线程池-Executors
一、合理使用线程池能够带来三个好处
1、减少创建和销毁线程上所花的时间以及系统资源的开销 => 减少内存开销,创建线程占用内存,创建线程需要时间,会延迟处理的请求
2、提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行
3、提高线程的客观理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控(根据系统承受能力,达到运行的最佳效果) => 避免无限创建线程引起的OutOfMemoryError【简称OOM】
二、线程池核心类
ExecutorService:线程池根接口
ScheduledExecutorService:和Timer/TimerTask类似,解决那些需要任务重复执行的问题
ThreadPoolExecutor:ExecutorService的默认实现,最主要的实现类
ScheduledThreadPoolExecutor:继承ThreadPoolExecutor,实现ScheduleExecutorService接口,周期性任务调度
三、Executors工厂创建线程池
1、Executors提供了一系列工厂方法用于创建线程池,返回的线程池都实现了ExecutorService接口
1.1、newSingleThreadExecutor(); == > 创建单一一个线程的线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
corePoolSize => 1,核心线程池的数量为1
maximumPoolSize => 1,只可以创建一个非核心线程
keepAliveTime => 0L
unit => 毫秒
workQueue => LinkedBlockingQueue
当一个任务提交时,首先会创建一个核心线程来执行任务,如果超过核心线程的数量,将会放入队列中,因为LinkedBlockingQueue是长度为Integer.MAX_VALUE的队列,可以认为是无界队列,因此忘队列中可以插入无限多的任务,在资源有限的时候容易引起OOM异常,同时因为无界队列,maximumPoolSize和keepAliveTime参数将无效,压根就不会创建非核心线程
1.2、newFixedThreadPool(int nThreads); == > 创建固定长度的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
corePoolSize => 1,核心线程池的数量为用户自己传入
maximumPoolSize => 1,和核心线程数一致,其实就没有非核心线程了
keepAliveTime => 0L
unit => 毫秒
workQueue => LinkedBlockingQueue
它和newSingleThreadExecutor类似,唯一的区别就是核心线程数不同,并且由于使用的是LinkedBlockingQueue,在资源有限的时候容易引起OOM异常
1.3、newScheduledThreadPool(int corePoolSize); == > 创建一个支持定时及周期性的任务执行的线程池,多数情况下可用来替代Timer类
1.4、newCachedThreadPool(); == > 创建一个可缓存的线程池(大小可变。按照任务数来分配线程),调用execute将重用以前构造的线程(如果线程可用)。如果现有线程没有可用的,则创建一个新线程并添加到池中。终止并从缓存中移除那些已有60秒钟未被使用的线程
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
corePoolSize => 0,核心线程池的数量为0
maximumPoolSize => Integer.MAX_VALUE,可以认为最大线程数是无限的
keepAliveTime => 60L
unit => 毫秒
workQueue => SynchronousQueue
当一个任务提交时,corePoolSize为0不创建核心线程SynchronousQueue是一个不存储元素的队列,可以理解为队列永远是满的,因此最终会创建非核心线程来执行任务。
对于非核心线程空闲60s时将会被回收。因为Integer.MAS_VALUE非常大,可以任务时可以无限创建线程的,在资源有限的情况下同样容易引起OOM异常
2、添加Runnable任务
使用executorService的execute(Runnable run)函数将任务添加到线程,线程就会自动的执行Runnable的run方法
3、关闭线程池
ExecutorService的生命周期包括三种状态:运行、关闭、终止。创建后便进入运行状态,当调用了shutdown()方法时,便进入了关闭状态,此时意味着ExecutorService不接受新的任务,但它还在执行已经提交了的任务,当所有已经提交了的任务执行完后,便到达终止状态。如果不调用shutdown()方法,ExecutorService会一直处在运行状态,不断接收新的任务,执行新的任务,服务器端一般不需要关闭它,保持一直运行即可
4、Executor执行Callable任务
Callable任务与Runnable任务不同的就是Callable任务有返回值,任务执行完成之后,他可以得到任务的返回值。返回Future对象,可以根据这个对象的isDone函数来判断是否这个对象已经得到了返回值,如果为ture,表示已经得到,这样可以使用Future的get方法皆可以得到任务的返回值
Future对象的方法
cancel(boolean):试图取消执行的任务,参数为true时直接中断正在执行的任务,否则直到当前任务完成,成功取消后返回true,否则返回false
isCancel():判断任务是否在正常执行完前被取消的
isDone():判断任务是否已完成
get():等待计算结果的返回,如果计算被取消则抛出异常
get(long timeout, TimeUtil unit):设定计算结果的返回时间,如果在规定时间内没有返回抛出TimeOutException
5、Executor执行FutureTask任务
FutureTask构造函数里接收一个Runnable或者Callable对象,然后直接将FutureTask对象作为参数放入execute方法(FutureTask类属于Runnable接口的间接子类)
6、方法shutdown()和ShutdownNow()与返回值
shutdown的作用是使当前未执行完的线程继续执行,而不再添加新的任务Task,还有shutdown不会阻塞,调用shutdown方法后,主线程main就马上结束了,而线程池会继续运行知道所有任务执行完才会停止。如果不调用shutdown方法,那么线程池会一直保持下去,以便随时执行被添加的新Task任务
shutdownNow的作用是中断所有的任务,并且抛出InterruptedException异常,前提是在Runnable中使用if(Thread.currentThread().isInterrupted() == true)语句判断当前线程的中断状态,而未执行的线程不再执行,也就是从执行队列中移除,如果没有上述if语句及抛出异常的代码,则池中正在运行的线程直到执行完毕,而未执行的线程不再执行,也从执行队列清除
方法shutdown和shutdownNow的功能是发出一个关闭大门的命令,方法isShutdown是判断这个关闭大门的命令是否发出,方法isTerminating代表大门是否正在关闭进行中,而isTerminated方法判断damned是否已经关闭了
7、execute()和submit()的区别
execute没有返回值,而submit方法可以有返回值
execute在默认的情况下异常直接抛出,不能捕获,但可以通过之定义ThreadFactory的方式进行捕获,而submit方法在默认的情况下,可以catch Exception捕获异常
8、Future的缺点
调用get()方法的时候是阻塞性的,如果调用get方法时,任务尚未执行完成,则调用get()方法时一直阻塞到此任务完成时为止。如果是这样的效果,则前面先执行的任务一旦耗时很多,则后面的任务调用get方法就呈阻塞状态,也就是排队进行等待,大大影响运行效率。也就是主线程并不能保证首先获得的是最先完成任务的返回值
9、使用CompletionService解决Future的缺点
CompletionService接口的take()方法,他的主要作用就是取得Future对象,子类ExecutorCompletionService构造接受一个Executor对象,使用submit方法提交任务,使用take方法获取Future对象,再调用get方法
take方法获取到的是最先完成任务的Future对象
四、自定义线程池
1、ThreadPoolExecutor
使用ThreadPoolExecutor类创建线程池,ThreadPoolExcutor是ExecutorService的间接子类,构造方法有很多个,而最终调用的是下图的构造
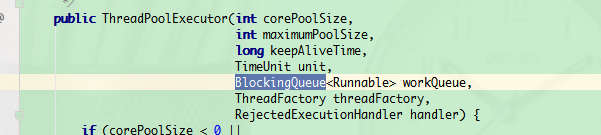
corePoolSize:核心线程最大值,包括空闲线程
- 核心线程:线程池新建的时候,如果当前线程总数小于corePoolSize,则新建的是核心线程,如果超过从corePoolSize,则新建的是非核心线程,核心线程默认情况下会一直保留在线程池中
- 如果指定ThreadPoolExecutor的allowCoreThreadTimeOut这个属性为true,那么核心线程不干活的话,超过一定时间(keepAliveTime),就会被销毁掉
maximumPoolSize:线程最大值,线程的增长始终不会超过该值。
- 线程总数 = 核心线程数 + 非核心线程数
keepAliveTime:空闲线程存活时间。当池内线程数高于corePoolSize时(非核心线程),经过多少时间多余的空闲线程才会被回收。回收前处于wait状态,allowCoreThreadTimeOut为true的时候同时作用域核心线程
unit:keepAliveTime参数的单位,可以使用TimeUnit的实例
workQueue:线程池所使用的缓冲队列,维护着等待执行的Runnable对象。当所有的核心线程都在干活的时候,新添加的任务会被添加到这个队列中等待处理,如果队列满了,则新建非核心线程执行任务。常用的workQueue类型
- SynchronousQueue(直接提交):这个队列接收到任务的时候,会直接提交给线程处理,而不保留它,如果所有线程都在工作的话,会新建一个线程来处理这个任务。所以为了保证不出现<线程数达到了maximumPoolSize而不能新建线程>的错误,使用这个队列的时候,maximumPoolSize一般指定成Integer.Max_VALUE
- LinkedBlockingQueue(无界队列):接收到任务的时候,如果当前线程小于核心线程数,则新建线程(核心线程)处理任务;如果当前线程数等于核心线程数,则进入队列等待。由于这个队列没有最大值限制,即所有超过核心线程数的任务都将添加到队列中,这就导致了maximumPoolSize的设定失效,因为总线程数永远不会超过corePoolSize
- ArrayBlockingQueue(有界队列):可以设定队列的长度,接收到任务的时候,如果没有达到corePoolSize的值,则新建线程(核心线程)执行任务,如果达到了,则入队等候,如果队列已满,则新建线程(非核心线程)执行任务,又如果总线程数到了maximumPoolSize,并且队列也满了,则发生错误
- DelayQueue:队列内元素必须实现Delayed接口。这个队列接收到任务时,首先先入队,只有达到了指定的延时时间,才会执行任务
threadFactory:线程工厂类,线程池创建线程使用的工厂。有默认实现,如果有自定义的需要则需要自己实现ThreadFactory接口并作为参数传入。
handler:线程池对拒绝任务的处理(拒绝策略)。当要创建的线程数大于线程池的最大线程数的时候,新的任务就会被拒绝,会调用这个接口的rejectedExecution()方法。默认提供了四种拒绝策略
- CallerRunsPolicy:在任务被拒绝添加之后,会调用当前线程池所在的线程去执行被拒绝的任务。就是在当前线程里执行run()方法,缺点是可能阻塞线程池所在的线程
- AbortPolicy:默认的拒绝策略,直接抛出异常
- DiscardPolicy:什么都没干。不会抛异常也不会执行
- DiscardOldestPolicy:任务被拒绝添加时,会抛弃任务队列中最旧的任务也就是最先加入队列的,再把这个新任务添加进去
总结:keepAliveTime和maximumPoolSize及BlockingQueue的类型均有关系。如果BlockingQueue是无界,那么永远不会触发maximumPoolSize,自然keepAliveTime也就没有了意义。反之,如果核心数较小,有界BlockingQueue数值又较小,同时keepAliveTime又设置的很小,如果任务频繁,那么系统就会频繁的申请回收线程
2、线程池执行任务逻辑和线程池参数的关系
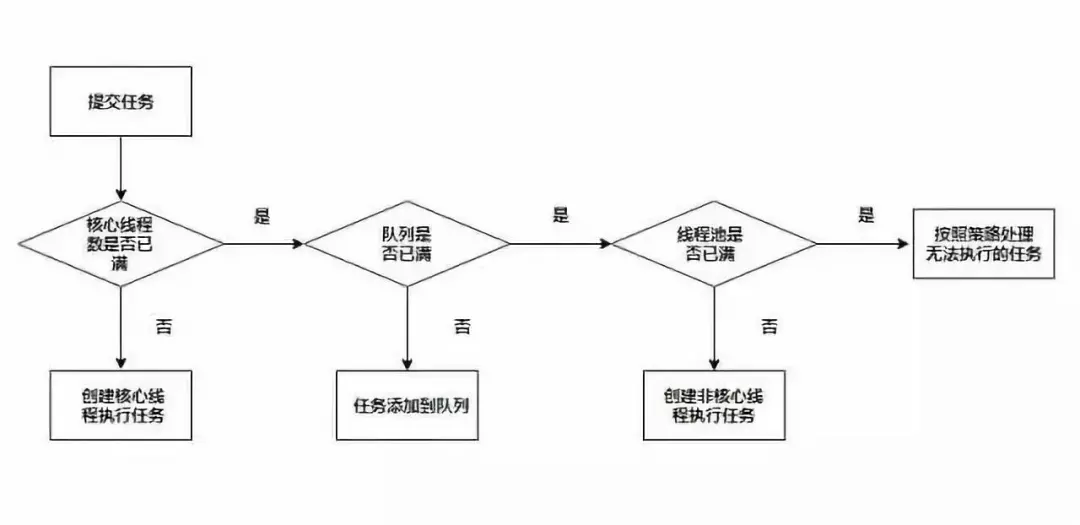
执行逻辑说明:
1、判断核心线程数是否已满,核心线程数大小和corePoolSize参数有关,未满则创建线程执行任务
2、若核心线程池已满,判断队列是否满,队列是否满和workQueue参数有关,若未满则加入队列中
3、若队列已满,判断线程池是否已满,线程池是否已满和maximumPoolSize参数有关,若未满则创建线程执行任务
4、若线程池已满,则采用拒绝策略处理无法执行的任务,拒绝策略和handler参数有关
3、ThreadPoolExecutor的执行策略
线程数量未达到corePoolSize,则新建一个线程(核心线程)执行任务
线程数量达到了corePoolSize,则将任务移入队列等待
队列已满,新建线程(非核心线程)执行任务
队列已满,总线程数又达到了maximumPoolSize,就会由RejectedExecutionHandler抛出异常
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit; public class ThreadPoolTest { public static void main(String[] args) {
//1、创建等待队列
BlockingQueue<Runnable> bqueue = new ArrayBlockingQueue<Runnable>(20);
//2、创建线程池,池中保存的线程数为3,允许的最大线程数为5
ThreadPoolExecutor pool = new ThreadPoolExecutor(3, 5, 50, TimeUnit.MILLISECONDS, bqueue);
Runnable t1 = new MyThread();
Runnable t2 = new MyThread();
Runnable t3 = new MyThread();
Runnable t4 = new MyThread();
Runnable t5 = new MyThread();
Runnable t6 = new MyThread();
Runnable t7 = new MyThread();
//3、向线程池添加任务
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
pool.execute(t4);
pool.execute(t5);
pool.execute(t6);
pool.execute(t7);
//4、关闭线程池
pool.shutdown();
}
} class MyThread implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "正在执行。。。");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
线程池-Executors的更多相关文章
- Java实现“睡排序”——线程池Executors的使用
前提 之前在知乎上看见一个有意思的排序算法——睡排序. 睡排序最早好像是4chan上一个用户用shell脚本实现的: 算法思想简洁明了:利用进程的sleep来实现 越大的数字越迟输出. 虽然像2L说的 ...
- 线程池——Executors
一 Executor框架 为了更好地控制多线程,JDK提供了一套线程框架Executor,帮助开发人员有效的进行线程控制.它们都在java.util.concurrent包中,是JDK并发包的核心.其 ...
- 线程池Executors探究
线程池用到的类在java.util.concurrent包下,核心类是Executors,通过其不同的几个方法可产生不同的线程池. 1.生成固定大小的线程池 public static Executo ...
- java 线程之executors线程池
一.线程池的作用 平时的业务中,如果要使用多线程,那么我们会在业务开始前创建线程,业务结束后,销毁线程.但是对于业务来说,线程的创建和销毁是与业务本身无关的,只关心线程所执行的任务.因此希望把尽可能多 ...
- 为什么阿里巴巴要禁用Executors创建线程池?
作者:何甜甜在吗 juejin.im/post/5dc41c165188257bad4d9e69 看阿里巴巴开发手册并发编程这块有一条:线程池不允许使用Executors去创建,而是通过ThreadP ...
- 为什么尽量不要使用Executors创建线程池
看阿里巴巴开发手册并发编程这块有一条:线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,通过源码分析禁用的原因. 线程池的优点 管理一组工作线程,通过线程池 ...
- [转]为什么阿里巴巴要禁用Executors创建线程池?
作者:何甜甜在吗 链接:https://juejin.im/post/5dc41c165188257bad4d9e69 来源:掘金 看阿里巴巴开发手册并发编程这块有一条:线程池不允许使用Executo ...
- java核心知识点学习----重点学习线程池ThreadPool
线程池是多线程学习中需要重点掌握的. 系统启动一个新线程的成本是比较高的,因为它涉及与操作系统交互.在这种情形下,使用线程池可以很好的提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考 ...
- Android学习笔记之ExecutorService线程池的应用....
PS:转眼间就开学了...都不知道这个假期到底是怎么过去的.... 学习内容: ExecutorService线程池的应用... 1.如何创建线程池... 2.调用线程池的方法,获取线程执行完毕后的结 ...
随机推荐
- Tennis Game CodeForces - 496D(唯一分解定理,费马大定理)
Tennis Game CodeForces - 496D 通过排列组合解决问题. 首先两组不同素数的乘积,是互不相同的.这应该算是唯一分解定理的逆运用了. 然后是,输入中的素数,任意组合,就是n的因 ...
- position:fixed固定定位的用法
一.position:fixed:固定定位 1.实现某个元素在可视窗口的居中位置显示 1)给自身设置宽高: 2)给自身加position:fixed: 3)用margin向左移动自身宽度的一半,向上移 ...
- eclipse设置
一.更改文件默认编码 一般每个项目及其项目中的文件的编码都要保持一致,主要是为了不让保存的内容出现乱码:一般会设置UTF-8这个编码格式 设置文件默认编码: windows-->General- ...
- maven依赖包下载地址
http://maven.org http://mvnrepository.com/
- php5.4使用dblib扩展,连接sqlserver中文乱码问题
在使用php链接sqlserver的时候,查询出来的数据,编码不稳定,一会utf8,一会出现问号.很纠结.下面的方法,可以解决此种问题.前提是dblib扩展. 如果查到的结果是乱码,更改/usr/lo ...
- 编译Hadoop 2.7.2支持压缩 转
hadoop Native Shared Libraries 使得Hadoop可以使用多种压缩编码算法,来提高数据的io处理性能.不同的压缩库需要依赖到很多Linux本地共享库文件,社区提供的二进制安 ...
- ESB简介及选型(转) http://www.cnblogs.com/skyme/archive/2012/08/06/2623414.html
什么是ESB 企业服务总线(Enterprise Service Bus,ESB)的概念是从面向服务体系架构(Service Oriented Architecture, SOA)发展而来的.SOA描 ...
- sql关联更新
/****** Script for SelectTopNRows command from SSMS ******/SELECT * FROM [LFBMP.Operating].[dbo].[Sh ...
- weui的icons示例
<!DOCTYPE html> <html lang="zh-cmn-Hans"> <head> <meta charset=" ...
- Python——安装requests第三方库
使用pip安装 在cmd下cd到这个目录下C:\Python27\Scripts,然后执行pip install requests 在cmd 命令行执行 E: 进入e盘 cd Python\pr ...