scrapy中css选择器初识
由于最近做图片爬取项目,涉及到网页中图片信息的选择,所以边做边学了点皮毛,有自己的心得
百度图库是ajax加载的,所以解析json数据即可
hjsons = json.loads(response.body)
img_datas = hjsons['data']
if hjsons:
for data in img_datas:
try:
item = Bd_Item()
#print(data['fromPageTitleEnc'])
#print(data['thumbURL'])
item['img_url'] = data['thumbURL']
item['img_title'] = data['fromPageTitleEnc']
item['width'] = data['width']
item['height'] = data['height']
yield item
except:
pass
千图网抠图是分页加载
http://588ku.com/sucai/0-default-0-0-yueliang-0-1/
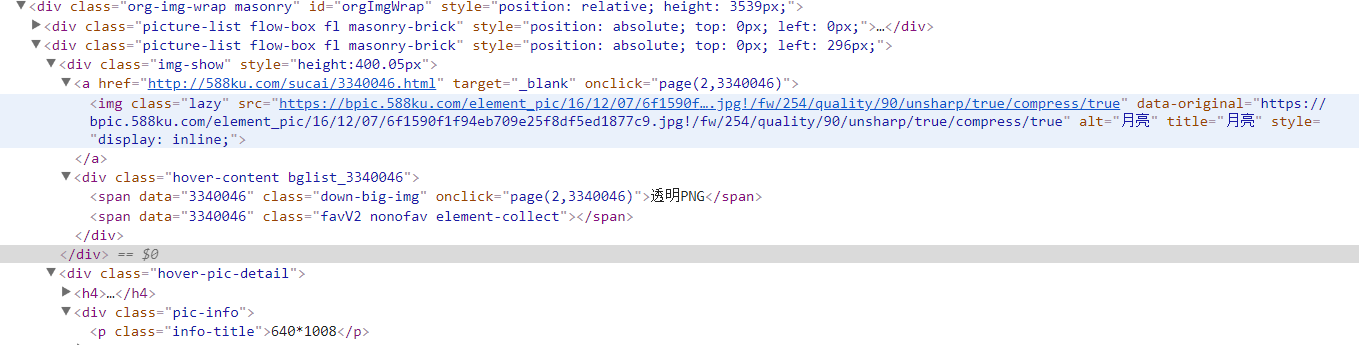
qt_imgs = response.css('.org-img-wrap .picture-list')
for qt_img in qt_imgs:
try:
item = Qt_Item()
img_url = qt_img.css('.img-show .lazy::attr(data-original)').extract_first()
title = qt_img.css('.img-show .lazy::attr(title)').extract_first()
size = qt_img.css('.hover-pic-detail .pic-info .info-title::text').extract_first()
#width = re.findall(r'(.*?)\*',size).extract_first()
#height = re.findall(r'\*(.*?)', size).extract_first()
#print(width)
#print(height)
#time.sleep(10)
item['qtimg_url'] = img_url
item['qtimg_title'] = title
item['size'] = size
#item['width'] = width
#item['height'] = height
yield item
except:
pass
觅元素和千图网差不多,但是选取图片链接有技巧,千图网图片可以看到有两个图片链接,其中data-original这个链接不同处理即可,但是如果选src会发现,选取出来的链接都是一样的,而且当你打开链接时发现黑色一片,我感觉这是种保护吧,但只有这一种链接该怎么办呢,于是我用正则去选择,结果发现,抓取结果中有两条链接,而第一条是无用的,第二条才是有用的,它的名字是data-src,这就好办了,只需要把src改成data-src即可成功选取。

mys_imgs = response.css('.content-wrap .w1200 .f-content .i-flow-item')
for mys_img in mys_imgs:
try:
item = Mys_Item()
img_url = mys_img.css('.img-out-wrap .img-wrap img::attr(data-src)').extract_first()
title = mys_img.css('.img-out-wrap .img-wrap img::attr(alt)').extract_first()
size = mys_img.css('.i-title-wrap a::text').extract_first()
size_detail = re.findall(r'\((.*?)\)',size)
#text = mys_img.css('.img-wrap .lazy').extract_first()
# time.sleep(10)
#img_url = re.findall(r'src="(.*?)!/fw/260/quality/90/unsharp/true/compress/true"', text)
#width = re.findall(r'(.*?)x', size_detail).extract_first()
#height = re.findall(r'x(.*?)', size_detail).extract_first()
item['mysimg_url'] = img_url
item['mysimg_title'] = title
item['size'] = size_detail
#item['width'] = width
#item['height'] = height
yield item
except:
pass
这东西有点意思,需要琢磨,以后用到再慢慢学吧
scrapy中css选择器初识的更多相关文章
- 使用scrapy中xpath选择器的一个坑点
情景如下: 一个网页下有一个ul,这个ur下有125个li标签,每个li标签下有我们想要的 url 字段(每个 url 是唯一的)和 price 字段,我们现在要访问每个li下的url并在生成的请求中 ...
- 爬虫学习笔记(2)--创建scrapy项目&&css选择器
一.手动创建scrapy项目---------------- 安装scrapy: pip install -i https://pypi.douban.com/simple/ scrapy 1 ...
- 爬虫(十一):scrapy中的选择器
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- selenium中CSS选择器定位
selenium元素定位,CSS选择器定位效率会高很多. CSS选择器用于选择你想要的元素的样式的模式.表格摘自“菜鸟教程”,具体用法可去查阅 选择器 示例 示例说明 CSS .class .intr ...
- Scrapy的中Css 选择器
//通过 名为 video_part_lists 的Class 中下面的 li 标签 liList = response.css('.video_part_lists li') for li in l ...
- Scrapy基础------css选择器基础
基本语法: * 选择所有节点 #container 选择id为container的节点 .container 选择所有class包含container的节点 li a 选取所有li 下所有a节点 ul ...
- 第 13 章 CSS 选择器[上]
学习要点: 1.选择器总汇 2.基本选择器 3.复合选择器 4.伪元素选择器 主讲教师:李炎恢 本章主要探讨 HTML5 中 CSS 选择器,通过选择器定位到想要设置样式的元素.目前 CSS 选择器的 ...
- 第七十节,css选择器
css选择器 学习要点: 1.选择器总汇 2.基本选择器 3.复合选择器 4.伪元素选择器 本章主要探讨 HTML5中 CSS选择器,通过选择器定位到想要设置样式的元素.目前CSS选择器的版本已经升 ...
- 初始scrapy,简单项目创建和CSS选择器,xpath选择器(1)
一 安装 #Linux: pip3 install scrapy #Windows: a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu ...
随机推荐
- Map接口----Map中嵌套Map
package cn.good.com; import java.util.HashMap; import java.util.Iterator; import java.util.Map; impo ...
- react 入坑笔记(五) - 条件渲染和列表渲染
条件渲染和列表渲染 一.条件渲染 条件渲染较简单,使用 JavaScript 操作符 if 或条件运算符来创建表示当前状态的元素,然后让 React 根据它们来更新 UI. 贴一个小栗子: funct ...
- Windows & RabbitMQ:安装
可以参考:在 Windows 上安装Rabbit MQ 指南 本文RabbitMQ版本为3.6.1 Step 1:安装Erlang Step 2:安装RabbitMQ Step 3:启用Managem ...
- 测试md
一级标题 table class="top_ta" width="100%" border="0" cellspacing="0& ...
- 关于mysql 5.7 版本登录时出现错误 1045的随笔
之前学习的时候用的都是oracle 但是现在在工作中大部分用的都是mysql,所以自己也就装了个mysql,下载.安装教程都是从网上百度的,花了挺长时间才装好,心也是挺累的,教程挺多,就是不知道该用哪 ...
- Ubuntu开发用新机安装流程
1.SSH安装 Ubuntu缺省已安装客户端,此处安装服务端 sudo apt-get install openssh-server 确认sshserver是否启动 netstat -tlp | gr ...
- 欧拉筛,线性筛,洛谷P2158仪仗队
题目 首先我们先把题目分析一下. emmmm,这应该是一个找规律,应该可以打表,然后我们再分析一下图片,发现如果这个点可以被看到,那它的横坐标和纵坐标应该互质,而互质的条件就是它的横坐标和纵坐标的最大 ...
- BZOJ 4196 软件包管理器
树链剖分 建树之后,安装软件就是让跟节点到安装的节点路径所有点权+1,卸载软件就是让一个节点和他的子数-1 要求变化数量的话直接求和相减就行啦(绝对值) 注意一点,一开始的lazyatag应该是-1, ...
- bzoj 1029: [JSOI2007]建筑抢修 (优先队列)
链接:https://www.lydsy.com/JudgeOnline/problem.php?id=1029 思路: 按结束时间排序,优先选结束时间短的,选完后扔到优先队列里(大的优先),如果选到 ...
- npm 常规错误
Unexpected end of JSON input while parsing near 意外结束.JSON解析期间 解决办法: npm cache clean --force 解释:Force ...