间的存储阵列称作broker。
- 多个broker协同合作,producer、consumer和broker三者之间通过zookeeper来协调请求和转发。
- producer产生和推送(push)数据到broker,consumer从broker拉取(pull)数据并进行处理。
- broker端不维护数据的消费状态,提升了性能。
- 直接使用磁盘进行存储,线性读写,速度快:避免了数据在JVM内存和系统内存之间的复制,减少耗性能的创建对象和垃圾回收。
- Kafka使用scala编写,可以运行在JVM上。
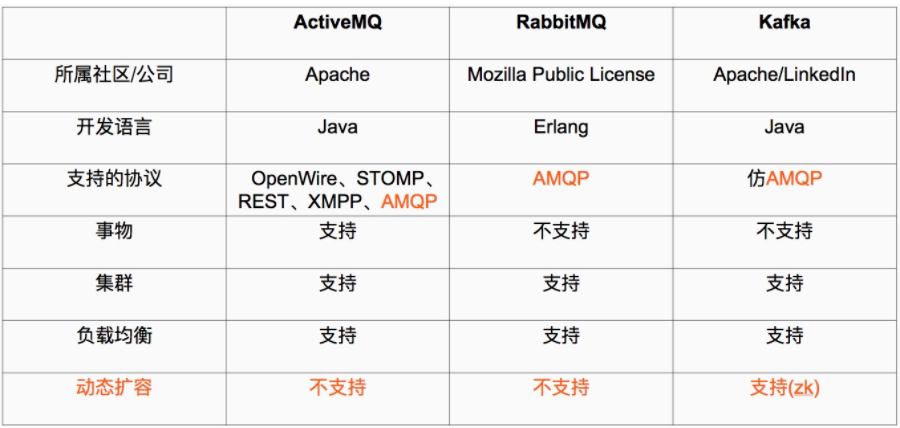
Kafka和其他主流分布式消息系统的对比
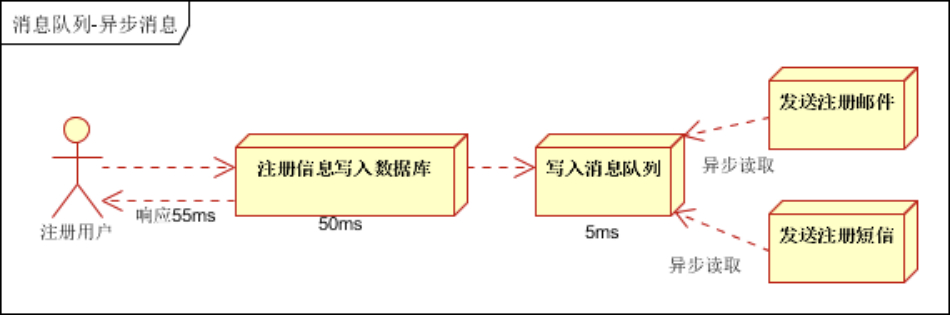
- 异步处理, 把非关键流程异步化,提高系统的响应时间和健壮性
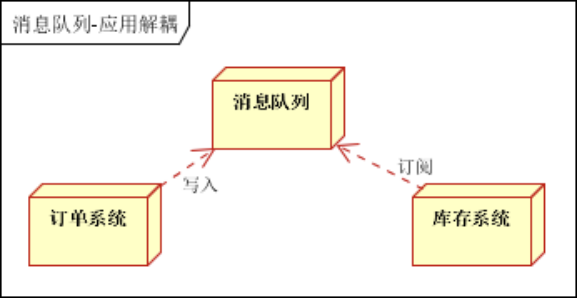
- 应用解耦,通过消息队列
- 流量削峰
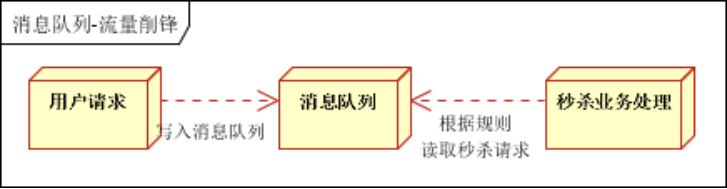
zookeeper简介
ZooKeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供了一项基本服务:分布式锁服务。由于ZooKeeper的开源特性,后来我们的开发者在分布式锁的基础上,摸索了出了其他的使用方法:配置维护、组服务、分布式消息队列、分布式通知/协调等。
官网:https://zookeeper.apache.org/
下载地址:http://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
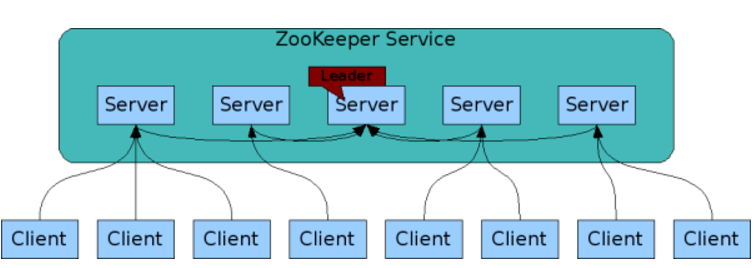
zookeeper应用场景:
- 服务注册&服务发现

配置中心

- 分布式锁
Zookeeper是强一致的
多个客户端同时在Zookeeper上创建相同znode,只有一个创建成功
其它博文:http://www.cnblogs.com/sunddenly/p/4033574.html
kafka和zookeeper的单机部署
1、配置环境变量
export ZOOKEEPER_HOME=/root/zookeeper-3.4.11
export JAVA_HOME=/usr/local/java/jre1.8.0_161
export PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$ZOOKEEPER_HOME/lib:$CLASSPATH
2、解压zookeeper
tar -xvf zookeeper-3.4.11.tar.gz
3、配置zookeeper
cp /root/zookeeper-3.4.11/conf/zoo_sample.cfg /root/zookeeper-3.4.11/conf/zoo.cfg
vim zoo.cfg
dataDir=/root/zookeeper-3.4.11/zkdata
dataLogDir=/root/zookeeper-3.4.11/zkdatalog
4、启动zookeeper
sh /root/zookeeper-3.4.11/bin/zkServer.sh start
5、解压kafka
tar -xvf kafka_2.11-1.0.0.tgz
6、修改配置kafka
log.dirs=/root/kafka_2.11-1.0.0/logs
7、启动kafka
./kafka-server-start.sh ../config/server.properties &
Zookeeper集群搭建
1、部署环境
操作系统:centos6.8
3台服务器:10.10.83.162、10.10.83.163、10.10.83.229
zookeeper版本:3.4.9
部署要求:Zookeeper集群的工作是超过半数才能对外提供服务,Linux服务器一台、三台、五台、(2*n+1)
2、java安装
yum list java*
yum -y install java-1.8.0-openjdk*
3、Zookeeper下载解压
tar -zxvf zookeeper-3.4.9.tar.gz
4、修改配置文件
1)进入conf目录
cp zoo_sample.cfg zoo.cfg
配置内容
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/software/zookeeper-3.4.9/zkdata
dataLogDir=/home/software/zookeeper-3.4.9/zkdata
# the port at which the clients will connect
clientPort=12181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=10.10.83.162:12888:13888
server.2=10.10.83.163:12888:13888
server.3=10.10.83.229:12888:13888
配置项说明:
- tickTime:心跳时间,为了确保连接存在的,以毫秒为单位,最小超时时间为两个心跳时间
- initLimit:多少个心跳时间内,允许其他server连接并初始化数据,如果ZooKeeper管理的数据较大,则应相应增大这个值
- clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
- dataDir:内存数据库快照存放地址,如果没有指定事务日志存放地址(dataLogDir),默认也是存放在这个路径下,建议两个地址分开存放到不同的设备上
- dataLogDir:用于单独设置transaction log的目录,transaction log分离可以避免和普通log还有快照的竞争
- syncLimit:这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是5*2000=10秒
- 从3.4.0开始,zookeeper提供了自动清理snapshot和事务日志的功能,通过配置 autopurge.snapRetainCount 和 autopurge.purgeInterval 这两个参数能够实现定时清理了。这两个参数都是在zoo.cfg中配置的:
- autopurge.purgeInterval 这个参数指定了清理频率,单位是小时,需要填写一个1或更大的整数,默认是0,表示不开启自己清理功能。
- autopurge.snapRetainCount 这个参数和上面的参数搭配使用,这个参数指定了需要保留的文件数目。默认是保留3个
- server.A=B:C:D(A是一个数字,表示这个是第几号服务器,B是这个服务器的ip地址,C第一个端口用来集群成员的信息交换,表示的是这个服务器与集群中的Leader服务器交换信息的端口,D是在leader挂掉时专门用来进行选举leader所用)
- maxClientCnxns:一个客户端能够连接到同一个服务器上的最大连接数,根据IP来区分。如果设置为0,表示没有任何限制。设置该值一方面是为了防止DoS攻击
2)创建myid文件
在每台服务器创建自己的myid文件
# server1 10.10.83.162
echo "1" > /home/software/zookeeper-3.4.9/zkdata/myid
# server2 10.10.83.163
echo "2" > /home/software/zookeeper-3.4.9/zkdata/myid
# server3 10.10.83.229
echo "3" > /home/software/zookeeper-3.4.9/zkdata/myid
myid文件和server.myid 在快照目录下存放的标识本台服务器的文件,他是整个zk集群用来发现彼此的一个重要标识。
3)日志输出配置
- 修改./bin/zkEnv.sh 文件
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="/home/software/zookeeper-3.4.9/logs"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
- 修改./conf/log4j.properties文件
zookeeper.root.logger=INFO, ROLLINGFILE log4j.appender.CONSOLE=org.apache.log4j.DailyRollingFileAppender log4j.appender.ROLLINGFILE.MaxFileSize=100MB
5、启动服务并查看
- 启动服务
#启动服务(3台都需要操作)
./bin/zkServer.sh start
- 检查服务状态
./bin/zkServer.sh status

zk集群一般只有一个leader,多个follower,主一般是相应客户端的读写请求,而从主同步数据,当主挂掉之后就会从follower里投票选举一个leader出来。
Kafka集群搭建
http://mirror.bit.edu.cn/apache/kafka
1、部署环境
centos 6.8
3台服务器:10.10.83.162、10.10.83.163、10.10.83.229(linux一台或多台,大于等于2)
kafka版本:2.11-0.11.0.1
已经搭建好的zookeeper集群
2、安装
官方文档:http://kafka.apache.org/quickstart
tar -xzf kafka_2.11-0.11.0.1.tgz
cd kafka_2.11-0.11.0.1
3、配置
进入到config目录,修改server.properties文件
broker.id=1 # 集群中每台主机唯一标识
listeners=PLAINTEXT://10.10.83.162:9092
advertised.host.name=10.10.83.162
log.dirs=/home/software/kafka_2.11-0.11.0.1/kafkalogs
zookeeper.connect=10.10.83.162:12181,10.10.83.163:12181,10.10.83.229:12181
配置项说明:
- broker.id: 当前机器在集群中的唯一标识,和zookeeper的myid性质一样
- listeners:绑定服务监听的地址和端口
- advertised.listeners:broker对producers和consumers服务的地址和端口,如果没有配置,使用listeners的配置
- num.network.threads:处理网络请求的线程数量,也就是接收消息的线程数,接收线程会将接收到的消息放到内存中,然后再从内存中写入磁盘
- num.io.threads:用来处理磁盘IO的线程数量,消息从内存中写入磁盘是时候使用的线程数量
- socket.send.buffer.bytes:发送套接字的缓冲区大小
- socket.receive.buffer.bytes:接受套接字的缓冲区大小
- socket.request.max.bytes:请求套接字的缓冲区大小
- log.dirs:存放日志和消息的目录,可以是用逗号分开的目录
- num.partitions:每个topic默认partitions的数量,数量较大表示消费者可以有更大的并行度
- num.recovery.threads.per.data.dir:用来设置恢复和清理data下数据的线程数量
- log.retention.hours:日志的过期时间,超过后被删除,单位小时
- log.segment.bytes:一个日志文件最大大小,超过会新建一个文件
- log.retention.check.interval.ms:根据过期策略检查过期文件的时间间隔,单位毫秒
- log.flush.interval.messages:每当producer写入消息的条数达到阈值,刷数据到磁盘
- log.flush.interval.ms:每间隔阈值时间,刷数据到磁盘,单位毫秒
- zookeeper.connect:broker需要使用zookeeper保存meta数据
- zookeeper.connection.timeout.ms:zookeeper链接超时时间
- delete.topic.enable:删除topic
- advertised.host.name:外网访问配置
4、启动Kafka集群
1)启动服务
cd ./bin
./kafka-server-start.sh -daemon ../config/server.properties
2)检查服务是否启动
jps -lm
5、测试
1)创建Topic,名称是nginx_log
./kafka-topics.sh --create --zookeeper 10.10.83.162:12181 --replication-factor 1 --partitions 1 --topic nginx_log
- --replication-factor 2 #复制两份
- --partitions 1 #创建1个分区
- --topic #主题为nginx_log
2)创建生产者
./kafka-console-producer.sh --broker-list 10.10.83.162:9092 --topic nginx_log
3)创建消费者
./kafka-console-consumer.sh --bootstrap-server 10.10.83.162:9092 --topic nginx_log --from-beginning
测试(在发布者那里发布消息看看订阅者那里是否能正常收到~)
4)查看topic
./kafka-topics.sh --list --zookeeper 10.10.83.162:12181
5)查看topic状态
./kafka-topics.sh --describe --zookeeper 10.10.83.162:12181 --topic nginx_log

6)删除topic
./kafka-topics.sh --zookeeper 10.10.83.162:12181 --delete --topic nginx_log
备注:设置server.properties文件中delete.topic.enable=true
6、日志说明
默认kafka的日志是保存在./logs目录下的
- server.log #kafka的运行日志
- state-change.log #kafka他是用zookeeper来保存状态,所以他可能会进行切换,切换的日志就保存在这里
- controller.log #kafka选择一个节点作为“controller”,当发现有节点down掉的时候它负责在分区的所有节点中选择新的leader,这使得Kafka可以批量的高效的管理所有分区节点的主从关系。如果controller down掉了,活着的节点中的一个会备切换为新的controller
kafka与zookeeper的更多相关文章
- kafka及zookeeper安装
kafka_2.9.2-0.8.1.tgzzookeeper-3.4.8.tar.gz 安装 zookeeper1 export PATH=$PATH:/usr/local/zookeeper/bin ...
- java企业架构 spring mvc +mybatis + KafKa+Flume+Zookeeper
声明:该框架面向企业,是大型互联网分布式企业架构,后期会介绍linux上部署高可用集群项目. 项目基础功能截图(自提供了最小部分) 平台简介 Jeesz是一个分布式的框架,提供 ...
- kafka之zookeeper 节点
1.zookeeper 节点 kafka 在 zookeeper 中的存储结构如下图所示:
- 脚本检测Kafka和Zookeeper
Java测试环境中Kafka最近总是自动停止,所有写了一个简单的脚本来监听Kafka和Zookeeper,其中Kafka监听端口为9092,Zookeeper监听端口为2181,脚本如下: #!/bi ...
- kubernetes(k8s) helm安装kafka、zookeeper
通过helm在k8s上部署kafka.zookeeper 通过helm方法安装 k8s上安装kafka,可以使用helm,将kafka作为一个应用安装.当然这首先要你的k8s支持使用helm安装.he ...
- centOS7安装kafka和zookeeper
wget http://mirrors.hust.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz tar zxvf kafka_2.-.tgz cd ka ...
- kafka在zookeeper上的节点信息和查看方式
kafka在Zookeeper上的节点如下图: 该图片盗自大牛的博客http://blog.csdn.net/lizhitao/article/details/23744675 服务端开启的情况下,进 ...
- zookeeper集群环境搭建(使用kafka的zookeeper搭建zk集群)
---恢复内容开始--- 使用kafka的zookeeper来搞集群的话和单纯用zk的其实差不了多少. 0.说在前头,搭建kafka集群之前请把每个服务器的jdk搞起来. 1.安装kafka wget ...
- Kafka学习之路 (五)Kafka在zookeeper中的存储
一.Kafka在zookeeper中存储结构图 二.分析 2.1 topic注册信息 /brokers/topics/[topic] : 存储某个topic的partitions所有分配信息 [zk: ...
随机推荐
- python命令里运行正确但是pycharm里面运行就是报错的问题
这两天在学习爬虫,第一步就是 import scrapy class StackOverflowSpider(scrapy.Spider): 结果一直报错,说是scrapy没有spider这个方法,各 ...
- 后台CRUD管理jqGrid 插件下载、使用、demo演示
jqGrid:demo?version=5.2.1download src: http://www.trirand.com/blog/ github:https://github.com/tonyto ...
- 三天STL与pbds(平板电视)
19.02.11 ~ 19.02.13 hjmmm要专攻STL辣 先列一下大纲? 第一天:各种基础容器 第二天:实现平衡树和平板电视pbds 第三天:非变异算法和变异算法 那么我们就开始吧! Day1 ...
- 用keras实现基本的文本分类任务
数据集介绍 包含来自互联网电影数据库的50000条影评文本,对半拆分为训练集和测试集.训练集和测试集之间达成了平衡,意味着它们包含相同数量的正面和负面影评,每个样本都是一个整数数组,表示影评中的字词. ...
- Mysql数据库操作笔记
如果数据库表字段存在,则删除该表 drop table if exists `table_name` 创建数据库表语句 create table `table_name`( `id` ) not n ...
- 利用纯粹的CSS3替代小图标---向右箭头
1.向右的箭头> . 看到很多网站里面向右的箭头都是图片代替的,但是为了网站的性能,我们一般的原则是能够避免使用图片的尽量不用图片 比如看下携程个人中心首页面,向右的箭头 其实现思路是这样 ...
- 【原创】hdu 1166 敌兵布阵(线段树→单点更新,区间查询)
学习线段树的第三天...真的是没学点啥好的,又是一道水题,纯模板,我个人觉得我的线段树模板还是不错的(毕竟我第一天相当于啥都没学...找了一整天模板,对比了好几个,终于找到了自己喜欢的类型),中文题目 ...
- Spring Data JPA Batch Insertion
转自:https://www.jeejava.com/spring-data-jpa-batch-insertion/ Spring Data JPA Batch Insertion will sho ...
- String:字符串常量池
String:字符串常量池 作为最基础的引用数据类型,Java 设计者为 String 提供了字符串常量池以提高其性能,那么字符串常量池的具体原理是什么,我们带着以下三个问题,去理解字符串常量池: 字 ...
- Spring Boot 1.X和2.X优雅重启实战
纯洁的微笑 今天 项目在重新发布的过程中,如果有的请求时间比较长,还没执行完成,此时重启的话就会导致请求中断,影响业务功能,优雅重启可以保证在停止的时候,不接收外部的新的请求,等待未完成的请求执行完成 ...