C++ Data Member内存布局
如果一个类只定义了类名,没定义任何方法和字段,如class A{};那么class A的每个实例占用1个字节的内存,编译器会会在这个其实例中安插一个char,以保证每个A实例在内存中有唯一的地址,如A a,b;&a!=&b。如果一个直接或是间接的继承(不是虚继承)了多个类,如果这个类及其父类像A一样没有方法没有字段,那么这个类的每个实例的大小都是1字节,如果有虚继承,那就不是1字节了,每虚继承一个类,这个类的实例就会多一个指向被虚继承父类的指针。还有一点值得说明的就是像A这样的类,编译器不一定会产生传说中的那6个方法,这些方法只会在需要的时候产生,如class A没有被任何地方使用那这些方法编译器就没有必要产生,如果这个类实例化了,那么会产生default constructor,而destructor则不一定产生。
如果一个类中有static data member,nonstatic data member,还有const data member,enum,那么它的内存布局会是什么样的呢,看下面简单的类Point:
class Point
{
public:
Point():maxCount(){}
private:
int X;
static int count;
int Y;
const int maxCount ;
enum{
minCount=
};
};
Sizeof(Point)=12,为什么占12字节呢,我相信很多人都知道是哪几个成员变量占用的,就是X,Y,maxCount,maxCount作为常量字段,但在Point的每个实例中可能有不同的值,当然属于Point实例的一部分,如果把maxCount定义成static,那它就不不是Point实例的一部分了,如果定义成static const int maxCount=1;则maxCount分配在.data段中,如果没有初始化则分配在.bss段中,反正跟Point的实例无关,count分配在.bss段中,minCount分配在.rdata段中,总之count,maxCount,minCount在编译连接完成之后,内存(虚拟地址)就分配好了,在程序加载的时候,会把他们的虚拟地址对应上实际的物理地址。
Data member的内存布局:nonstatic data member在class object中的顺序和其申明的顺序一样,static data member和const member不在class object中因为他们只有一份,被class object共享,所以static data member和const data member,枚举并不会响应class object的大小。关于段的信息,我觉得是每个C/C++程序员必须知道的。而Point每次实例化的时候则只需要分配X,Y,maxCount需要的内存。
每个类的data member在内存中应该是连续的,如果出现数据对齐的情况,可能中间会有空白地带。请看下面几个类:
class AA
{
protected:
int X;
char a;
}; class BB:public AA
{
protected:
char b;
}; class CC:public BB
{
protected:
char c;
};
Sizeof(AA)=8//对齐3字节
Sizeof(BB)=12//两个3字节对齐
Sizeof(CC)=16//编译器“无耻”的用了3个3字节对齐
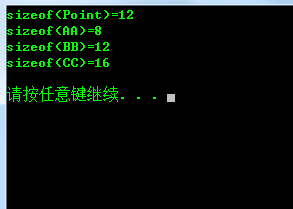
关于内存对齐问题我相信大家经常遇到,我就不废话,我之前写过一篇关于内存对齐的文章《数据对齐》
编译器为什么要无耻的在class CC中加3个3字节对齐呢,这样每个CC的实例就大了9字节。如果编译器不加这9字节的空白,那么CC的每个实例就是8字节,前面的X占4字节,后面的a,b,c占3字节,加1字节的空白对齐,刚好8字节,没有谁很傻很天真的以为最好是占7字节吧。
如果CC占用8字节内存,同样的AA,BB都是8字节的内存,这样的话,如果把一个指向AA实例的指针赋给一个指向CC实例的指针,那么就会把AA中的8字节直接盖到CC的8字节上,结果CC实例中的b,c都被赋上了不是我们想要的值,这很可能会导致你的程序出问题。
父类的data member会在子类的实例中有完整的一份,这样在有继承关系的类之间进行类型转换,就只用简单的修改指针的指向。
Data Member的存取。对一个data member的存取,编译器把对象实例的起始地址加上data member的偏移量。如CC c;
c.X=1;相当于&c+(&CC::X-1),减一其实是为了区分是指向object的指针还是指向data member的指针,指向data member的要减一。每一个data member的偏移量在编译的时候是知道的,根据成员变量的类型和内存对齐,存在virtual继承或是虚方法的情况编译器会自动加上一些辅助的指针,如指向虚方法的指针,指向虚继承父类的指针等。
在data member的存取效率上,struct member 、class member、单一继承或是多重继承的情况下效率都是一样的,因为他们的存储其实都是&obj+(&class.datamember-1)。在虚继承的情况下,可能会影响存储性能,如通过一个指针来存取一个指向虚继承而来的data member,那么性能会有影响,因为在虚继承的时候,在编译的时候还不能确定这个data member是来自子类还是父类,只有在运行的时候才能推断出来,其实就是多了一步指针的操作,在虚继承中,如果是通过对象实例来操作虚继承而来的data member,则不会有任何性能问题,因为不存在什么多态性,所有东西在编译的时候内存地址都确定了。
虚继承还是虚方法为了实现多态一样,多了一步,如果不需要多态,而是通过对象实例调用相关的方法就不会有性能问题。
C++ Data Member内存布局的更多相关文章
- 图说C++对象模型:对象内存布局详解
0.前言 文章较长,而且内容相对来说比较枯燥,希望对C++对象的内存布局.虚表指针.虚基类指针等有深入了解的朋友可以慢慢看. 本文的结论都在VS2013上得到验证.不同的编译器在内存布局的细节上可能有 ...
- c++ 对象内存布局详解
今天看了的,感觉需要了解对象内存的问题.参考:http://blog.jobbole.com/101583/ 1.何为C++对象模型? 引用<深度探索C++对象模型>这本书中的话: 有两个 ...
- Linux Debugging(四): 使用GDB来理解C++ 对象的内存布局(多重继承,虚继承)
前一段时间再次拜读<Inside the C++ Object Model> 深入探索C++对象模型,有了进一步的理解,因此我也写了四篇博文算是读书笔记: Program Transfor ...
- 好文章系列C/C++——图说C++对象模型:对象内存布局详解
注:收藏好文章,得出自己的笔记,以查漏补缺! ------>原文链接:http://blog.jobbole.com/101583/ 前言 本文可加深对C++对象的内存布局.虚表指针.虚 ...
- 【转载】图说C++对象模型:对象内存布局详解
原文: 图说C++对象模型:对象内存布局详解 正文 回到顶部 0.前言 文章较长,而且内容相对来说比较枯燥,希望对C++对象的内存布局.虚表指针.虚基类指针等有深入了解的朋友可以慢慢看.本文的结论都在 ...
- c++对象模型和对象内存布局
简单对象模型:如下图所示: 每一个object是一系列的slots,每一个data member或者function member都有自己的一个slot.这种模型的空间和执行效率都很低.在这个模型中, ...
- C++ 系列:内存布局
转载自http://www.cnblogs.com/skynet/archive/2011/03/07/1975479.html 为什么需要知道C/C++的内存布局和在哪可以可以找到想要的数据?知道内 ...
- 根据内存布局定位的一个fastdfs坑
在使用fastdfs时,编写数据上传代码时,遇到一个坑.最终根据指针对应的内存布局定位到一个其client API的一个坑,值得记录一下.具体是在 tracker_connect_server() 这 ...
- Linux 内存布局
本文主要简介在X86体系结构下和在ARM体系结构下,Linux内存布局的概况,力求简单明了,不过多深入概念,多以图示的方式来记忆理解,一图胜万言. Technorati 标签: 内存 布局 ...
随机推荐
- MySQL报错“1366 - Incorrect integer value: '' XXXXXXX' at row 1 ”
出现这个错误是因为我在表中插入了一条含有中文字符的语句: 修改方法:(两种) 1:命令行 set names gbk:(此为设置通信编码) 2:my.ini中查找sql-mode 将 sql-mod ...
- “ExternalException (0x80004005): GDI+ 中发生一般性错误”的问题 .
原因一般是写入文件时,.net没有该目录的写入权限. 解决方案:增加iis(对aspx而言)对该目录的写入权限.
- 斯坦福第十六课:推荐系统(Recommender Systems)
16.1 问题形式化 16.2 基于内容的推荐系统 16.3 协同过滤 16.4 协同过滤算法 16.5 矢量化:低秩矩阵分解 16.6 推行工作上的细节:均值归一化 16.1 问题形式 ...
- 2014 New Year’s First Blog
新年开篇博客,依旧是流水账. 读到一篇强文,<关于两个世界体系的对话>.common practice 往往是针对某种语言或者特定技术为背景,然而,很多时候,common practice ...
- 使用PPT绘制96孔板
什么?96孔板就是Ctrl+C然后再Ctrl+V? 那你用PPT给我画一个384孔板吧……(学生物的应该都知道这货吧?示意图不少用吧?) 还不够麻烦?那就试试基因芯片吧…… 疯掉了有木有? 那么,看看 ...
- 配置iDempiere源码开发环境
你需要一个较为快速通畅的互联网连接来下载源代码! 安装软件: OS: Windows Server 2008 R2 SP1 x64 英文版 Database: Oracle 11G R2 x64 英文 ...
- redis和ssdb读取性能对比
最近关注了一下ssdb,它的特点是基于文件存储系统所以它支撑量大的数据而不因为内存的限制受取约束.从官网的测试报告来看其性能也非常出色和redis相当,因此可以使用它来代替redis来进行k-v数据业 ...
- Dynamic CRM 2013学习笔记(九)CrmFetchKit.js介绍:Fetchxml、多表联合查询, 批量更新
CrmFetchKit.js是一个跨浏览器的一个类库,允许通过JavaScript来执行fetch xml的查询,还可以实现批量更新,分页查询等.目前已支持Chrome 25, Firefox 19 ...
- 说说ABP项目中的AutoMapper,Castle Windsor(痛并快乐着)
这篇博客要说的东西跟ABP,AutoMapper和Castle Windsor都有关系,而且也是我在项目中遇到的问题,最终解决了,现在的感受就是“痛并快乐着”. 首先,这篇博客不是讲什么新的知识点,而 ...
- 冲刺阶段 day5
day5 项目进展 今天我们组的成员聚在一起进行了讨论,首先我们继续编写了学生管理这部分的代码,然后负责数据库的同学完成了数据库的部分,最后进行了学生管理这部分的代码复审 存在问题 因为代码不是一天之 ...