Webmagic 爬虫框架 爬取马蜂窝、携程旅游、汽车之家游记信息
WebMagic学习
遇到的问题
Log4j错误
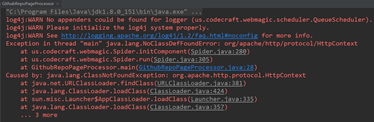
解决:在src目录下添加配置文件 log4j.properties
log4j.rootLogger=INFO, stdout, file
log4j.logger.org.quartz=WARN, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=C:\\log4j\\webmagic\\webmagic.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
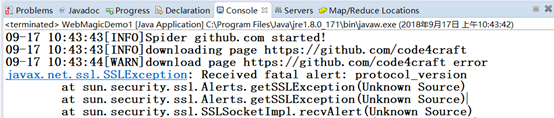
协议错误,有的网站需要的SSL协议比较高,尽量使用做高版本的jar包
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
状态码错误

解决:主要是与site有关,下边两种解决办法暂时还没弄明白
private Site site = Site
.me()
.setRetryTimes(3)
.setSleepTime(3000)
.setUserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64; rv:56.0) Gecko/20100101 Firefox/56.0");
或者
private Site site = Site
.me()
.setRetryTimes(3)
.setSleepTime(3000)
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36");
缺少HttpContext类
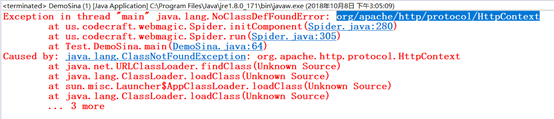
解决:添加HTTPContext的Jar包
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
Webmagic学习配置
创建一个maven项目
在pom中引用jar包,引用完之后就基本好了
<dependencies>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.4</version>
</dependency>
</dependencies>
Webmagic学习参考
参考博客:
参考博客:https://www.xttblog.com/?s=webmagic
其中有些案例,我没有运行成功,我会将我自己的案例发布上去(src/File目录下为正式爬取的案例,src/Test下的程序为学习过程中找到的案例,也有自己测试的案例) 动态页面爬取参考 http://webmagic.io/docs/zh/posts/chx-cases/js-render-page.html Webmagic的使用说明 http://webmagic.io/docs/zh/
案例
案例1 汽车之家游记爬取 (src/File/Test2)
如何判断页面数据为通过js动态获取的???
判断页面是否为js渲染的方式比较简单,在浏览器中直接查看源码(Windows下Ctrl+U,Mac下command+alt+u),如果找不到有效的信息,则基本可以肯定为js渲染。
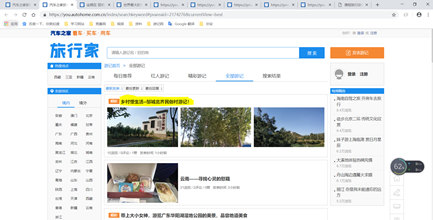
Windows中按Ctrl+U,再按Ctrl+F查找其中的内容,我查找的是第一个游记,结果没有找到,这就判定该页面的数据是通过js动态获取的。

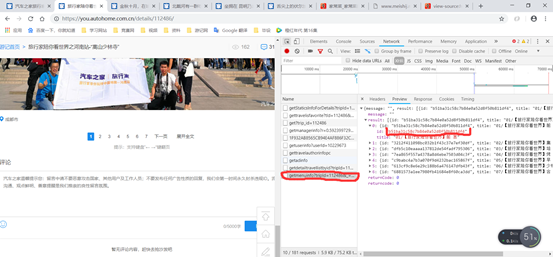
如果判定该页面的数据是通过JS动态获取的,就开始找获取数据的链接:例如:此时只有这几个请求,当点击第二页的时候,又出现了几个链接。


点击新出现的第一个链接,选择preview,出现返回的数据,从中找到详情页的链接。也可以直接复制这个链接,在新的标签页打开(https://you.autohome.com.cn/summary/getsearchresultlist?ps=20&pg=1&type=3&tagCode=&tagName=&sortType=3) 按照上边,同样的点击第三页也同样出现了一个新的请求链接https://you.autohome.com.cn/summary/getsearchresultlist?ps=20&pg=2&type=3&tagCode=&tagName=&sortType=3) 比较这两个链接,发现这两个链接只是pg这个参数不同,根据这两个链接一个是第一页,一个是第二页,可以推测出每个列表页的链接

如果在新的标签页打开(我的谷歌浏览器安装了一个JsonView插件,查看json格式的数据比较方便)
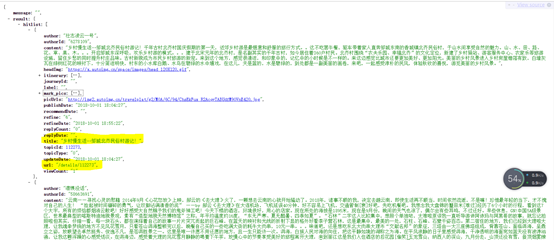
这里就有详情页的地址,我们再看一下这个详情页的具体地址,链接后边的那个暂时不知道是什么用,大概只是一个标识作用,删去也可以访问,这样就可以根据上边的/details/112251拼接详情页的地址,这样知道了列表页的链接和详情的链接,就可以将这上面的游记都爬取下来了


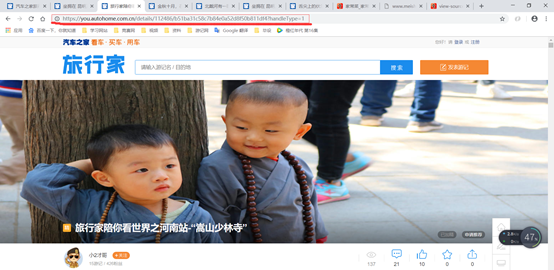
当初我也就这样试了试,结果能爬下来,也就没管。但是后来查看这些游记,发现有的游记都只有一半,并不全,后来我又看网页,发现有的网页是只有一页(比如上边那个游记),有的网页有好几页(https://you.autohome.com.cn/details/112486#pvareaid=2174234),但时候后边附带着一个扩展全文的按钮,这时候就需要寻找全文的链接,否则爬取的只是一半的内容

-
单页面游记的随机数

获取这个随机数之后,就可以拼接这个完整页面的链接,然后将链接加入带爬取队列。然后就跟正常的爬取一样了
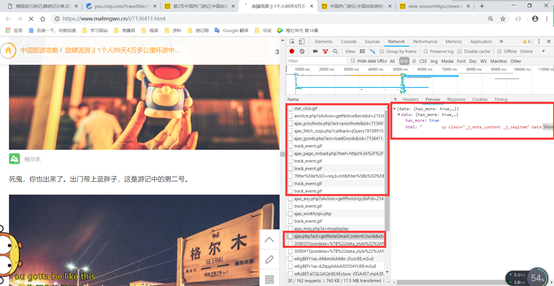
案例2 马蜂窝旅游游记爬取(能爬取数据,但是数据爬不全)(src/File/Test0)
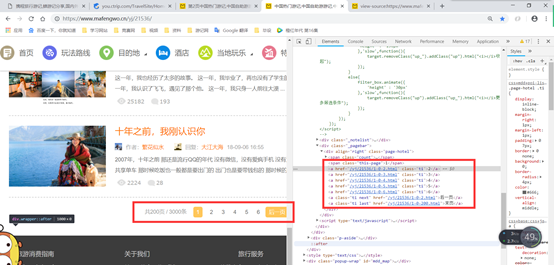
马蜂窝的爬取比较简单,只是最简单的列表页-详情页格式,只是在翻页的时候,页面只有5页,再看看每个列表页的格式(https://www.mafengwo.cn/yj/21536/1-0-2.html) 只是最后的数不同,应该就是代表页数。通过循环拼接链接,并将链接加入带爬取队列
但是这里有一个问题还没有解决:马蜂窝的游记都比较长,为了快速加载,每个游记都是分成几次加载,比如刚打开页面的时候,只是显示上边的一部分,当下滑到最下边的时候,就会JS请求继续获取下边的页面
当随着下滑,会加载出剩下的页面数据

类似的,随着游记的长度不同,会有不同的加载次数,按照一般过程,都会要拼接加载的链接,然后获取数据,追加到同一个文件中,但是通过观察这几个链接,发现他们都有一个随机数,并且这个随机数并没有在页面中找到,导致现在爬取的数据只有一部分
{kind=link}
{kind=link}
{kind=link}
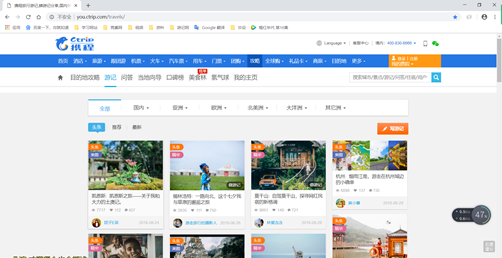
案例3 携程旅游游记爬取(src/File/Test1_1)
携程旅游也是一个动态获取的页面,只不过他的动态获取只是翻页的时候的列表页是动态获取的,具体的详情页是正常的。所以只要获取翻页的链接就跟正常的列表-详情页的爬取是一样的了。
这个网站没有具体的翻页按钮,每次向下滑动页面,就会动态加载下一页的游记列表
这样就找到了翻页的链接 (http://you.ctrip.com/TravelSite/Home/IndexTravelListHtml?p=2&Idea=0&Type=100&Plate=0), 根据上边的链接发现只有那个p属性不同,应该是是代表页数。拼接这个链接,加入带爬取队列就可以了
{kind=link}
{kind=link}
欢迎大家访问(Star、Fork)
GitHub地址 https://github.com/zhangHaoNiHao/WebMagicWebmagic 爬虫框架 爬取马蜂窝、携程旅游、汽车之家游记信息的更多相关文章
- 手把手教大家如何用scrapy爬虫框架爬取王者荣耀官网英雄资料
之前被两个关系很好的朋友拉入了王者荣耀的大坑,奈何技术太差,就想着做一个英雄的随查手册,这样就可以边打边查了.菜归菜,至少得说明咱打王者的态度是没得说的,对吧?大神不喜勿喷!!!感谢!!废话不多说,开 ...
- python-scrapy爬虫框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏 ...
- scrapy爬虫框架爬取招聘网站
目录结构 BossFace.py文件中代码: # -*- coding: utf-8 -*-import scrapyfrom ..items import BossfaceItemimport js ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 【爬虫问题】爬取tv.sohu.com的页面, 提取视频相关信息
尝试解决下面的问题 问题: 爬取tv.sohu.com的页面, 提取视频相关信息,不可用爬虫框架完成 何为视频i关信息?属性有哪些? 需求: 做到最大可能的页面覆盖率 *使用httpClient 模拟 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- Java爬虫一键爬取结果并保存为Excel
Java爬虫一键爬取结果并保存为Excel 将爬取结果保存为一个Excel表格 官方没有给出导出Excel 的教程 这里我就发一个导出为Excel的教程 导包 因为个人爱好 我喜欢用Gradle所以这 ...
- scrapy-redis实现爬虫分布式爬取分析与实现
本文链接:http://blog.csdn.net/u012150179/article/details/38091411 一 scrapy-redis实现分布式爬取分析 所谓的scrapy-redi ...
随机推荐
- 微信小程序之弹出操作菜单
<view class="List_count" bindtap="actioncnt"> <view class="img&quo ...
- WRF 安装备忘
▶ n 年前在笔记本上安装 WRF 的一个过程 ● 安装 cpp,csh,m4,quota,samba # apt-get install cpp csh m4 quota samba ● 网上教程有 ...
- 深入理解Java虚拟机读书笔记4----虚拟机类加载机制
四 虚拟机类加载机制 1 类加载机制 ---概念:虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型. -- ...
- part2
一. 列表.元组操作 切片:取多个元素 #!/usr/bin/env python # _*_ coding:utf-8 _*_ #切片:取多个元素 names = ['cai','xiao','lo ...
- 序列号多个input输入demo
<input class="inputs" type="text" maxlength="4" /> <input cla ...
- Kafka运维填坑(转)
前提: 只针对Kafka 0.9.0.1版本; 说是运维,其实偏重于问题解决; 大部分解决方案都是google而来, 我只是作了次搬运工; 有些问题的解决方案未必一定是通用的, 若应用到线上请慎重; ...
- sphinx-2.1.9的安装使用
1.下载/编译安装 cd /usr/local/src wget http://sphinxsearch.com/files/sphinx-2.1.9-release.tar.gz tar -xf s ...
- express 内存溢出问题分析定位
一.现象 1. 如下报错 FATAL ERROR: CALL_AND_RETRY_LAST Allocation failed - JavaScript heap out of memory 1: n ...
- C语言顺序栈
10进制转任何进制 #include<stdio.h> #include<stdlib.h>#define maxSize 30typedef int DataType;typ ...
- asp.net mvc 使用NPOI插件导出excel
/// <summary> /// 交易账单 导出交易列表 /// </summary> /// <returns></returns> public ...