基于superagent 与 cheerio 的node简单爬虫
最近重新玩起了node,便总结下基本的东西,在本文中通过node的superagent与cheerio来抓取分析网页的数据。
目的
superagent 抓取网页
cheerio 分析网页
准备
Node(我的6.0)
三个依赖, express(4X),superagent 和 cheerio。
文档参考
superagent(http://visionmedia.github.io/superagent/ ) 是个 http 方面的库,可以发起 get 或 post 请求。
cheerio(https://github.com/cheeriojs/cheerio )为服务器特别定制的,快速、灵活、实施的jQuery. 用来从网页中以 css selector 取数据,使用方式跟 jquery 一样。
代码
那么我将抓取自己博客的数据。(有兴趣的朋友可以锦上添花一下,用正则筛选阅读数不少于400的文章.)
var express = require('express');
var superagent = require('superagent');
var cheerio = require('cheerio');
var app = express();
app.get('/', function (req, res, next) {
superagent.get('http://www.cnblogs.com/LIUYANZUO')
.end(function (err, sres) {
if (err) {
return next(err);
}
// sres.text 里面存储着网页的 html 内容,将它传给 cheerio.load 之后
// 就可以得到一个实现了 jquery 接口的变量,我们习惯性地将它命名为 `$`
// 剩下就都是 jquery 的内容了
var $ = cheerio.load(sres.text);
var items = [];
$('.day .postTitle2').each(function (index, element) {
var $element = $(element);
items.push({
标题: $element.text(),
网址: $element.attr('href')
});
});
res.send(items);
});
});
app.listen(4000, function () {
console.log('app is listenling at port 4000');
});
在命令行运行,得到截图
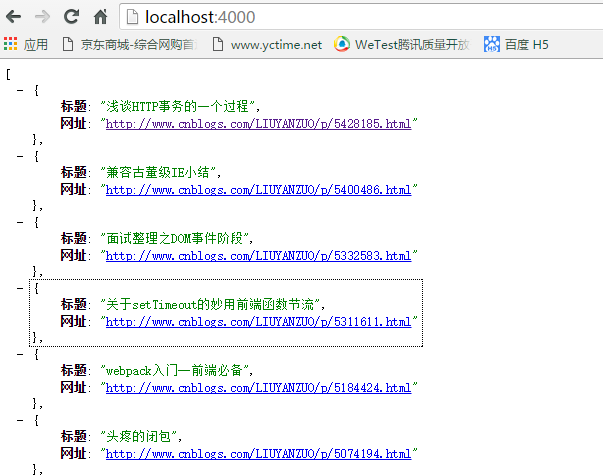
当然这是最简单的,下一篇我想介绍下node的异步并发。
基于superagent 与 cheerio 的node简单爬虫的更多相关文章
- 手把手教你学node.js之使用 superagent 与 cheerio 完成简单爬虫
使用 superagent 与 cheerio 完成简单爬虫 目标 建立一个 lesson 3 项目,在其中编写代码. 当在浏览器中访问 http://localhost:3000/ 时,输出 CNo ...
- nodejs爬虫初试---superagent和cheerio
前言 早就听过爬虫,这几天开始学习nodejs,写了个爬虫 demo ,爬取 博客园首页的文章标题.用户名.阅读数.推荐数和用户头像,现做个小总结. 使用到这几个点: 1.node的核心模块-- 文件 ...
- node的简单爬虫
最近在学node,这里简单记录一下. 首先是在linux的环境下,关于node的安装教程: https://github.com/alsotang/node-lessons/tree/master ...
- node 简单的爬虫
基于express爬虫, 1,node做爬虫的优势 首先说一下node做爬虫的优势 第一个就是他的驱动语言是JavaScript.JavaScript在nodejs诞生之前是运行在浏览器上的脚本语言, ...
- <node.js爬虫>制作教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友. 目标:爬取 http://tweixin.yueyishu ...
- 【原】小玩node+express爬虫-2
上周写了一个node+experss的爬虫小入门.今天继续来学习一下,写一个爬虫2.0版本. 这次我们不再爬博客园了,咋玩点新的,爬爬电影天堂.因为每个周末都会在电影天堂下载一部电影来看看. talk ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
随机推荐
- 一个简单例子:贫血模型or领域模型
转:一个简单例子:贫血模型or领域模型 贫血模型 我们首先用贫血模型来实现.所谓贫血模型就是模型对象之间存在完整的关联(可能存在多余的关联),但是对象除了get和set方外外几乎就没有其它的方法,整个 ...
- ABK (枚举)
ABK Accepted : 24 Submit : 176 Time Limit : 1000 MS Memory Limit : 65536 KB 题目描述 ABK是一个比A+B还要简单 ...
- undefined与null的区别
最近在默默的看面试题,其中有一个题目就是“undefined和null的区别”,突然意识到自己从未关注过这个问题,心中莫名有种急躁的感觉,百度一下发现阮大神的一篇文章(http://www.ruany ...
- Android之项目推荐使用的第三方库,有助于快速开发,欢迎各位网友补充
1. 使用上拉更多,下拉刷新:https://github.com/JosephPeng/XListView-Android这个是github上面更为火爆的:https://github.com/ch ...
- Leetcode 之Convert Sorted Array to Binary Search Tree(54)
思路很简单,用二分法,每次选中间的点作为根结点,用左.右结点递归. TreeNode* sortedArrayToBST(vector<int> &num) { return so ...
- 粒子滤波particle filter和目标跟踪
粒子滤波用于跟踪,参考:http://www.cnblogs.com/tornadomeet/archive/2012/03/18/2404817.html http://blog.csdn.net/ ...
- RPM常用组合【转载】
RPM常用组合 -ivh:安装显示安装进度--install--verbose--hash -Uvh:升级软件包--Update: -qpl:列出RPM软件包内的文件信息[Query Package ...
- 查看daemon使用技巧
una ~ # ps -ef|egrep "*d$"或"[a-z]d" //查看现有的服务器上都有哪些服务器进程.root 3509 ...
- mysql sql维护常用命令
mysql修改表名,列名,列类型,添加表列,删除表列 alter table test rename test1; --修改表名 alter table test add column name v ...
- Search Range in Binary Search Tree
Given two values k1 and k2 (where k1 < k2) and a root pointer to a Binary Search Tree. Find all t ...