Redis数据库 02事务| 持久化| 主从复制| 集群
1、 Redis事务
Redis不支持事务,此事务不是关系型数据库中的事务;
- Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- Redis事务的主要作用就是串联多个命令防止别的命令插队;
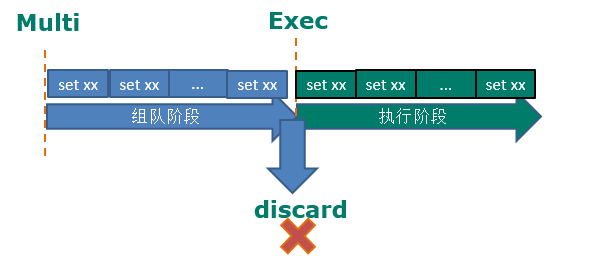
Multi(组队阶段)、Exec、discard
- 从输入Multi命令开始,输入的命令都会依次进入命令队列中(开始组队),但不会执行,至到输入Exec后,Redis会将之前的命令队列中的命令依次执行。
- 组队的过程中可以通过discard来放弃组队。
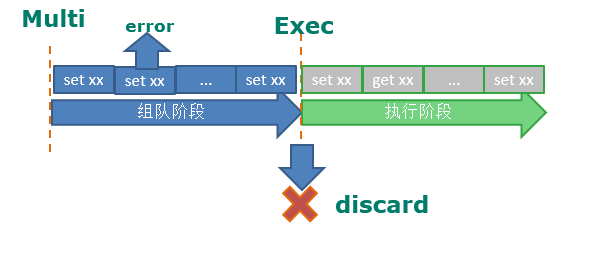
- 事务的错误处理
- 组队阶段中某个命令出现了报告错误,执行时整个的所有队列会都会被取消。
- 如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。
127.0.0.1:> multi
OK
127.0.0.1:> set k1 v1
QUEUED
127.0.0.1:> set k2 v2
QUEUED
127.0.0.1:> set k3
(error) ERR wrong number of arguments for 'set' command ##在组队阶段就错误了!
127.0.0.1:> exec #开始执行队列中的命令,会回滚,都不会执行成功!!!
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:> keys * ##回滚了,一个都没set成功!!
(empty list or set)
127.0.0.1:>
=========================================
127.0.0.1:> multi
OK
127.0.0.1:> set k1 v1
QUEUED
127.0.0.1:> set k2 v2
QUEUED
127.0.0.1:> incr k2 ##执行的时候才能发现它是错误的,组队的时候不知道的
QUEUED
127.0.0.1:> set k3 v3 #组队成功!
QUEUED
127.0.0.1:> exec ##执行队列中的命令,发现有一个错误了就跳过!!
) OK
) OK
) (error) ERR value is not an integer or out of range #incr k2失败了
) OK ##跳过了第三个命令;
127.0.0.1:> keys *
) "k3"
) "k2"
) "k1"
事务冲突的问题:
三个请求(账户中一共10000元)
一个请求想给金额减8000
一个请求想给金额减5000
一个请求想给金额减1000
如果没有事务,三个请求一个个执行,最后结果是-4000!!
有了事务:
- 悲观锁(Pessimistic Lock), 关系型数据库用的就是悲观锁; 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block(阻塞)直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
把并发的串行,第一个请求先抢到就先执行时,会把账户锁住其他请求就不能执行了,执行完之后打开锁账户变成2000了然后再锁上;执行第二个请求....发现5000>2000就不执行了。
- 乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。
没有锁,只是有一个版本号;3个请求都可以看到账户的余额,可以同时执行,而悲观锁只能一个个的执行;第一个请求先抢到就先执行它,执行完之后变成2000,他把账户版本号改变成1.1版本了;虽然第二个请求也可以执行但发现版本号变了,也是执行不了的,版本不一致了;如果第三个请求看到的是1.1版本,他就可以执行了1000 < 2000;
Redis就用的乐观锁;
- WATCH key [key ...]
- 在执行multi之前,先执行watch key1 [key2],可以监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。
127.0.0.1:> get balance
""
127.0.0.1:> watch balance
OK
127.0.0.1:> incrby balance 1000 ##事务执行之前balance被改动了,则事务被打断,执行不了事务了就;
(integer)
127.0.0.1:> multi
OK
127.0.0.1:> incrby balance
QUEUED
127.0.0.1:> exec
(nil)
127.0.0.1:> get balance
""
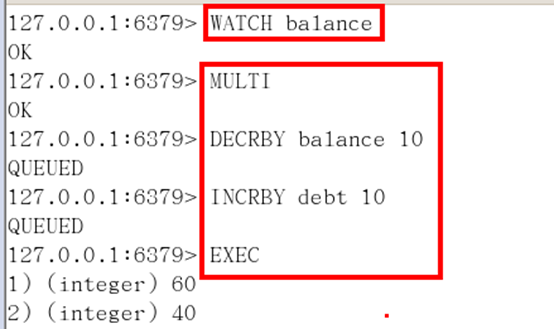

两个同时watch balance这个账户;第一个执行完了把版本号改变了,第二个看到的版本号跟之前不一样,就不能执行了。
- 单独的隔离操作
- 事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断;但是如果其他客户端把key值改变了,则事务照常进行,按照最新的key值执行事务中的操作!!!
- 没有隔离级别的概念
- 队列中的命令没有提交之前都不会实际的被执行,因为事务提交前任何指令都不会被实际执行,也就不存在“事务内的查询要看到事务里的更新,在事务外查询不能看到”这个让人万分头痛的问题
- 不保证原子性
- Redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
2、 Redis的持久化
- Redis 提供了2个不同形式的持久化方式。
- RDB (Redis DataBase)
- AOF (Append Of File)
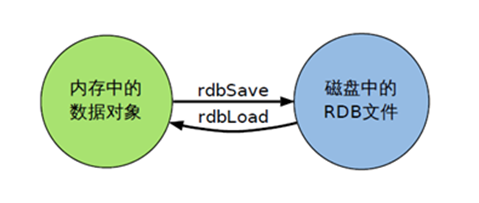
① RDB
- 在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
备份的进行:
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。
RDB的缺点是最后一次持久化后的数据可能丢失。(还没到那个持久化时间点,万一停电了,它就丢失了。)
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”,一般情况父进程和子进程会共用同一段物理内存(在持久化之前),只有进程空间的各段的内容要发生变化时(当子进程开始写,开始持久化时,会单独给子进程分配一块内存;),才会将父进程的内容复制一份给子进程。
rdb的备份
先通过config get dir 查询rdb文件的目录
将*.rdb的文件拷贝到别的地方
[root@hadoop myredis]# cp dump.rdb dump.rdb.bank 备份dump.rdb文件;
-rw-r--r--. root root 1月 : dump.rdb
-rw-r--r--. root root 1月 : dump.rdb.bank ##备份的文件
rdb的恢复
关闭Redis :shutdown
先把备份的文件拷贝到工作目录下
[root@hadoop myredis]# cp dump.rdb.bank dump.rdb
cp:是否覆盖"dump.rdb"? y 将备份文件把目标文件dump.rdb给覆盖掉级rdb的恢复;
启动Redis, 备份数据会直接加载
rdb的保存的文件
- 在redis.conf中配置文件名称,默认为dump.rdb (数据都存在这里边)
- rdb文件的保存路径,也可以修改。默认为Redis启动时命令行所在的目录下 /root/myredis (默认在当前目录下生成(你在哪个目录下运行它就会在哪里生成,会很乱);可在配置文件redis.conf 中修改;)
#把dump.rdb文件保存路径修改为:
dir /root/myredis
rdb在什么时候持久化:(自动保存策略--配置文件 | 手动保存策略shutdown、bgsave)
配置文件(vim redis.conf )中的自动保存策略
每分钟如果又10000个变化就保存一次;每5min如果有10个变化了就保存一次;每15min如果有1个变化了就保存一次;


手动保存快照(用bgsave)
- 命令save: 只管保存,其它不管,全部阻塞(直接调用rdbSave函数,它会占用阻塞Redis主进程直到保存完成为止,在阻塞期间Redis服务器不能处理客户端的任何请求)bgsave (fork一个子进程,子进程负责调用 rdbSave ,并在保存完成之后向主进程发送信号,通知保存已完成。因为 rdbSave 在子进程被调用,所以 Redis 服务器在 BGSAVE 执行期间仍然可以继续处理客户端的请求)
- save vs bgsave
shutdown & bgsave 自己的保存策略,都会持久化;;; 还有一种是配置文件中见上;
cp dump.rdb dump.rdb.bak 把dump.rdb文件复制一份为为dump.rdb.bak
flushdb shutdown
stop-writes-on-bgsave-error yes
当Redis无法写入磁盘的话(如文件太大硬盘中内存满了,就通知你),直接关掉Redis的写操作
rdbcompression yes 默认的
进行rdb保存时,将文件压缩
rdbchecksum yes
在存储快照后,还可以让Redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能 rdb的优点 ms
节省磁盘空间
恢复速度快
缺点
虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
② AOF
- 以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
- AOF默认不开启,需要手动在配置文件中配置vim redis.conf
- 可以在redis.conf 中配置文件名称,默认为 appendonly.aof

- AOF文件的保存路径,同RDB的路径一致。
- AOF和RDB同时开启,redis听谁的? 系统默认取AOF的数据
-rw-r--r--. root root 1月 : appendonly.aof #有3个key,如果执行flushdb了,要先把它给删除了不然恢复的时候会把库给删了;
-rw-r--r--. root root 1月 : dump.rdb
-rw-r--r--. root root 1月 : dump.rdb.bank #有10个key [root@hadoop myredis]# cp dump.rdb.bank dump.rdb
cp:是否覆盖"dump.rdb"? y
[root@hadoop myredis]# redis-server redis.conf
[root@hadoop myredis]# redis-cli
127.0.0.1:> keys *
) "k3"
) "k2"
) "k1"
听AOF的;RDB有可能缺失,但AOF不会有缺失;AOF默认是关闭,如果同时开启默认是听AOF的;
AOF文件故障备份
- AOF的备份机制和性能虽然和RDB不同, 但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载。
AOF文件故障恢复
- AOF文件的保存路径,同RDB的路径一致。
- 如遇到AOF文件损坏,可通过 redis-check-aof --fix appendonly.aof 进行恢复
[root@hadoop myredis]# redis-check-aof --fix appendonly.aof
0x 6e: Expected prefix 'a', got: '*'
AOF analyzed: size=, ok_up_to=, diff=
This will shrink the AOF from bytes, with bytes, to bytes
Continue? [y/N]: y
Successfully truncated AOF
AOF同步频率设置(redis.conf配置文件)
- 始终同步,每次Redis的写入都会立刻记入日志
- 每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
- 把不主动进行同步,把同步时机交给操作系统。

Rewrite
- AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof。
Redis如何实现重写?
- 如果超过了规定大小的命令,它就会它你有重复的命令给简写;大小就减少了;
- AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
何时重写:
- 重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。

- 系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
AOF的优点
- 备份机制更稳健,丢失数据概率更低。
- 可读的日志文本,通过操作AOF稳健,可以处理误操作。
AOF的缺点
- 比起RDB占用更多的磁盘空间。
- 恢复备份速度要慢。
- 每次读写都同步的话,有一定的性能压力。
- 存在个别Bug,造成恢复不能。

用哪个好
- 官方推荐两个都启用。
- 如果对数据不敏感,可以选单独用RDB。
- 不建议单独用 AOF,因为可能会出现Bug。
- 如果只是做纯内存缓存,可以都不用。
3、 Redis的主从复制
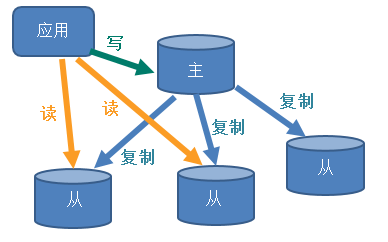
- 主从复制,就是主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
用处
- 读写分离,性能扩展
- 容灾快速恢复
 一山不容二虎,不能有两个主机;
一山不容二虎,不能有两个主机;
配从(服务器)不配主(服务器)
① 一主二仆模式的配置
- 拷贝多个redis.conf文件include
- 开启daemonize yes #即让服务在后台启动
- Pid文件名字pidfile
- 指定端口port
- Log文件名字
- Dump.rdb名字dbfilename
- Appendonly 关掉或者换名字
具体配置方法:6379为主机,6380| 6381为从机;
① vim redis6379.conf #创建redis6379.conf文件,可在redis.conf文件中找
include /root/myredis/redis.conf
pidfile /var/run/redis_6379.pid
port
dbfilename dump6379.rdb ② cp redis6379.conf redis6380.conf
cp redis6379.conf redis6381.conf ③ vim redis6380.conf :%S//6380 ;修改端口号
vim redis6381.conf :%S// slave-priority 10 ;修改端口号和; slave-priority 100默认值为100,值越小优先级越高;主机down,继承主机它继位; ④开启3个服务器和3个客户端
redis-server redis6379.conf
redis-server redis6380.conf
redis-server redis6381.conf redis-cli -p
redis-cli -p
redis-cli -p info replication
⑤ 配置从机 6379为主,| 6381为从
slaveof 127.0.0.1
slaveof 127.0.0.1
info replication
- info replication 打印主从复制的相关信息
- slaveof <ip> <port> 成为某个实例的从服务器
一主二仆的一些问题:
1 切入点问题?slave1、slave2是从头开始复制还是从切入点开始复制?比如从k4进来,那之前的123是否也可以复制;从头开始复制,同步主的所有数据
2 从机是否可以写?set可否?
3 主机shutdown后情况如何?从机是上位还是原地待命,原地待命!!
4 主机又回来了后,主机新增记录,从机还能否顺利复制? 可以的
5 其中一台从机down后情况如何?依照原有它能跟上大部队吗?
可以,重新slaveof “127.0.0.1” “6380“ ,都可以获得master的信息
主机:
set k1 v1
keys * 从机只能读,不能写; 主机挂了:从机还是slave,会显示主机down掉了;主机回来,从机照样听从,信息都可以获得;
127.0.0.1:> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:
master_link_status:down
主机shutdown又回来:
127.0.0.1:> info replication
# Replication
role:master
connected_slaves:
slave0:ip=127.0.0.1,port=,state=online,offset=,lag=
slave1:ip=127.0.0.1,port=,state=online,offset=,lag=
master_repl_offset:
repl_backlog_active:
repl_backlog_size:
repl_backlog_first_byte_offset:
repl_backlog_histlen:
信息都可以获取到; 从机挂了,主机就把它驱逐了,
127.0.0.1:> info replication
# Replication
role:master
connected_slaves:
slave0:ip=127.0.0.1,port=,state=online,offset=,lag=
从机再回来,之前保留的数据还可以获得,主机新添加的数据就无法获取,要想获取就要重新拜山头了slaveof 127.0.0.1 ;它会马上同步主机中的数据
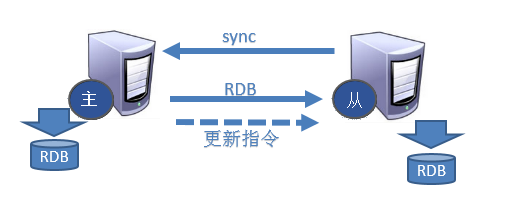
从机的复制原理
- 每次从机联通后,都会给主机发送sync指令
- 主机立刻进行存盘操作,发送RDB文件,给从机
- 从机收到RDB文件后,进行全盘加载
- 之后每次主机的写操作,都会立刻发送给从机,从机执行相同的命令
② 薪火相传 (主机在金字塔塔尖,徒弟还是可以收徒弟,徒弟的徒弟也可以收徒弟)
- 上一个slave可以是下一个slave的Master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
- 用 slaveof <ip> <port>
- 中途变更转向:会清除之前的数据,重新建立拷贝最新的
- 风险是一旦某个slave宕机,后面的slave都没法备份

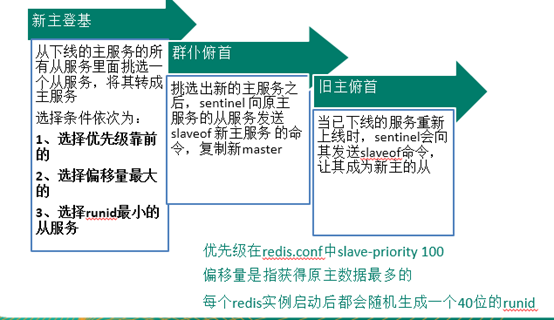
③ 反客为主
- 当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。。
- 当它成为master时,原来的主的slave还依照原本的master; 若主回来了都是可以获得原来的key的
- 用 slaveof no one 将从机变为主机。(而其他从机还是原地待命,还是原来的从机)
哨兵模式(sentinel)
- 反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库.
配置哨兵
- 调整为一主二仆模式
- 自定义的/myredis目录下新建sentinel.conf文件
- 在配置文件中填写内容:
sentinel monitor mymaster 127.0.0.1 6379 1
- 其中mymaster为监控对象起的服务器名称, 1 为 至少有多少个哨兵同意迁移的数量。
- 执行redis-sentinel /myredis/sentinel.conf 启动哨兵
slave-priority 100默认值为100,值越小优先级越高;主机down,继承主机它继位;如果默认值一样就看数据量,数据量一样就看id,id越小优先级越高;
[root@hadoop myredis]# vim sentinel.conf
sentinel monitor mymaster 127.0.0.1
启动哨兵:
[root@hadoop myredis]# redis-sentinel sentinel.conf
127.0.0.1:> shutdown 主机down掉;6381继位!! 127.0.0.1:> info replication
# Replication
role:master
connected_slaves:
slave0:ip=127.0.0.1,port=,state=online,offset=,lag=
如果原来的主机又回来了,它就会自动变成从机了!!不用再拜山头。
127.0.0.1:> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:
master_link_status:up
master_last_io_seconds
故障恢复
4、 redis的集群 (去中心化式的)
- 容量不够,redis如何进行扩容?
- 并发写操作, redis如何分摊?
- Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
- Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
至少6台机器,3台主机,3台从机(数据的备份);无论查询哪台机器上的信息,都可以从任何机器上进去取查询,它会自动帮你找到相应的信息的机器;
1、安装ruby环境
- 能上网:
rm -rf *.rdb 安装之前先把它们删除掉
执行yum install ruby
执行yum install rubygems
2、拷贝redis-3.2.0.gem到/opt目录下
alt+p
3、执行在opt目录下执行 gem install --local redis-3.2.0.gem
vim redis6379.conf:
include /root/myredis/redis.conf
pidfile /var/run/redis_6379.pid
port
dbfilename dump6379.rdb
cluster-enabled yes
cluster-config-file nodes-.conf
cluster-node-timeout
复制copy其他的,改端口号:
cp redis6379.conf redis6380.conf
制作6个实例,6379,6380,6381,6389,6390,6391
- 拷贝多个redis.conf文件
- 开启daemonize yes
- Pid文件名字
- 指定端口
- Log文件名字
- Dump.rdb名字
- Appendonly 关掉或者换名字
安装redis cluster配置修改
- cluster-enabled yes 打开集群模式
- cluster-config-file nodes-6379.conf 设定节点配置文件名
- cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换,换主 。
将六个节点合成一个集群
- 先把6个服务启动了: [root@kris myredis]# redis-server redis6379.conf .............
- 组合之前,请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。
[root@hadoop myredis]# redis-server redis6379.conf
[root@hadoop myredis]# redis-server redis6380.conf
[root@hadoop myredis]# redis-server redis6381.conf
[root@hadoop myredis]# redis-server redis6389.conf
[root@hadoop myredis]# redis-server redis6390.conf
[root@hadoop myredis]# redis-server redis6391.conf
---->确保生成6个节点文件
-rw-r--r--. root root 2月 : nodes-.conf
-rw-r--r--. root root 2月 : nodes-.conf
-rw-r--r--. root root 2月 : nodes-.conf
-rw-r--r--. root root 2月 : nodes-.conf
-rw-r--r--. root root 2月 : nodes-.conf
-rw-r--r--. root root 2月 : nodes-.conf
合体:
- cd /opt/redis-3.2.5/src
- ./redis-trib.rb create --replicas 1 192.168.1.100:6379 192.168.1.100:6380 192.168.1.100:6381 192.168.1.100:6389 192.168.1.100:6390 192.168.1.100:6391
- 此处不要用127.0.0.1, 请用真实IP地址
- 通过 cluster nodes 命令查看集群信息
[root@hadoop myredis]# cd /opt/redis-3.2./src 在这个目录下的下面这个文件
-rwxrwxr-x. root root 10月 redis-trib.rb
[root@hadoop src]# ./redis-trib.rb create --replicas 192.168.1.100: 192.168.1.100: 192.168.1.100: 192.168.1.100: 192.168.1.100: 192.168.1.100:
>>> Creating cluster
>>> Performing hash slots allocation on nodes...
Using 3 masters:
192.168.1.100:
192.168.1.100:
192.168.1.100:
Adding replica 192.168.1.100: to 192.168.1.100:
Adding replica 192.168.1.100: to 192.168.1.100:
Adding replica 192.168.1.100: to 192.168.1.100:
M: 9385a8e93b21bc59011661170a4b42ba6b9de9db 192.168.1.100:6379 ##地址
slots:- ( slots) master ##插槽,看key值在哪个范围就放在哪个机器
M: 2cb3f766e4874e1518b9ce6dc119f882bef43dd2 192.168.1.100:
slots:- ( slots) master
M: 5afbb8d846826a56db5dc668020911067f4d2604 192.168.1.100:
slots:- ( slots) master
S: 79d50a02d153463b34c21e1decd9db728bae1441 192.168.1.100:
replicates 9385a8e93b21bc59011661170a4b42ba6b9de9db 它的主机就是6379了,地址是相同的;
S: e44a41e31d40d05ce33baf18a233bda62d5add84 192.168.1.100:
replicates 2cb3f766e4874e1518b9ce6dc119f882bef43dd2
S: aa52dceea9257a3641ffadab8832d2fdd2817f05 192.168.1.100:
replicates 5afbb8d846826a56db5dc668020911067f4d2604 选项 --replicas 表示我们希望为集群中的每个主节点创建一个从节点
启动客户端:
[root@hadoop myredis]# redis-cli -p
127.0.0.1:> cluster nodes
9385a8e93b21bc59011661170a4b42ba6b9de9db 192.168.1.100: myself,master - connected -
e44a41e31d40d05ce33baf18a233bda62d5add84 192.168.1.100: slave 2cb3f766e4874e1518b9ce6dc119f882bef43dd2 connected
aa52dceea9257a3641ffadab8832d2fdd2817f05 192.168.1.100: slave 5afbb8d846826a56db5dc668020911067f4d2604 connected
2cb3f766e4874e1518b9ce6dc119f882bef43dd2 192.168.1.100: master - connected -
5afbb8d846826a56db5dc668020911067f4d2604 192.168.1.100: master - connected -
79d50a02d153463b34c21e1decd9db728bae1441 192.168.1.100: slave 9385a8e93b21bc59011661170a4b42ba6b9de9db connected
...
[OK] All 16384 slots covered.
6379、6380、6381为3个master | 6389、6390、6391为3个slave
redis cluster 如何分配这六个节点?
- 一个集群至少要有三个主节点。
- 选项 --replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
- 分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
什么是slots
- 一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
- 集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5500 号插槽。
节点 B 负责处理 5501 号至 11000 号插槽。
节点 C 负责处理 11001 号至 16383 号插槽。
在集群中录入值
- 在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。
- redis-cli客户端提供了 –c 参数实现自动重定向。
如 redis-cli -c –p 6379 登入后,再录入、查询键值对可以自动重定向。
[root@hadoop myredis]# redis-cli -c -p 6379
127.0.0.1:> set k1 v1
-> Redirected to slot [] located at 192.168.1.100:6381 ##不管是主还是从都是可以set,操作数据的
OK
192.168.1.100:> keys *
) "k1"
192.168.1.100:> set k2 v2
-> Redirected to slot [] located at 192.168.1.100:
OK
192.168.1.100:>
- 不在一个slot下的键值,是不能使用mget,mset等多键操作。
- 可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。
查询集群中的值
- CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。
- CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的键值对数量。
- CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键。
192.168.1.100:> CLUSTER KEYSLOT k1
(integer)
192.168.1.100:> CLUSTER COUNTKEYSINSLOT
(integer) ##要在k1所在的服务器上才可以看到
192.168.1.100:> CLUSTER KEYSLOT k2
(integer)
192.168.1.100:> CLUSTER COUNTKEYSINSLOT
(integer)
192.168.1.100:> CLUSTER GETKEYSINSLOT
) "k2"
192.168.1.100:> CLUSTER GETKEYSINSLOT
) "k2"
192.168.1.100:> set k3 v3
OK
192.168.1.100:> CLUSTER GETKEYSINSLOT
) "k2" 192.168.1.100:> keys *
) "k2"
故障恢复
- 如果主节点下限?从节点能否自动升为主节点? 例如6379down掉,则从机6389就会自动升为主节点成为master;
- 主节点恢复后,主从关系会如何? 原来的主节点6379恢复后,则它就自动变成从机了;数据之间都是自动同步的;
192.168.1.100:> info replication
# Replication
role:master
connected_slaves:
slave0:ip=192.168.1.100,port=6389,state=online,offset=,lag=
192.168.1.100:> shutdown
[root@hadoop myredis]# redis-server redis6379.conf
[root@hadoop myredis]# redis-cli
127.0.0.1:> keys *
) "k2"
) "k3"
) "k6" ##6389升为master,set值数据就可以同步过来;
127.0.0.1:> info replication
# Replication
role:slave
master_host:192.168.1.100
master_port:
- 如果所有某一段插槽的主从节点都当掉,redis服务是否还能继续? 主从都down掉,再启动就可以继续了;
- redis.conf中的参数 cluster-require-full-coverage
5、 集群的Jedis开发
public class JedisClusterTest {
public static void main(String[] args) {
Set<HostAndPort> set =new HashSet<HostAndPort>();
set.add(new HostAndPort("192.168.1.100",6379));
JedisCluster jedisCluster=new JedisCluster(set);
jedisCluster.set("k1", "v1");
System.out.println(jedisCluster.get("k1"));
}
}
Redis 集群提供了以下好处:
- 实现扩容
- 分摊压力
- 无中心配置相对简单
Redis 集群的不足:
- 多键操作是不被支持的
- 多键的Redis事务是不被支持的。lua脚本不被支持。
- 由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。
Redis数据库 02事务| 持久化| 主从复制| 集群的更多相关文章
- Linux--6 redis订阅发布、持久化、集群cluster、nginx入门
一.redis发布订阅 Redis 通过 PUBLISH .SUBSCRIBE 等命令实现了订阅与发布模式. 其实从Pub/Sub的机制来看,它更像是一个广播系统,多个Subscriber可以订阅多个 ...
- Quartz.net 3.x使用总结(二)——Db持久化和集群
上一篇简单介绍了Quartz.net的概念和基本用法,这一篇记录一下Quartz.net通过数据库持久化Trigger和Jobs等数据,并简单配置Quartz.net的集群. 1.JobStore介绍 ...
- Linux下redis 的部署、主从与集群
老男孩Python全栈6期——redis--------------------------Linux 操作系统 默认的内存管理机制RSS:page cache:anno page:Linux操作系统 ...
- redis 5.0.3 讲解、集群搭建
REDIS 一 .redis 介绍 不管你是从事Python.Java.Go.PHP.Ruby等等... Redis都应该是一个比较熟悉的中间件.而大部分经常写业务代码的程序员,实际工作中或许只用到了 ...
- Redis安装(单机及各类集群,阿里云)
Redis安装(单机及各类集群,阿里云) 前言 上周,我朋友突然悄悄咪咪地指着手机上的一篇博客说,这是你的博客吧.我看了一眼,是之前发布的<Rabbit安装(单机及集群,阿里云>.我朋友很 ...
- Redis详解(七)——集群
Redis详解(七)--集群 Redis3.0版本之前,可以通过Redis Sentinel(哨兵)来实现高可用 ( HA ),从3.0版本之后,官方推出了Redis Cluster,它的主要用途是 ...
- Redis系列5:深入分析Cluster 集群模式
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 Redis系列3:高可用之主从架构 Redis系列4:高可用之Sentinel(哨兵模式) 1 背景 前面我们 ...
- t持久化与集群部署开发详解
Quartz.net持久化与集群部署开发详解 序言 我前边有几篇文章有介绍过quartz的基本使用语法与类库.但是他的执行计划都是被写在本地的xml文件中.无法做集群部署,我让它看起来脆弱不堪,那是我 ...
- CentOSserverMysql主从复制集群结构
在配置Mysql数据库主从复制集群时间,以确保: 1.主从server操作系统版本号和位数一致. 2.Mysql版本号一致. 为了保证稳定性,最好server操作系统和Mysql数据库环境一致. Ce ...
随机推荐
- [记录]一个有趣的url请求(nodejs)
1 前言 IDE是webstrom,跟项目编程语言,应该没有多大关系. 2 现象 两个看起来是一样的url,但是一个能访问一个不能访问. 然后,复制url到console中发现了差异,分别是:file ...
- Go语言环境安装&搭建(Linux)
Linux的东西果然不记不行啊~ 下载&安装 下载 我们先找到linux版的下载链接 https://golang.org/dl/ 打开网址找到Linux对应的链接右键复制下载地址 然后连接服 ...
- Oauth2.0 QQ&微信&微博实现第三方登陆
一.写在前面 目前对于大多数的App或Web网站都支持有第三方登陆这个功能,用户可使用 QQ/ 微信/ 微博 帐号快速登录你的网站,降低注册门槛,为你的网站带来海量新用户.最近在新项目上刚好用到了,在 ...
- Confluence 6 配置索引语言
修改你 Confluence 的索引语言将有助于你提高搜索的准确性,如果你网站使用的主要语言是除了英语以外的其他语言. Confluence 可以支持下面语言的的内容索引: Arabic Brazil ...
- python魔法函数之__getattr__与__getattribute__
getattr 在访问对象的属性不存在时,调用__getattr__,如果没有定义该魔法函数会报错 class Test: def __init__(self, name, age): self.na ...
- gnuradio 创建动态库 libftd3xx.so
首先还是创建好模块gr-kcd cd gr-kcd 打开CMakeLists.txt cmake_minimum_required(VERSION 2.6) project(gr-kcd CXX C) ...
- 第十六单元 yum管理RPM包
yum的功能 本地yum配置 光盘挂载和镜像挂载 本地yum配置 网络yum配置 网络yum配置 Yum命令的使用 使用yum安装软件 使用yum删除软件 安装组件 删除组件 清除缓存 查询 课后作业 ...
- python并发编程之多进程2-------------数据共享及进程池和回调函数
一.数据共享 1.进程间的通信应该尽量避免共享数据的方式 2.进程间的数据是独立的,可以借助队列或管道实现通信,二者都是基于消息传递的. 虽然进程间数据独立,但可以用过Manager实现数据共享,事实 ...
- Django框架之第三篇模板语法(重要!!!)
一.什么是模板? 只要是在html里面有模板语法就不是html文件了,这样的文件就叫做模板. 二.模板语法分类 一.模板语法之变量:语法为 {{ }}: 在 Django 模板中遍历复杂数据结构的关键 ...
- Op-level的快速算法
十岁的小男孩 本文为终端移植的一个小章节. 目录 引言 FFT Conv2d (7x7, 9x9) Winograd Conv2d (3x3, 5x5) 引言 本节针对CNN进行加速计算的,主要有以下 ...