并查集 Union-Find
并查集能做什么?
1.连接两个对象;
2.查询两个对象是否在一个集合中,或者说两个对象是否是连接在一起的。
并查集有什么应用?
1. Percolation问题、
2. 无向图连通子图个数
3. 最近公共祖先问题
4. Kruskal最小生成树
5. 社交网络 等等
并查集数据结构:
并查集是一种树形的数据结构,处理不相交集合的合并和查询操作。
并查集常用的启发式策略:路径压缩,按秩合并(或按集合元素个数合并)
路径压缩是为了加快查找的效率,让树变得竟可能的平。
按秩合并(或按集合元素个数合并)是一种加权合并的策略,让包含较少节点的根指向较多节点的根。
初始化:每个元素自身代表一个集合
void init(int n) {
for (int i = 0; i <= n; i++) {
fa[i] = i;
rank[i] = 0;
}
}
查找:找到当前集合的最顶端元素,并且在查找的过程中进行路径压缩,下面是三种查找的写法,第一种递归查找并压缩路径,第二种显式的进行查找和压缩,第三种两次遍历,第一次找根,第二次进行路径压缩。
int find(int x) {
return (x==fa[x]) ? x : (fa[x]=find(fa[x]));
}
int find(int x) {
while (x != fa[x]) {
fa[x] = fa[fa[x]];
x = fa[x];
}
return x;
}
int find(int x) {
int root = x;
while (root != fa[root]) root = fa[root];
while (x != fa[x]) {
fa[x] = root;
x = fa[x];
}
retur root;
}
合并:合并操作将p和q所在的集合,合并在一起,合并采用了按秩合并的启发式策略。
void unionSet(int p, int q) {
int fp = find(p);
int fq = find(q);
if (fp == fq) return;
if (rank[fp] < rank[fq]) fa[fp] = fq;
else {
fa[fq] = fp;
if (rank[fp] == rank[fq]) rank[fp]++;
}
}
集合关系:判断p和q是否在同一集合中
bool connected(int p, int q) {
return find(p) == find(q);
}
基本的带路径压缩的按秩合并的并查集结构就差不多是这样,并查集的复杂度分析比较复杂,当M个Union-find在N个对象上的操作,时间复杂度约为N+Mlg*N.
POJ 1182 食物链
经典的种类并查集,参考《挑战程序设计》上的思想,对于动物X我们分别使用X表示A种类,X+n表示B种类,X+2n表示C种类。
主要思考如何判断当前话与前面的话冲突。
对于输入1, x, y来说,这句话表明x, y是同类,那么如果x的A种类与y的B种类,或者x的A种类与y的C种类为一个集合,那么这句话就是假话。否则,我们就要把x与y的A种类合并,x与y的B种类合并,x与y的C种类合并。
if (connected(x, y+n) || connected(x, y+2*n)) {
ans++;
} else {
unionSet(x, y);
unionSet(x+n, y+n);
unionSet(x+2*n, y+2*n);
}
对于输入2, x, y来说,这句话表明x吃y,如果x的A种类与y的A种类为一个集合,那么同类集合不能捕食,这是假话。如果x的A种类与y的C种类为一个集合,表明y捕食x,这也是不正确的。其他情况下,就可以合并x的A种类与y的B种类,x的B种类与y的C种类,x的C种类与y的A种类。
if (connected(x, y) || connected(x, y+2*n)) {
ans++;
} else {
unionSet(x, y+n);
unionSet(x+n, y+2*n);
unionSet(x+2*n, y);
}
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_1182-cpp
BTW,坑爹的这道题是单Case。
POJ 2524 Ubiquitous Religions
初始每个元素为一个集合,将输入p和q集合合并,最后输出有多少个集合。使用一个component变量维护集合的数量,初始为N个,每当两个不在同一个集合的p和q进行合并时,component的数量就减去1,最后component存储的就是集合数。
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_2524-cpp
POJ 1611 The Suspects
题意是不断进行集合合并操作,最后输出0所在集合的大小。这里我们就可以使用前面提到的按照集合元素个数的启发式规则来进行合并,最后输出0所在集合最顶端元素的集合元素个数,就是所要求解的答案了。其他的方法我们也可以把所有集合合并完后,对除0以外的所有进行判断是否Find(0) == Find(other)成立,这样来统计0所在集合元素个数。
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_1611-cpp
POJ 1456 Supermarket
题目描述的是对于每个商品有p和d,分别代表商品的价值和它要卖出的截止时间。
那么我们可以有一个贪心的策略,将商品按照价值从大到小进行排序,如果价值相同按照时间从大到小进行排序,我们要获取的商品价值越大越好,截止时间越久我们选择的空间就越不会与其他时间发生冲突。使用一个d[]标记哪些截止时间被用掉了,如果被用掉,我们就去截止时间之前找未被使用的截止时间,如果没被用掉的,就直接使用。
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_1456v2-cpp
那么这题并查集又有什么关系?当我们发现某个截止时间被用掉了,我们for循环向前去枚举查找,没有被用掉的截止时间,这里并查集登场了。用并查集去替代for循环去查找,将被用过的当前点i与它的前一个点i-1进行合并,当我们要知道i之前未使用的截止时间时候,我们只要pos = find(i.time),就得到了它的位置,细节地方注意一下边界。
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_1456v1-cpp
POJ 1703 Find them, Catch them
和食物链类似的种类并查集,对于某人X,用X表示他所在的帮派,X+n表示他的敌对帮派。
对于操作 D, x, y,x和y属于不同帮派,那么x所在帮派和y的敌对帮派是同盟,union(x, y+n),x的敌对帮派与y的帮派是同盟,union(x+n, y)。敌人的敌人是朋友
对于操作 A, x, y, 判断x 和 y是否是同一帮派,如果find(x) == find(y),那么就是同一帮派了。如果find(x) == find(y+n), 那么就是敌对帮派了。其他就是未知。
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_1703-cpp
POJ 1988 Cube Stacking
这个题目描述是有N个栈,初始每个栈里面是1-N个方块,定义两个操作,第一个操作是M X Y,将X所在的栈移动到Y所在的栈的上面,另一个操作是C X,当前X下面有多少个方块。
采用并查集实现,对于M X Y操作, X所在栈放在Y所在栈上面,我们要合并X,Y所在集合,把Y所在的集合指向X所在的集合。但是对于C X操作进行查询的时候,我们如何得到X下面有多少个方块?如果我们记录了当前点并查集最顶根的距离,如果我们又知道了当前这个并查集元素个数,size为多大,那么二者之差减1就可以得到C X操作的结果了。
那么点到的根的距离如何维护,我们用数组up[],up[x]表示x到他所在并查集树根的距离,初始时候每个自身为树根,那么up[] = 0,在进行合并时候,我们相当于在X集合上附加了一个集合Y,那么初始X集合的root到自身距离为0,现在root指向了Y的root,就被修正成了Y所在集合大小也就是sz[fy],然后还要更新Y所在集合的大小sz[fy] += sz[fx]
void union_set(int p, int q) {
//把p所在的栈放在q所在栈上面
int fp = find(p);
int fq = find(q);
if (fp == fq) return;
fa[fq] = fp;//fq指向fp
up[fq] += sz[fp];//更新q的root节点到新的p的根节点的距离
sz[fp] += sz[fq];//更新p的root的节点个数
}
这里我们只是修改了X的root的up的值但是对于X的root下面的节点元素,up的值都还没有更新,这一步的更新是在find操作中,在进行压缩路径的同时,进行当前点到root距离的更新。
int find(int x) {
int tmp = fa[x];
if (x == fa[x]) return x;
fa[x] = find(fa[x]);
up[x] += up[tmp];//求解当前点到root的距离,up[x] += up[未压缩之前的fa[x]]
return fa[x];
}
附图:
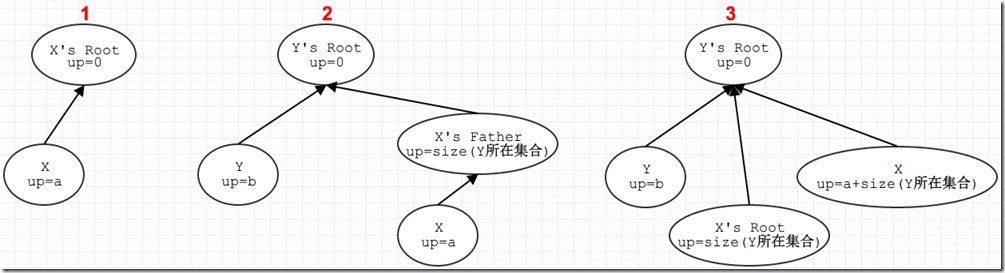
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_1988-cpp
POJ 1038 Is It A Tree?
题意很简答,给很多的边,最后判断能否构成一棵树,对于题目来说,树是不存在环,并且仅能只有一棵。
简单的并查集操作在加边时候判断,两个点是否已经在一个集合了。然后判断一下是否所有点都在一个集合,不能构成森林。
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_1038-cpp
POJ 2492 A Bugs Life
这一题的解题思路与POJ1703类似,每只虫子分为公母两类,如果某一类夹杂了公母,那么就是有问题的。
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_2492-cpp
POJ 2236 Wireless Network
裸的并查集。需要预先处理一下d^2之内的computer邻接表,然后再做并查集操作时候,将已经open的computer也一起加进来。
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_2236-cpp
POJ 1962 Coporative Network
这一题的思路做法和POJ1988一样。这里就不赘述了,
完整代码:https://gist.github.com/Lee656/edc34d790461afae190e#file-poj_1962-cpp
并查集 Union-Find的更多相关文章
- 并查集(Union/Find)模板及详解
概念: 并查集是一种非常精巧而实用的数据结构,它主要用于处理一些不相交集合的合并问题.一些常见的用途有求连通子图.求最小生成树的Kruskal 算法和求最近公共祖先等. 操作: 并查集的基本操作有两个 ...
- POJ 1611 The Suspects 并查集 Union Find
本题也是个标准的并查集题解. 操作完并查集之后,就是要找和0节点在同一个集合的元素有多少. 注意这个操作,须要先找到0的父母节点.然后查找有多少个节点的额父母节点和0的父母节点同样. 这个时候须要对每 ...
- Java 并查集Union Find
对于一组数据,主要支持两种动作: union isConnected public interface UF { int getSize(); boolean isConnected(int p,in ...
- 最小生成树(Minimum Spanning Tree)——Prim算法与Kruskal算法+并查集
最小生成树——Minimum Spanning Tree,是图论中比较重要的模型,通常用于解决实际生活中的路径代价最小一类的问题.我们首先用通俗的语言解释它的定义: 对于有n个节点的有权无向连通图,寻 ...
- bzoj1854 [Scoi2010]游戏【构图 并查集】
传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=1854 没想到怎么做真是不应该,看到每个武器都有两个属性,应该要想到连边构图的!太不应该了! ...
- [leetcode] 并查集(Ⅰ)
预备知识 并查集 (Union Set) 一种常见的应用是计算一个图中连通分量的个数.比如: a e / \ | b c f | | d g 上图的连通分量的个数为 2 . 并查集的主要思想是在每个连 ...
- 并查集(Union Find)的基本实现
概念 并查集是一种树形的数据结构,用来处理一些不交集的合并及查询问题.主要有两个操作: find:确定元素属于哪一个子集. union:将两个子集合并成同一个集合. 所以并查集能够解决网络中节点的连通 ...
- 并查集 (Union Find ) P - The Suspects
Severe acute respiratory syndrome (SARS), an atypical pneumonia of unknown aetiology, was recognized ...
- 并查集(Disjoint Set Union,DSU)
定义: 并查集是一种用来管理元素分组情况的数据结构. 作用: 查询元素a和元素b是否属于同一组 合并元素a和元素b所在的组 优化方法: 1.路径压缩 2.添加高度属性 拓展延伸: 分组并查集 带权并查 ...
- 第三十一篇 玩转数据结构——并查集(Union Find)
1.. 并查集的应用场景 查看"网络"中节点的连接状态,这里的网络是广义上的网络 数学中的集合类的实现 2.. 并查集所支持的操作 对于一组数据,并查集主要支持两种操作:合并两 ...
随机推荐
- android WebView问题
1.加载本地js.css文件 今天碰到个问题,使用WebView加载html数据,本来没什么问题,loadUrl(),loadData(),都可以使用 但是如果需要引入本地的js.css文件就碰到问题 ...
- C++ 创建和遍历二叉树
一个简单的创建和遍历二叉树的C++程序,二叉树的其他操作程序待更新. #include <iostream> using namespace std; struct BiTNode{ ch ...
- linux mono环境
安装好 CentOS 6.5 之后 1.更新系统 在命令行下执行 yum –y update 2.安装必要的软件 yum -y install gcc gcc-c++ bison pkgconfig ...
- 计算hashCode的常见方法
把某个非零常数值,比如说17,保存在一个叫result的int类型的变量中. 2.对于对象中每一个关键域f(值equals方法中考虑的每一个域),完成以下步骤: a.为该域计算int类型的散列吗c: ...
- CSS子元素居中(父元素宽高已知,子元素未知)
<style> .container{width:400px; height:400px; position:relative;} .center{position:absolute; l ...
- Java内各种进制的表示
不同进制的数据表现: 二进制:由0,1组成.以0b开头. 八进制:由0,1,...7组成.以0开头. 十进制:由0,1,...9组成.默认整数是十进制. 十六进制:由0,1,...9,a,b,c,d, ...
- Maven实战(五)坐标详解
1.为什么要定义Maven坐标 在我们开发Maven项目的时候,需要为其定义适当的坐标,这是Maven强制要求的.在这个基础上,其他Maven项目才能应用该项目生成的构件. 2.Maven坐 ...
- 转:RealThinClient LinkedObjects Demo解析
这个Demo源码实现比较怪,有点拗脑,原因估是作者想把控件的使用做得简单,而封装太多. 这里说是解析,其实是粗析,俺没有耐心每个实现点都查实清楚,看源码一般也就连读带猜的. 这个Demo表达出的意义, ...
- Django模板格式
变量 {{ 变量名称 }} 块 {% block 块名称 %} 判断 根据布尔值判断: {% if 布尔值 %} 操作 {% endif %} 根据两者是否相等判断: {% ifequals 变量1 ...
- 利用Delphi的File Of Type创建并管理属于你自己的数据库
http://www.360doc.com/content/16/1128/19/28222077_610249962.shtml 利用Delphi的File Of Type创建并管理属于你自己的数据 ...