斯坦福大学公开课机器学习:advice for applying machine learning | learning curves (改进学习算法:高偏差和高方差与学习曲线的关系)
绘制学习曲线非常有用,比如你想检查你的学习算法,运行是否正常。或者你希望改进算法的表现或效果。那么学习曲线就是一种很好的工具。学习曲线可以判断某一个学习算法,是偏差、方差问题,或是二者皆有。
为了绘制一条学习曲线,通常先绘制出训练集数据的平均误差平方和(Jtrain),或者交叉验证集数据的平均误差平方和(Jcv)。将其绘制成一个关于参数m的函数。也就是一个关于训练集、样本总数的函数。m一般是一个常数,比如m等于100,表示100组训练样本。但我们要自己取一些m的值,也就是说对m的取值做一点限制,比如说取10、20或者30、40组训练集,然后绘出训练集误差、以及交叉验证集误差。那么我们来看看这条曲线绘制出来是什么样子。假设只有一组训练样本,也即m=1。正如第一幅图中所示(下图,m=1),并且假设使用二次函数来拟合模型,那么由于我只有一个训练样本,拟合的结果很明显会很好,用二次函数来拟合对这一个训练样本拟合其误差一定为0。如果有两组训练样本,二次函数也能很好得拟合。即使是使用正则化,拟合的结果也会很好。而如果不使用正则化的话,那么拟合效果绝对棒极了。如果用三组训练样本的话,看起来依然能很好地用二次函数拟合。也就是说,当m等于1、2、3时,对训练集数据进行预测,得到的训练集误差都将等于0,这里假设不使用正则化。当然如果使用正则化,那么误差就稍大于0。如果训练集样本很大,要人为地限制训练集样本的容量。比如说,将m值设为3,然后仅用这三组样本进行训练,然后对应到这个图中。我只看对这三组训练样本,进行预测得到的训练误差。也是和模型拟合的三组样本,所以即使有100组训练样本,而我们还是想绘制当m等于3时的训练误差,那么我们要关注的仍然是对这三组训练样本进行预测的误差。同样,这三组样本也是我们用来拟合模型的三组样本。所有其他的样本,都在训练过程中选择性忽略了。总结一下,我们现在已经看到,当训练样本容量m很小的时候,训练误差也会很小。因为很显然,如果我们训练集很小,那么很容易就能把训练集拟合到很好,甚至拟合得天衣无缝。现在我们来看,当m等于4的时候,二次函数似乎也能对数据拟合得很好。那我们再看当m等于5的情况,这时候再用二次函数来拟合,好像效果有下降但还是差强人意。而当我的训练集越来越大的时候,要保证使用二次函数的拟合效果依然很好,就显得越来越困难了。
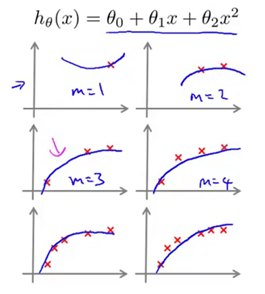
事实上随着训练集容量的增大,平均训练误差是逐渐增大的。因此如果画出这条曲线,你就会发现训练集误差(对假设进行预测的误差平均值)随着m的增大而增大(下图)。再重复一遍对这一问题的理解,当训练样本很少的时候,对每一个训练样本都能很容易地拟合到很好,所以训练误差将会很小。而反过来,当m的值逐渐增大,那么想对每一个训练样本都拟合到很好,就显得愈发的困难了,因此训练集误差就会越来越大。那么交叉验证集误差的情况如何呢。交叉验证集误差是对完全陌生的交叉验证集数据进行预测得到的误差,那么我们知道当训练集样本很小的时候,泛化程度不会很好,意思是不能很好地适应新样本。因此这个假设就不是一个理想的假设。只有使用一个更大的训练集时,我们才有可能得到一个能够更好拟合数据的可能的假设。因此,验证集误差和测试集误差都会随着训练集样本容量m的增加而减小,因为你使用的数据越多,你越能获得更好地泛化表现,或者说对新样本的适应能力更强。因此,数据越多,越能拟合出合适的假设。所以,如果把Jtrain和Jcv绘制出来就应该得到如下的曲线。

现在我们来看看,当处于高偏差或者高方差的情况时,这些学习曲线又会变成什么样子。假如我们的假设处于高偏差问题,为了更清楚地解释这个问题,下面用一个简单的例子来说明,也就是用一条直线,来拟合数据的例子(下图)。很显然一条直线不能很好地拟合数据。

现在我们来想一想,如果我们增大训练集样本容量,会发生什么情况呢。不难发现还是会得到类似的一条直线假设。但一条直线再怎么接近,也不可能对这组数据进行很好的拟合。
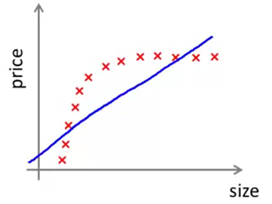
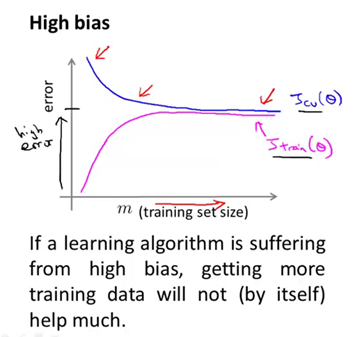
所以,如果你绘出交叉验证集误差,应该是如下图(蓝色曲线)。最左端表示训练集样本容量很小,比如说只有一组样本,那么表现当然很不好,而随着你增大训练集样本数,当达到某一个容量值的时候,你就会找到那条最有可能拟合数据的那条直线,并且此时即便你继续增大训练集的样本容量,即使你不断增大m的值,你基本上还是会得到的一条差不多的直线。因此,交叉验证集误差,或者测试集误差,将会很快变为水平而不再变化。只要训练集样本容量值达到或超过了那个特定的数值,交叉验证集误差和测试集误差就趋于不变,这样你会得到最能拟合数据的那条直线。那么训练误差又如何呢?同样,训练误差一开始也是很小的,而在高偏差的情形中,你会发现训练集误差会逐渐增大。一直趋于接近交叉验证集误差,这是因为你的参数很少。但当m很大的时候,数据太多,此时训练集和交叉验证集的预测效果将会非常接近,这是当你的学习算法处于高偏差情形时,学习曲线的大致走向。最后补充一点,高偏差的情形反映出的问题是,交叉验证集和训练集误差都很大。也就是说,你最终会得到一个值比较大Jcv和Jtrain。这也得出一个很有意思的结论,那就是如果一个学习算法有很大的偏差,那么当我们选用更多的训练样本时,也就是在这幅图中,随着我们增大横坐标,我们发现交叉验证集误差的值,不会表现出明显的下降,实际上是变为水平了。所以如果学习算法正处于高偏差的情形,那么选用更多的训练集数据,对于改善算法表现无益。正如我们右边的这两幅图所体现的,这里我们只有五组训练样本,我们找到这条直线来拟合,然后我们增加了更多的训练样本,但我们仍然得到几乎一样的一条直线。因此如果学习算法处于高偏差时,给再多的训练数据也于事无补。交叉验证集误差或测试集误差也不会降低多少。所以,能够看清算法正处于高偏差的情形是一件很有意义的事情,因为这样可以避免把时间浪费在收集更多的训练集数据上。因为再多的数据也是无意义的。
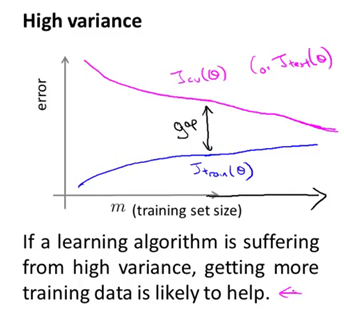
接下来我们再来看看当学习算法正处于高方差的时候,学习曲线应该是什么样子的。首先我们来看训练集误差,如果你的训练集样本容量很小,比如像下图所示情形只有五组训练样本,如果我们用很高阶次的多项式来拟合,比如用了100次的多项式函数。当然不会有人这么用的,这里只是演示。并且假设我们使用一个很小的lambda值,可能不等于0,但足够小的lambda。那么很显然,我们会对这组数据拟合得非常非常好,因此这个假设函数对数据过拟合。所以如果训练集样本容量很小时,训练集误差Jtrain将会很小。
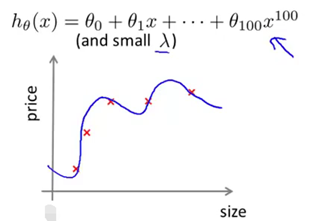
随着训练集样本容量的增加,可能这个假设函数仍然会对数据或多或少有一点过拟合,但很明显此时要对数据很好地拟合,显得更加困难和吃力了(如下图所示)。

所以,随着训练集样本容量的增大,我们会发现Jtrain的值会随之增大。因为当训练样本越多的时候,我们就越难跟训练集数据拟合得很好,但总的来说训练集误差还是很小。交叉验证集误差又如何呢?在高方差的情形中,假设函数对数据过拟合,因此交叉验证集误差将会一直都很大,即便我们选择一个比较合适恰当的训练集样本数,因此交叉验证集误差画出来差不多是图下紫色曲线。所以算法处于高方差情形最明显的一个特点是在训练集误差和交叉验证集误差之间有一段很大的差距。而这个曲线图也反映出如果我们要考虑增大训练集的样本数,也就是在这幅图中向右延伸曲线。我们大致可以看出这两条学习曲线,蓝色和红色的两条曲线正在相互靠近。因此,如果我们将曲线向右延伸出去, 那么似乎训练集误差很可能会逐渐增大. 而交叉验证集误差则会持续下降。当然我们最关心的还是交叉验证集误差或者测试集误差。所以从这幅图中,我们基本可以预测如果继续增大训练样本的数量,将曲线向右延伸,交叉验证集误差将会逐渐下降。所以,在高方差的情形中,使用更多的训练集数据,对改进算法的表现是有效果的。这同样也体现出知道你的算法正处于高方差的情形,也是非常有意义的。因为它能告诉你是否有必要浪费时间来增加更多的训练集数据。
上面画出的学习曲线都是相当理想化的曲线,针对一个实际的学习算法,如果画出学习曲线的话,基本会得到类似的结果。虽然如此,有时候也会看到带有一点噪声或干扰的曲线。但总的来说,像这样画出学习曲线,确实能帮助我们看清学习算法是否处于高偏差、高方差、或二者皆有的情形。所以当我们打算改进一个学习算法的表现时,通常要进行的一项工作,就是画出这些学习曲线。
斯坦福大学公开课机器学习:advice for applying machine learning | learning curves (改进学习算法:高偏差和高方差与学习曲线的关系)的更多相关文章
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- 第19月第8天 斯坦福大学公开课机器学习 (吴恩达 Andrew Ng)
1.斯坦福大学公开课机器学习 (吴恩达 Andrew Ng) http://open.163.com/special/opencourse/machinelearning.html 笔记 http:/ ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning - deciding what to try next(设计机器学习系统时,怎样确定最适合、最正确的方法)
假如我们在开发一个机器学习系统,想试着改进一个机器学习系统的性能,我们应该如何决定接下来应该选择哪条道路? 为了解释这一问题,以预测房价的学习例子.假如我们已经得到学习参数以后,要将我们的假设函数放到 ...
- 斯坦福大学公开课机器学习:machine learning system design | error metrics for skewed classes(偏斜类问题的定义以及针对偏斜类问题的评估度量值:查准率(precision)和召回率(recall))
上篇文章提到了误差分析以及设定误差度量值的重要性.那就是设定某个实数来评估学习算法并衡量它的表现.有了算法的评估和误差度量值,有一件重要的事情要注意,就是使用一个合适的误差度量值,有时会对学习算法造成 ...
- 斯坦福大学公开课机器学习: machine learning system design | prioritizing what to work on : spam classification example(设计复杂机器学习系统的主要问题及构建复杂的机器学习系统的建议)
当我们在进行机器学习时着重要考虑什么问题.以垃圾邮件分类为例子.假如你想建立一个垃圾邮件分类器,看这些垃圾邮件与非垃圾邮件的例子.左边这封邮件想向你推销东西.注意这封垃圾邮件有意的拼错一些单词,就像M ...
- 斯坦福大学公开课机器学习:Neural Networks,representation: non-linear hypotheses(为什么需要做非线性分类器)
如上图所示,如果用逻辑回归来解决这个问题,首先需要构造一个包含很多非线性项的逻辑回归函数g(x).这里g仍是s型函数(即 ).我们能让函数包含很多像这的多项式,当多项式足够多时,那么你也许能够得到可以 ...
- 斯坦福大学公开课机器学习: advice for applying machine learning | deciding what to try next(revisited)(针对高偏差、高方差问题的解决方法以及隐藏层数的选择)
针对高偏差.高方差问题的解决方法: 1.解决高方差问题的方案:增大训练样本量.缩小特征量.增大lambda值 2.解决高偏差问题的方案:增大特征量.增加多项式特征(比如x1*x2,x1的平方等等).减 ...
随机推荐
- /dev被异常删除的问题
今天遇到一个问题,在执行某些操作后,发现经常报“read_urandom: /dev/urandom: open failed: No such file or directory”这个错误.后来查看 ...
- ssl证书部署问题
问:我现在得到的ssl证书是.crt和.key两个在nginx环境下部署的证书,如果我们改用是tomcat,现在把这两个文件合成了.jks给tomcat使用,合成的时候输入的jks密码是不是就是部署在 ...
- MyISAM索引和InnoDB索引的区别
首先你要知道: 无论是Myisam和Innodb引擎,如果在建表的时候没有显示的定义一行主键列的话,他内部都会自动创建一个隐藏的主键索引: 主键索引以外的索引假设称为次索引:首先Myisam和Inno ...
- solr单机版搭建
需要把solr服务器安装到linux环境: 第一步:安装linux.jdk.tomcat. [root@bogon ~]# ll total 8044 -rw-r--r--. 1 root root ...
- 51nod-1445-变色DNA(最短路)
题意:题目是说从0到n-1,我还是习惯从1到n,所以以下我都这么写,大概题意就是(i, j)==‘Y’表示可以从i颜色变成j颜色,然后问我们最少删除几个会影响结果的‘Y’,能到n这个颜色: 没有意义的 ...
- h.264并行熵解码
在前面讨论并行解码的章节中,我们专注于讨论解码的宏块重建部分,甚至把宏块重建描述成宏块解码,这是因为在解码工作中,宏块重建确实占了相当大的比重,不过解码还包含其它的部分,按照解码流程可粗略分为: 读取 ...
- Spring 使用介绍(十二)—— Spring Task
一.概述 1.jdk的线程池和任务调用器分别由ExecutorService.ScheduledExecutorService定义,继承关系如下: ThreadPoolExecutor:Executo ...
- BZOJ2150部落战争——最小路径覆盖
题目描述 lanzerb的部落在A国的上部,他们不满天寒地冻的环境,于是准备向A国的下部征战来获得更大的领土. A国是一 个M*N的矩阵,其中某些地方是城镇,某些地方是高山深涧无人居住.lanzerb ...
- xml 模块
XML ———可扩展的标记语言 也是一种通用的数据格式 之所以用它 也是因为跨平台 XML 的语法格式: 1,任何的起始标签都必须有一个结束标签. <> 起始标签 </>结束标 ...
- Matplotlib学习---用seaborn画矩阵图(pair plot)
矩阵图非常有用,人们经常用它来查看多个变量之间的联系. 下面用著名的鸢尾花数据来画一个矩阵图.从sklearn导入鸢尾花数据,然后将其转换成pandas的DataFrame类型,最后用seaborn画 ...