Feature Extractor[DenseNet]
0.背景
随着CNN变得越来越深,人们发现会有梯度消失的现象。这个问题主要是单路径的信息和梯度的传播,其中的激活函数都是非线性的,从而特别是乘法就可以使得随着层数越深,假设将传统的神经网络的每一层看成是自动机中的一个状态。那么对于整个神经网络来说,输入到输出就是一个输入态不断的转移到输出态的一个过程。假设其中每一层都是有个变率,即缩放因子。那么:
- 变率大于1,层数越多,越呈现倍数放大趋势,比如爆炸;
- 变率小于1,层数越多,越呈现倍数缩小趋势,比如消失;
而传统以往的卷积神经网络都是单路径的,即从输入到输出只能走一条路,所以人们发现了可以通过扩展信息的传输路径和形式,如:
- inception系列从模块入手,基于每个模块建立多个不同的通道,然后将模块进行连接,不过从模型整体角度上看也是一本道;
- ResNet系列通过快捷连接的方式将不同层的输出直接连接到后面层的输入,算是让信息的传播通道有了分支,不完全直接走非线性的卷积和池化等权重层,让信息的传播路径有了选择。
正是发现可以从网络结构入手,让信息的传输路径不再单一。假如我们认为传统的神经网络的输入到输出是单路径形式,那么通过添加分支路径使得某些层能够比传统模型有更多更短的路径可以选择,这样较好的解决了唯一路径的"瓶颈问题"(信息只有一条路可走),从而通过网络训练,信息能够自适应的走网络的多个路径。不过近期很多的论文,如ResNet和Highway Network等都是通过恒等连接将某层的输出信息传递到后面其他层,且而《Deep networks with stochastic depth》在Resnet网络结构上发现其实很多层的信息是冗余的,通过在训练过程中随机丢弃某些层可以得到更好的信息和梯度流。
DenseNet由此出发,建立了更复杂的多通道模型,如图0.1所示,输入层可以快捷连接到输出层:
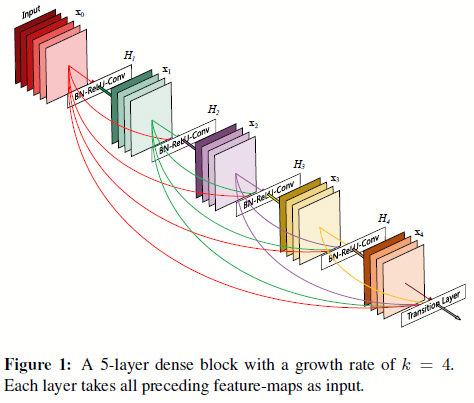
图0.1 Densenet的模块结构
如图0.1,这就是Densenet的模块结构。作者认为好处有:
- 缓和了梯度消失的问题(多路径带来的好处);
- 增强了特征传播(多路径带来的好处);
- 特征能够多次重用,从而减少冗余特征的学习;
- 模型参数量能够很大程度上的减少;
- 模型具有正则效果(在很小的数据集上减少过拟合)
如图0.1所示,Densenet在将特征连入后面的层之前,不对其做任何操作,只是将其以通道的维度进行合并(如第\(l\)层有\(l\)个通道输入,那么结合之前所有的卷积层,这时候的通道数变成了\(l(l+1)/2\)).
值得注意的是,通过实验发现,这样一个相对更密集的网络结构,所需要的参数量反而更少,这归功于densenet不需要去保留那些冗余的feature map。
1. DenseNet
基于上述自动机的角度,传统的前向网络结构可以认为是:当前层从前一层获取状态,然后加以处理,并将新的状态输出到下一层。这其中就会发现有些信息其实是需要保留到当前层的,结果也传递到后面去了,造成了冗余。接着从自动机角度出发,Resnet也可以看成是一个“相似的铺展开的RNN网络结构”(通过恒等连接实现循环),不过不同于RNN的就是resnet的参数量因为每一层都是有各自的参数,所以相比RNN的参数量要大很多。
为了防止参数量过大,且主要是基于特征重用。densenet设计的时候是让每一层的通道数量很小(一层12个通道),且如0.1图所示,后续每一层都能直接获取前面所有层的特征,最后的分类器可以基于所有的feature map进行做决策,这样让特定层的特征能够一直重用,从而减少网络的冗余特征学习。
用数学形式来说明ResNet与Densenet的差别如下:
- ResNet: \(x_l = H_l(x_{l-1})+x_{l-1}\)
- DenseNet: \(x_l = H_l([x_0,x_1,...,x_{l-1}])\)
其中\([x_0,x_1,...,x_{l-1}]\)就是将之前的feature map以通道的维度进行合并,且受到ResNet v2的影响,其中的\(H_l(\dot)\)也是三层网络:BN、ReLU、卷积。
如上面所述,在进行feature map合并的时候,是没法处理feature map的size不同的情况的,可是CNN是必须要有map的size的减小的,也就是池化还是需要的,不然输出层会参数量过多了。所以作者通过图1.1形式来解决这个问题。
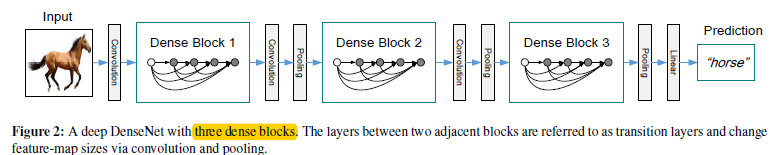
图1.1 将图0.1结构作为densenet的块来构建整个网络
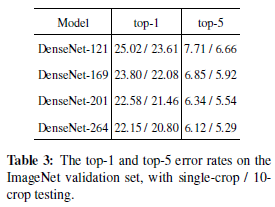
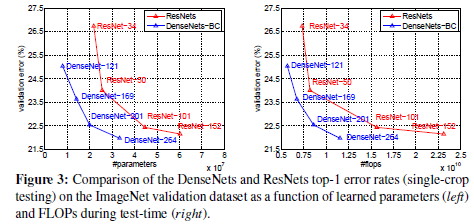
图1.2 基于imagenet上的实验结果
如图1.1。通过将图0.1的结构作为一个构建块,从而在不同的构建块之间建立转换层,从而解决feature map需要变化的问题(其中连接层由:BN层,\(1*1\)卷积层,\(2*2\)池化层构成,其中BN未画出来)(那么,这样是不是说在池化部分,就有瓶颈存在了呢?)
1.1 增长参数k
对于图0.1来说,假定每一层的feature maps的个数为k,则第\(l\)层的输入map个数为\(k_0+k*(l-1)\),即收集之前每层输出的feature maps,然后基于通道维度进行合并,以此作为当前层的输入feature maps。那么k值的大小就能控制网络的复杂度了,作者将该变量称为网络的"growth rate"
1.2 DenseNet-B
对于DenseNet-B来说,就是将之前densenet的构建块中的BN-ReLU-(\(3*3\)卷积)变成BN-ReLU-(\(1*1\)卷积),并且对于其中的(\(1*1\)卷积),输出的feature maps的通道数为4k个
1.3 DenseNet-C
对于Densenet-C来说,就是在转换层下功夫了,如图1.1中的两个Dense block中间的部分,如果上一个Dense block输出了m个feature maps(即将之前所有的feature map都连接到这个转换层),那么设定一个缩放因子\(\theta\),如果\(0<\theta<1\),那么就达到了网络通道上的降维,使得模型更紧凑,实验中该值设为0.5。
2 实现过程
- 1 - 作者在imagenet数据集上用个4个dense block,结构如下图
图2.1 k等于32基础上,不同层数densenet网络的结构

2 - 在其他数据集上是用了三个dense block(每个block中层数相同),转换层是\(1*1\)的卷积加上\(2*2\)的平均池化,在最后一个dense block后面跟上一个全局平均池化,然后是一个softmax。
其中三个dense block中feature map的大小分别是\(32*32\),\(16*16\),\(8*8\),且有三个不同的参数组合:
- 对于简单的densenet来说有(L=40,k=12)、(L=100,k=12)、(L=100,k=24);
- 对于densenet-BC来说有(L=100,k=12)、(L=250,k=24)、(L=190,k=40)

图2.2 其他数据集下的实验对比
Feature Extractor[DenseNet]的更多相关文章
- Feature Extractor[SENet]
0.背景 这个模型是<Deep Learning高质量>群里的牛津大神Weidi Xie在介绍他们的VGG face2时候,看到对应的论文<VGGFace2: A dataset f ...
- Feature Extractor[content]
0. AlexNet 1. VGG VGG网络相对来说,结构简单,通俗易懂,作者通过分析2013年imagenet的比赛的最好模型,并发现感受野还是小的好,然后再加上<network in ne ...
- Feature Extractor[VGG]
0. 背景 Karen Simonyan等人在2014年参加Imagenet挑战赛的时候提出的深度卷积神经网络.作者通过对2013年的ILSVRC中最好的深度神经网络模型(他们最初的对应模型都是ale ...
- Feature Extractor[inception v2 v3]
0 - 背景 在经过了inception v1的基础上,google的人员还是觉得有维度约间的空间,在<Rethinking the Inception Architecture for Com ...
- Feature Extractor[ResNet]
0. 背景 众所周知,深度学习,要的就是深度,VGG主要的工作贡献就是基于小卷积核的基础上,去探寻网络深度对结果的影响.而何恺明大神等人发现,不是随着网络深度增加,效果就好的,他们发现了一个违背直觉的 ...
- 图像金字塔(pyramid)与 SIFT 图像特征提取(feature extractor)
David Lowe(SIFT 的提出者) 0. 图像金字塔变换(matlab) matlab 对图像金字塔变换接口的支持(impyramid),十分简单好用. 其支持在reduce和expand两种 ...
- Feature Extractor[googlenet v1]
1 - V1 google团队在模型上,更多考虑的是实用性,也就是如何能让强大的深度学习模型能够用在嵌入式或者移动设备上.传统的想增强模型的方法无非就是深度和宽度,而如果简单的增加深度和宽度,那么带来 ...
- Feature Extractor[batch normalization]
1 - 背景 摘要:因为随着前面层的参数的改变会导致后面层得到的输入数据的分布也会不断地改变,从而训练dnn变得麻烦.那么通过降低学习率和小心地参数初始化又会减慢训练过程,而且会使得具有饱和非线性模型 ...
- Feature Extractor[Inception v4]
0. 背景 随着何凯明等人提出的ResNet v1,google这边坐不住了,他们基于inception v3的基础上,引入了残差结构,提出了inception-resnet-v1和inception ...
随机推荐
- CentOS 7上VNCServer的安装使用
1.安装 yum install tigervnc tigervnc-server 2.配置 vncserver的配置,创建一个新的配置文件 cp /lib/systemd/system/vncser ...
- yarn安装ant-报错
异常现象: 使用react引用antd的库时报错 yarn add antd Trace: Error: connect ETIMEDOUT 114.55.80.225:80 at Object._e ...
- Android笔试题三
1.java堆得Young区由哪些组成: Java堆由Perm区和Heap区组成,Heap区由Old区和New区(也叫Young区)组成,New区由Eden区.From区和To区(Survivor)组 ...
- 【LeetCode】正则表达式匹配(动态规划)
题目描述 给定一个字符串 (s) 和一个字符模式 (p).实现支持 '.' 和 '*' 的正则表达式匹配. '.' 匹配任意单个字符. '*' 匹配零个或多个前面的元素. 匹配应该覆盖整个字符串 (s ...
- git 入门教程之配置 git
配置 git 安装完成后,还需要最后一步配置就可以愉快使用了,在命令行输入: git config --global user.name "your username" git c ...
- 钉钉扫码登录web网站
钉钉扫码登录网站 前言 由于本公司前后台分离,这里主要讲述后台的实现逻辑与过程,前端相关的一略而过.前端我们采用的是把二维码内嵌到我们的网页中. 流程如下: 1.登录钉钉后台创建一个企业应用 2.根 ...
- (转载)彻底的理解:WebService到底是什么?
最近老是有人跟我提web service接口,怎么,怎么滴,我觉得很扎耳朵,web service是一种将服务器的服务封装起来的技术,表现为对外提供接口,所以,web service不是一种接口 !! ...
- ES搜索引擎集群模式搭建【Kibana可视化】
一.简介 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎(与Solr类似),基于RESTful web接口.Elasticsearch是用Ja ...
- gitolite的部署
gitolite服务部署: 1,在git服务器端安装git并创建git用户. yum install -y git useradd git 2,生成gitolite的管理账户,这个账户也可以在git服 ...
- [20190214]11g Query Result Cache RC Latches.txt
[20190214]11g Query Result Cache RC Latches.txt --//昨天我重复链接http://www.pythian.com/blog/oracle-11g-qu ...