HashMap的resize方法中尾部遍历出现死循环问题 Tail Traversing (多线程)
正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

-----------------------正文开始---------------------------
一、背景介绍:
例如原来顺序是:
10 20 30 40
插入顺序如下
10
20 10
30 20 10
40 30 20 10
二、存在的问题:
采用队头插入的方式,导致了HashMap在“多线程环境下”的死循环问题
问题的症状
从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题。后来,我们的程序性能有问题,所以需要变成多线程的,于是,变成多线程后到了线上,发现程序经常占了100%的CPU,查看堆栈,你会发现程序都Hang在了HashMap.get()这个方法上了,重启程序后问题消失。但是过段时间又会来。而且,这个问题在测试环境里可能很难重现。
我们简单的看一下我们自己的代码,我们就知道HashMap被多个线程操作。而Java的文档说HashMap是非线程安全的,应该用ConcurrentHashMap。
但是在这里我们可以来研究一下原因。
Hash表数据结构
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷。
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的无素都需要被重算一遍。这叫rehash,这个成本相当的大。
相信大家对这个基础知识已经很熟悉了。
HashMap的rehash源代码
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已)和 arraylist 或者 linkedlist 中的clone方法是一样的 都是浅拷贝关系
foreach (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
//将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
//第一次时 newTable[i] = null
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash的过程
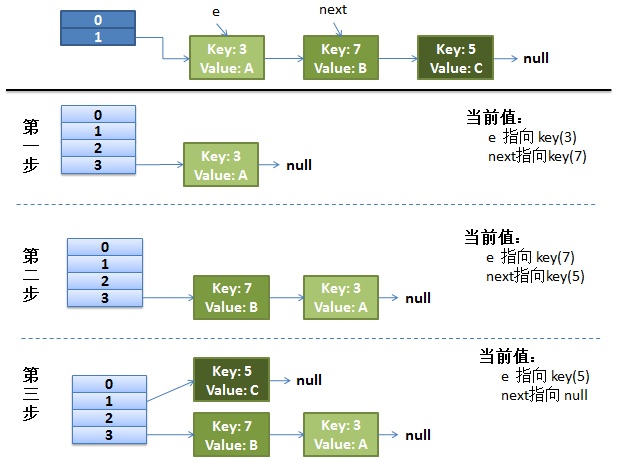
画了个图做了个演示。
- 我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
- 最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
- 接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程
并发下的Rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
int i = indexFor(e.hash, newCapacity); //假设线程一执行到这 失去了运行权限
//将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
//第一次时 newTable[i] = null e.next = newTable[i];
newTable[i] = e;
e = next;
而我们的线程二执行完成了。于是我们有下面的这个样子。
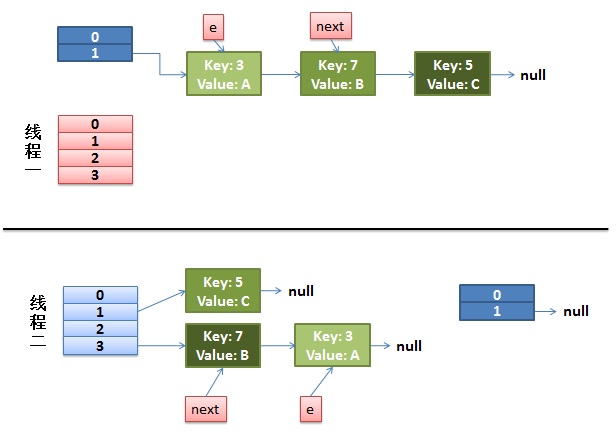
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
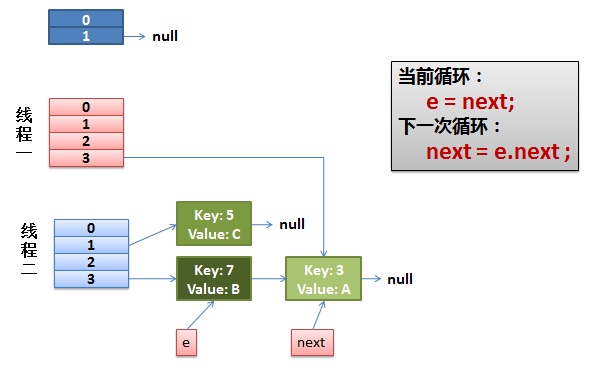
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
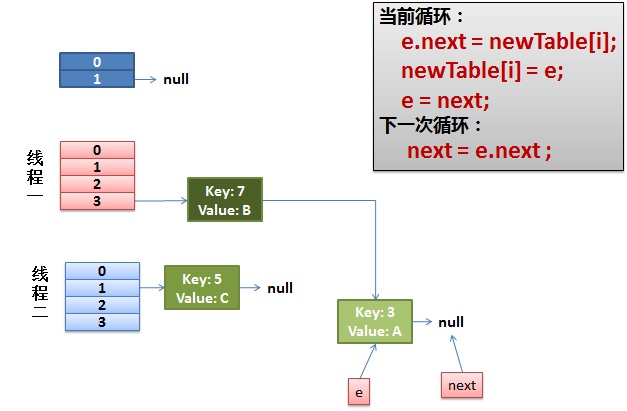
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
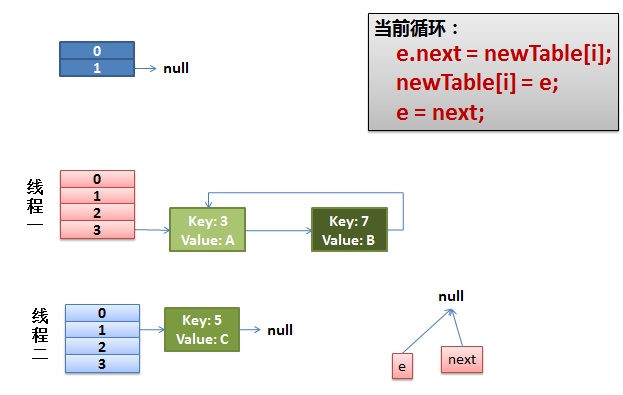
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
三、问题解决:
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null; // JDK1.8改进了rehash算法,扩容时,容量翻倍,新扩容部分,标识为hi,原来old的部分标识为lo
Node<K,V> hiHead = null, hiTail = null; // 声明了队尾和队头指针。
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
HashMap的resize方法中尾部遍历出现死循环问题 Tail Traversing (多线程)的更多相关文章
- HashMap在JDK1.8中并发操作,代码测试以及源码分析
HashMap在JDK1.8中并发操作不会出现死循环,只会出现缺数据.测试如下: package JDKSource; import java.util.HashMap; import java.ut ...
- HashMap的尾部遍历问题--Tail Traversing
在看网上HashMap的resize()设计时,提到尾部遍历. JDK1.7的HashMap在实现resize()时,新table[]的列表采用LIFO方式,即队头插入.这样做的目的是:避免尾部遍 ...
- jdk8与jdk7中hashMap的resize分析
在分析代码之前,我们先抛出下面的问题: hashmap 扩容时每个 entry 需要再计算一次 hash 吗? 我们首先看看jdk7中的hashmap的resize实现 1 void resize(i ...
- Java中如何遍历Map对象的4种方法
在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都实现了Map接口,以下方法适用于任何map实现(HashMap, TreeMap, LinkedHa ...
- 转!! Java中如何遍历Map对象的4种方法
在Java中如何遍历Map对象 How to Iterate Over a Map in Java 在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都 ...
- 【转】Java中如何遍历Map对象的4种方法
原文网址:http://blog.csdn.net/tjcyjd/article/details/11111401 在Java中如何遍历Map对象 How to Iterate Over a Map ...
- (转载)Java中如何遍历Map对象的4种方法
在Java中如何遍历Map对象 How to Iterate Over a Map in Java 在java中遍历Map有不少的方法.我们看一下最常用的方法及其优缺点. 既然java中的所有map都 ...
- OC中几种集合的遍历方法(数组遍历,字典遍历,集合遍历)
// 先分别初始化数组.字典和集合,然后分别用for循环.NSEnumerator枚举器和forin循环这三个方法来实现遍历 NSArray *array = @[@"yinhao" ...
- leetCode 94.Binary Tree Inorder Traversal(二叉树中序遍历) 解题思路和方法
Given a binary tree, return the inorder traversal of its nodes' values. For example: Given binary tr ...
随机推荐
- Spring autowire自动装配 ByType和ByName
不使用自动装配前使用的是类的引用: <?xml version="1.0" encoding="UTF-8"?> <beans xmlns=& ...
- 国内使用google搜索引擎
百度搜索 "谷歌访问助手",点击第一个搜索结果,如下: 或者直接点击链接:http://www.ggfwzs.com/ ,然后点击相应的浏览器下载谷歌访问助手,解压,将解压好的谷 ...
- 编码之痛:操作系统迁移后redis缓存无法命中
前几天一台内网服务器从ubuntu迁移到了centos,检查一切正常后就没有太在意. 今天有同事反馈迁移后的机器上的服务一个缓存总是无法获取,对比了下环境.JVM参数,尝试了war包替换等方式照样复现 ...
- Spring Cloud微服务下的权限架构调研
随着微服务架构的流行,系统架构调整,项目权限系统模块开发提上日程,需要对权限架构进行设计以及技术选型.所以这段时间看了下相关的资料,做了几个对比选择. 一.架构图 初步设想的架构如下,结构很简单:eu ...
- C# 获取 sha256
C# 获取 sha256, 输入可以是 字符串,也可以是 字节流流: 自定义的输入类型的枚举: public enum Sha26ParseType { StringType, StreamType ...
- leetcode — text-justification
import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * * Source : https:/ ...
- 项目实战2.1—nginx 反向代理负载均衡、动静分离和缓存的实现
总项目流程图,详见 http://www.cnblogs.com/along21/p/8000812.html 实验一:实现反向代理负载均衡且动静分离 1.环境准备: 机器名称 IP配置 服务角色 备 ...
- 【详解JavaScript系列】JavaScript之流程语句
一 开篇概述 本讲主要讲解JavaScript流程语句,其大致内容包括如下: 其中,常用的if,while,do..while,for在本片文章就不论述,重点论述for..in..,label,bre ...
- dubbo源码解析五 --- 集群容错架构设计与原理分析
欢迎来我的 Star Followers 后期后继续更新Dubbo别的文章 Dubbo 源码分析系列之一环境搭建 博客园 Dubbo 入门之二 --- 项目结构解析 博客园 Dubbo 源码分析系列之 ...
- Go基础系列:import导包和初始化阶段
import导入包 搜索路径 import用于导入包: import ( "fmt" "net/http" "mypkg" ) 编译器会根据 ...