Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍
xgboost的可以参考:https://xgboost.readthedocs.io/en/latest/gpu/index.html
整体看加速5-6倍的样子。
Gradient Boosting, Decision Trees and XGBoost with CUDA
 Gradient boosting is a powerful machine learning algorithm used to achieve state-of-the-art accuracy on a variety of tasks such as regression, classification and ranking. It has achieved notice in machine learning competitions in recent years by “winning practically every competition in the structured data category”. If you don’t use deep neural networks for your problem, there is a good chance you use gradient boosting.
Gradient boosting is a powerful machine learning algorithm used to achieve state-of-the-art accuracy on a variety of tasks such as regression, classification and ranking. It has achieved notice in machine learning competitions in recent years by “winning practically every competition in the structured data category”. If you don’t use deep neural networks for your problem, there is a good chance you use gradient boosting.
In this post I look at the popular gradient boosting algorithm XGBoost and show how to apply CUDA and parallel algorithms to greatly decrease training times in decision tree algorithms. I originally described this approach in my MSc thesis and it has since evolved to become a core part of the open source XGBoost library as well as a part of the H2O GPU Edition by H2O.ai.
H2O GPU Edition is a collection of GPU-accelerated machine learning algorithms including gradient boosting, generalized linear modeling and unsupervised methods like clustering and dimensionality reduction. H2O.ai is also a founding member of the GPU Open Analytics Initiative, which aims to create common data frameworks that enable developers and statistical researchers to accelerate data science on GPUs.
Gradient Boosting
The term “gradient boosting” comes from the idea of “boosting” or improving a single weak model by combining it with a number of other weak models in order to generate a collectively strong model. Gradient boosting is an extension of boosting where the process of additively generating weak models is formalised as a gradient descent algorithm over an objective function.
Gradient boosting is a supervised learning algorithm. This means that it takes a set of labelled training instances as input and builds a model that aims to correctly predict the label of each training example based on other non-label information that we know about the example (known as features of the instance). The purpose of this is to build an accurate model that can automatically label future data with unknown labels.
| Instance | Age | Has job | Owns house | Income ($1000) |
|---|---|---|---|---|
| 0 | 12 | N | N | 0 |
| 1 | 32 | Y | Y | 90 |
| 2 | 25 | Y | Y | 50 |
| 3 | 48 | N | N | 25 |
| 4 | 67 | N | Y | 35 |
| 5 | 18 | Y | N | 10 |
Table 1 shows a toy dataset with four columns: ”age”, “has job”, “owns house” and “income”. In this example I will use income as the label (sometimes known as the target variable for prediction) and use the other features to try to predict income.
To do this, first I need to come up with a model, for which I will use a simple decision tree. Many different types of models can be used for gradient boosting, but in practice decision trees are almost always used. I’ll skip over exactly how the tree is constructed. For now it is enough to know that it can be constructed in order to greedily minimise some loss function (for example squared error).
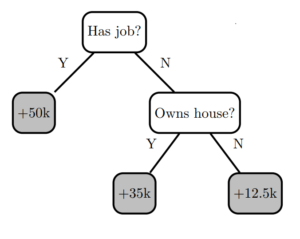 Figure 1. Decision tree 0.
Figure 1. Decision tree 0.
Figure 1 shows a simple decision tree model (I’ll call it “Decision Tree 0”) with two decision nodes and three leaves. A single training instance is inserted at the root node of the tree, following decision rules until a prediction is obtained at a leaf node.
This first decision tree works well for some instances but not so well for other instances. Subtracting the predicted label (



Table 2 shows the residuals for the dataset after passing its training instances through tree 0.
| Instance | Age | Has job | Owns house | Income ($1000) | Tree 0 Residuals |
|---|---|---|---|---|---|
| 0 | 12 | N | N | 0 | -12.5 |
| 1 | 32 | Y | Y | 90 | 40 |
| 2 | 25 | Y | Y | 50 | 0 |
| 3 | 48 | N | N | 25 | 12.5 |
| 4 | 67 | N | Y | 35 | 0 |
| 5 | 18 | Y | N | 10 | -40 |
 Figure 2. Decision tree 1.
Figure 2. Decision tree 1.
To improve the model, I can build another decision tree, but this time try to predict the residuals instead of the original labels. This can be thought of as building another model to correct for the error in the current model.
I add the new tree to the model, make new predictions and then calculate residuals again. In order to make predictions with multiple trees I simply pass the given instance through every tree and sum up the predictions from each tree.
| Instance | Age | Has job | Owns house | Income ($1000) | Tree 0 Residuals | Tree 1 Residuals |
|---|---|---|---|---|---|---|
| 0 | 12 | N | N | 0 | -12.5 | 5 |
| 1 | 32 | Y | Y | 90 | 40 | 22.5 |
| 2 | 25 | Y | Y | 50 | 0 | 17.5 |
| 3 | 48 | N | N | 25 | 12.5 | -5 |
| 4 | 67 | N | Y | 35 | 0 | -17.5 |
| 5 | 18 | Y | N | 10 | -40 | -22.5 |
Let’s take a look at the sum of squared errors for the extended model. SSE can be calculated as:

For the baseline model I just predict 0 for all instances.
| Model | SSE |
|---|---|
| No model (predict 0) | 6275 |
| Tree 0 | 1756 |
| Tree 0 + Tree 1 | 837 |
You can see that the error decreases as new models are added. To explain why fitting new models to the residuals of the current model increases the performance of the complete model, take the gradient of the SSE loss function for a single training instance:

So the residual
This minimises the loss function for the training instances until it eventually reaches a local minimum for the training data.
The XGBoost Algorithm
The above algorithm describes a basic gradient boosting solution, but a few modifications make it more flexible and robust for a variety of real world problems.
In particular, XGBoost uses second-order gradients of the loss function in addition to the first-order gradients, based on Taylor expansion of the loss function. You can take the Taylor expansion of a variety of different loss functions (such as logistic loss for binary classification) and plug them into the same algorithm for greater generalisation.
In addition to this, XGBoost transforms the loss function into a more sophisticated objective function containing regularisation terms. This extension of the loss function adds penalty terms for adding new decision tree leaves to the model with penalty proportional to the size of the leaf weights. This inhibits the growth of the model in order to prevent overfitting. Without these regularisation terms, gradient boosted models can quickly become large and overfit to noise present in the training data. Overfitting means that the model may look very good on the training set but generalises poorly to new data that it has not seen before.
You can find a more detailed mathematical explanation of the XGBoost algorithm in the documentation.
Quantiles
In order to explain how to formulate a GPU algorithm for gradient boosting, I will first compute quantiles for the input features (‘age’, ‘has job’, ‘owns house’). This process involves finding cut points that divide a feature into equal-sized groups. The boolean features ‘has job’ and ‘owns house’ are easily transformed by using 0 to represent false and 1 to represent true. The numerical feature ‘age’ transforms into four different groups.
| Age | Quantile | Count |
|---|---|---|
| <18 | 0 | 1 |
| <32 | 1 | 2 |
| <67 | 2 | 2 |
| 67+ | 3 | 1 |
The following table shows the training data with quantised features.
| Instance | Age | Has job | Owns house |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 2 | 1 | 1 |
| 2 | 1 | 1 | 1 |
| 3 | 2 | 0 | 0 |
| 4 | 3 | 0 | 1 |
| 5 | 1 | 1 | 0 |
It turns out that dealing with features as quantiles in a gradient boosting algorithm results in accuracy comparable to directly using the floating point values, while significantly simplifying the tree construction algorithm and allowing a more efficient implementation.
Finding Splits in Decision Trees
Here’s a brief explanation of how to find appropriate splits for a decision tree, assuming SSE is the loss function. As an example, I’ll try to find a decision split for the “age” feature at the start of the boosting process. After quantisation there are three different possible splits I could create for this feature: (age < 18), (age < 32) or (age < 67). I need a way to evaluate the quality of each of these splits with respect to the loss function in order to pick the best.
Given a node in a tree that currently contains a set of training instances 

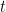
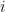

Rewritten in terms of the residuals and expanded this yields

I can simplify here by denoting the sum of residuals in the leaf 
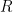

The above equation gives the training loss of a set of instances in a leaf. The next question is, what value should I predict in this leaf to minimise the loss function? The optimal leaf weight 

This gives

I can plug this back into the loss function for the current boosting iteration to see the effect of predicting

Simplifying, I get

This equation tells what the training loss will be for a given leaf 




The above equation gives the training loss for a given split in the tree, so I can simply apply this function to a number of possible splits under consideration and choose the one with the lowest training loss. I can recursively create new splits down the tree until I reach a specified depth or other stopping condition.
Note that the sum term 


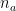
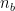

Implementation: Histograms and Prefix Sums
Bringing this back to my example of finding a split for the feature “age”, I’ll start by summing the residuals for each possible quantile value of age. Assume I’m at the start of the boosting process and therefore the residuals
The sums for each quantile can be calculated easily in CUDA using simple global memory atomic add operations or using the more sophisticated shared memory histogram algorithm discussed in thispost.
In order to apply the 
| Quantile | <18 | <32 | <67 | 67+ |
|---|---|---|---|---|
 |
1 | 2 | 2 | 1 |
Quantile sum  |
0 | 60 | 115 | 35 |
| Inclusive scan |
1 | 3 | 5 | 6 |
| Inclusive scan |
0 | 60 | 175 | 210 |
| Split loss | -4410 | -4350 | -3675 | – |
After applying the split loss function to the dataset, the split (<18) has the greatest reduction in the SSE loss function.
I would also perform this test over all other features and then choose the best out of all features to create a decision node in the tree. A GPU can do this in parallel for all nodes and all features at a given level of the tree, providing powerful scalability compared to CPU-based implementations.
Memory Efficiency: Bit Compression and Sparsity
Gradient boosting in XGBoost contains some unique features specific to its CUDA implementation. Memory efficiency is an important consideration in data science. Datasets may contain hundreds of millions of rows, thousands of features and a high level of sparsity. Given that device (GPU) memory capacity is typically smaller than host (CPU) memory, memory efficiency is important.
I have implemented parallel primitives for processing sparse CSR (Compressed Sparse Row) format input matrices following work in the modern GPU library and CUDA implementation of sparse matrix vector multiplication algorithms. These primitives allow me to process a sparse matrix in CSR format with one work unit (thread) per non-zero matrix element and efficiently look up the associated row index of the non-zero element using a form of vectorised binary search. This significantly reduces storage requirements, provides stable performance and still allows very clean and readable code.
Another innovation is the use of symbol compression to store the quantised input matrix on the device. The maximum integer value contained in a quantised nonzero matrix element is proportional to the number of quantiles, commonly 256, and to the number of features which are specified at runtime by the user. It seems wasteful to use a four-byte integer to store a value that very commonly has a maximum value less than 216. To solve this, the input matrix is bit compressed down to 
I can then define an iterator that accesses these compressed elements in a seamless way, resulting in minimal changes to existing CUDA kernels and function calls:
CompressedIterator<int> itr(compressed_buffer, max_value); template <typename iter_t>
__global__ void some_kernel(iter_t x) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int decompressed_value = x[tid];
}
It’s easy to implement this compressed iterator to be compatible with the Thrust library, allowing the use of parallel primitives such as scan:
thrust::device_vector<int> output(n);
thrust::exclusive_scan(itr, itr + n, output.begin());
Using this bit compression method in XGBoost reduces the memory cost of each matrix element to less than 16 bits in typical use cases. This is half the cost of the equivalent CPU implementation. Note that while it would be possible to use this iterator just as easily on the CPU, the instructions required to extract a symbol from the compressed stream can result in a noticeable performance penalty. The GPU kernels are typically memory bound (as opposed to compute bound) and therefore do not incur the same performance penalty from extracting symbols.
Performance on GPUs
I evaluate performance of the entire boosting algorithm using the commonly benchmarked UCI Higgs dataset. This is a binary classification problem with 11M rows * 29 features and is a relatively time consuming problem in the single machine setting.
The following Python script runs the XGBoost algorithm. It outputs the decreasing test error during boosting and measures the time taken by GPU and CPU algorithms.
import csv
import numpy as np
import os.path
import pandas
import time
import xgboost as xgb
import sys
if sys.version_info[0] >= 3:
from urllib.request import urlretrieve
else:
from urllib import urlretrieve data_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00280/HIGGS.csv.gz"
dmatrix_train_filename = "higgs_train.dmatrix"
dmatrix_test_filename = "higgs_test.dmatrix"
csv_filename = "HIGGS.csv.gz"
train_rows = 10500000
test_rows = 500000
num_round = 1000 plot = True # return xgboost dmatrix
def load_higgs():
if os.path.isfile(dmatrix_train_filename)
and os.path.isfile(dmatrix_test_filename):
dtrain = xgb.DMatrix(dmatrix_train_filename)
dtest = xgb.DMatrix(dmatrix_test_filename)
if dtrain.num_row() == train_rows and dtest.num_row() == test_rows:
print("Loading cached dmatrix...")
return dtrain, dtest if not os.path.isfile(csv_filename):
print("Downloading higgs file...")
urlretrieve(data_url, csv_filename) df_higgs_train = pandas.read_csv(csv_filename, dtype=np.float32,
nrows=train_rows, header=None)
dtrain = xgb.DMatrix(df_higgs_train.ix[:, 1:29], df_higgs_train[0])
dtrain.save_binary(dmatrix_train_filename)
df_higgs_test = pandas.read_csv(csv_filename, dtype=np.float32,
skiprows=train_rows, nrows=test_rows,
header=None)
dtest = xgb.DMatrix(df_higgs_test.ix[:, 1:29], df_higgs_test[0])
dtest.save_binary(dmatrix_test_filename) return dtrain, dtest dtrain, dtest = load_higgs()
param = {}
param['objective'] = 'binary:logitraw'
param['eval_metric'] = 'error'
param['tree_method'] = 'gpu_hist'
param['silent'] = 1 print("Training with GPU ...")
tmp = time.time()
gpu_res = {}
xgb.train(param, dtrain, num_round, evals=[(dtest, "test")],
evals_result=gpu_res)
gpu_time = time.time() - tmp
print("GPU Training Time: %s seconds" % (str(gpu_time))) print("Training with CPU ...")
param['tree_method'] = 'hist'
tmp = time.time()
cpu_res = {}
xgb.train(param, dtrain, num_round, evals=[(dtest, "test")],
evals_result=cpu_res)
cpu_time = time.time() - tmp
print("CPU Training Time: %s seconds" % (str(cpu_time))) if plot:
import matplotlib.pyplot as plt
min_error = min(min(gpu_res["test"][param['eval_metric']]),
min(cpu_res["test"][param['eval_metric']]))
gpu_iteration_time =
[x / (num_round * 1.0) * gpu_time for x in range(0, num_round)]
cpu_iteration_time =
[x / (num_round * 1.0) * cpu_time for x in range(0, num_round)]
plt.plot(gpu_iteration_time, gpu_res['test'][param['eval_metric']],
label='Tesla P100')
plt.plot(cpu_iteration_time, cpu_res['test'][param['eval_metric']],
label='2x Haswell E5-2698 v3 (32 cores)')
plt.legend()
plt.xlabel('Time (s)')
plt.ylabel('Test error')
plt.axhline(y=min_error, color='r', linestyle='dashed')
plt.margins(x=0)
plt.ylim((0.23,0.35))
plt.show()
Running this script on a system with an NVIDIA Tesla P100 accelerator and 2x Intel Xeon E5-2698 CPUs (32 cores total) shows a 4.15x speed improvement for the GPU algorithm with the same accuracy as the CPU algorithm. Figure 3 plots the decrease in test error over time for each algorithm. As you can see, the test error decreases much more rapidly with GPU acceleration.
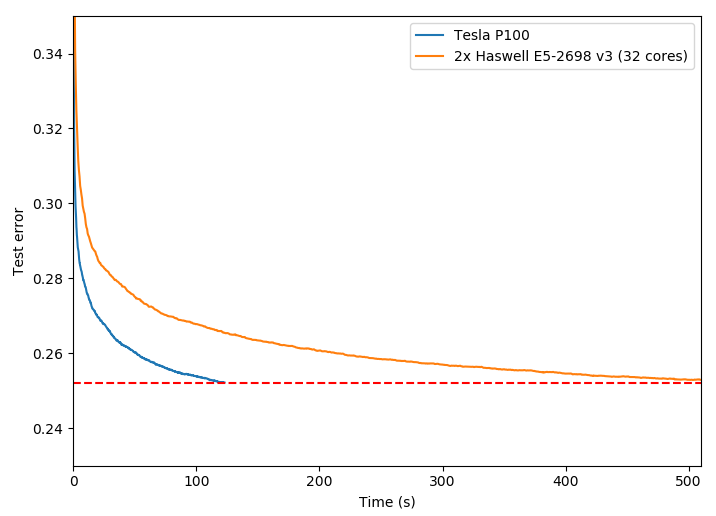 Figure 3. Test error over time for the Higgs dataset, 1000 boosting iterations.
Figure 3. Test error over time for the Higgs dataset, 1000 boosting iterations.
Using the GPU-accelerated boosting algorithm results in a significantly faster turnaround for data science problems. This is particularly important because data scientists typically run the algorithm not just once, but many times in order to tune hyperparameters (such as learning rate or tree depth) and find the best accuracy.
Future Work
Future work on the XGBoost GPU project will focus on bringing high performance gradient boosting algorithms to multi-GPU and multi-node systems to increase the tractability of large-scale real-world problems. Experimental multi-GPU support is already available at the time of writing but is a work in progress. Stay tuned!
Conclusion
Whether you are interested in winning Kaggle competitions, predicting customer interactions or ranking relevant web pages, you can achieve significant improvements in training and inference speed by using CUDA-accelerated gradient boosting.
Get started here with an easy python demo, including links to installation instructions.
Gradient Boosting, Decision Trees and XGBoost with CUDA ——GPU加速5-6倍的更多相关文章
- Parallel Gradient Boosting Decision Trees
本文转载自:链接 Highlights Three different methods for parallel gradient boosting decision trees. My algori ...
- Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)
https://www.quora.com/Why-do-people-use-gradient-boosted-decision-trees-to-do-feature-transform Why ...
- Gradient Boosting Decision Tree学习
Gradient Boosting Decision Tree,即梯度提升树,简称GBDT,也叫GBRT(Gradient Boosting Regression Tree),也称为Multiple ...
- GBDT(Gradient Boosting Decision Tree)算法&协同过滤算法
GBDT(Gradient Boosting Decision Tree)算法参考:http://blog.csdn.net/dark_scope/article/details/24863289 理 ...
- GBDT(Gradient Boosting Decision Tree) 没有实现仅仅有原理
阿弥陀佛.好久没写文章,实在是受不了了.特来填坑,近期实习了(ting)解(shuo)到(le)非常多工业界经常使用的算法.诸如GBDT,CRF,topic model的一些算 ...
- 论文笔记:LightGBM: A Highly Efficient Gradient Boosting Decision Tree
引言 GBDT已经有了比较成熟的应用,例如XGBoost和pGBRT,但是在特征维度很高数据量很大的时候依然不够快.一个主要的原因是,对于每个特征,他们都需要遍历每一条数据,对每一个可能的分割点去计算 ...
- 梯度提升树 Gradient Boosting Decision Tree
Adaboost + CART 用 CART 决策树来作为 Adaboost 的基础学习器 但是问题在于,需要把决策树改成能接收带权样本输入的版本.(need: weighted DTree(D, u ...
- 后端程序员之路 10、gbdt(Gradient Boosting Decision Tree)
1.GbdtModelGNode,含fea_idx.val.left.right.missing(指向left或right之一,本身不分配空间)load,从model文件加载模型,xgboost输出的 ...
- Gradient Boosting Decision Tree
GBDT中的树是回归树(不是分类树),GBDT用来做回归预测,调整后也可以用于分类.当采用平方误差损失函数时,每一棵回归树学习的是之前所有树的结论和残差,拟合得到一个当前的残差回归树,残差的意义如公式 ...
随机推荐
- 用pdf.js实现在移动端在线预览pdf文件
用pdf.js实现在移动端在线预览pdf文件1.下载pdf.js 官网地址:https://mozilla.github.io/pdf.js/ 2.配置 下载下来的文件包,就是一个demo ...
- 《CSS世界》读书笔记(十四)
<!-- <CSS世界>张鑫旭著 --> 功勋卓越的 border 属性 border-width 不支持百分比值 border-style 类型 border-style ...
- 【js】箭头函数与普通函数的异同
普通函数在es5中就有了,箭头函数是es6中出现的函数形式,当然也可以继续用es5写法. 普通函数大家知道: 形式基本一致 来看看箭头函数: 开发时根据实际情况可以省略一些东西 单条处理可以省略ret ...
- php,js 对字符串按位异或运算加密解密
异或的符号是^.按位异或运算, 对等长二进制模式按位或二进制数的每一位执行逻辑按位异或操作. 操作的结果是如果某位不同则该位为1, 否则该位为0. xor运算的逆运算是它本身,也就是说两次异或同一个数 ...
- 【Diary】
[写日记是好习惯] 前记 很随意的日记.想什么写什么,没有限制. 希望以后看到曾经,努力的自己比摸鱼的自己多. 2019.3 2019.3.29 第24次请假打卡 xzh:那些理科男以后都会当IT工作 ...
- Angular 中的数据交互(get jsonp post)
Angular get 请求数据 Angular5.x 以后 get.post 和和服务器交互使用的是 HttpClientModule 模块. import {HttpClientModule} f ...
- Centos7通过SSH使用密钥实现免密登录
日常开发中,难免会有登录服务器的操作,而通过ssh方式登录无疑是比较方便的一种方式. 如果登录较频繁,使用密钥实现免密登录无疑更是方便中的方便.因此本文就简单说一说如何实现免密登录. 一.安装配置ss ...
- CefSharp浏览器网页中文语言设置
设置浏览器语言而非cef语言 ChromiumWebBrowser browser = new ChromiumWebBrowser(url); BrowserSettings browserSett ...
- 将一,二维数组转化为Excel格式
首先,我们来看一下一维数组的, 其代码可以如下: import numpy as np import pandas as pd x = pd.Series([1, 3, 5, np.nan]) pri ...
- 如何使用postman传数组数据
如何使用postman传数组数据 在我们做api接口数据调试的时候,大部分是会用到postman的,一般请求数据的参数都是字符串,但是特殊情况下我们是需要传一个数组数据的,那么为了实现这种需求,究竟该 ...