Cross-Validation & Nested Cross-Validation
分享stackexchange的一篇问答:https://stats.stackexchange.com/questions/11602/training-with-the-full-dataset-after-cross-validation
Q: Is it always a good idea to train with the full dataset after cross-validation? Put it another way, is it ok to train with all the samples in my dataset and not being able to check if this particular fittingoverfits?
A: The way to think of cross-validation is as estimating the performance obtained using a method for building a model, rather than for estimating the performance of a model.
If you use cross-validation to estimate the hyperparameters of a model and then use those hyper-parameters to fit a model to the whole dataset, then that is fine, provided that you recognise that the cross-validation estimate of performance is likely to be (possibly substantially) optimistically biased. This is because part of the model (the hyper-parameters) have been selected to minimise the cross-validation performance, so if the cross-validation statistic has a non-zero variance (and it will) there is the possibility of over-fitting the model selection criterion.
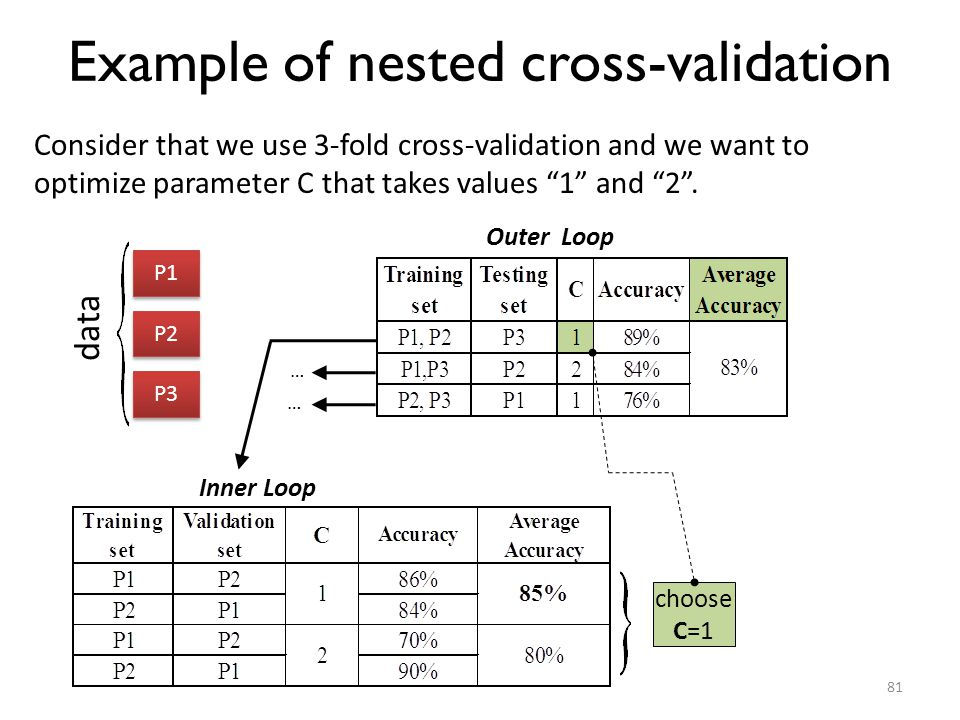
If you want to choose the hyper-parameters and estimate the performance of the resulting model then you need to perform a nested cross-validation, where the outer cross-validation is used to assess the performance of the model, and in each fold cross-validation is used to determine the hyper-parameters separately in each fold. You build the final model by using cross-validation on the whole set to choose the hyper-parameters and then build the classifier on the whole dataset using the optimized hyper-parameters.
This is of course computationally expensive, but worth it as the bias introduced by improper performance estimation can be large. See my paper
G. C. Cawley and N. L. C. Talbot, Over-fitting in model selection and subsequent selection bias in performance evaluation, Journal of Machine Learning Research, 2010. Research, vol. 11, pp. 2079-2107, July 2010. (www, pdf)
However, it is still possible to have over-fitting in model selection (nested cross-validation just allows you to test for it). A method I have found useful is to add a regularisation term to the cross-validation error that penalises hyper-parameter values likely to result in overly-complex models, see
G. C. Cawley and N. L. C. Talbot, Preventing over-fitting in model selection via Bayesian regularisation of the hyper-parameters, Journal of Machine Learning Research, volume 8, pages 841-861, April 2007. (www,pdf)
So the answers to your question are (i) yes, you should use the full dataset to produce your final model as the more data you use the more likely it is to generalise well but (ii) make sure you obtain an unbiased performance estimate via nested cross-validation and potentially consider penalising the cross-validation statistic to further avoid over-fitting in model selection.
交叉验证的目的可以理解为是为了估算建模方法的性能,而不是具体模型的性能。
如果使用交叉验证来选择超参数,那使用选取出的超参数在全部数据上拟合模型,这是对的。但是需要注意的是,使用这种交叉验证方法得出的性能估计是很有可能有偏差的。这是因为被选出模型的超参数是通过最小化交叉验证的性能而选出来的,这种情况下,交叉验证的性能用于衡量模型的泛化误差,不够准确。
如果既需要选择超参数,又需要估算选出模型的性能,可以选择Nested Cross-Validation。Nested Cross-Validation中的外层交叉验证用于估算模型性能,内层交叉验证用于选择超参数。最后,基于选出的超参数和全部数据集,产生最终的模型。
尽管这样,还是有可能在模型选择阶段存在过拟合(Nested Cross-Validation只是允许你可以对这种情况进行测试,如何测?)。一种解决方法是在cross-validation error中加入正则项,用于惩罚易产生过度复杂模型的超参数。
总结,(1)最终的模型应该使用全部数据集来建模,因为越多的数据,模型泛化能力越好;(2)需要确认性能估计得无偏的,Nested Cross-Validation和加惩罚项是解决性能估计出现偏差的方法。
Cross-Validation & Nested Cross-Validation的更多相关文章
- JSR303/JSR-349,hibernate validation,spring validation 之间的关系
JSR303是一项标准,JSR-349是其的升级版本,添加了一些新特性,他们规定一些校验规范即校验注解,如@Null,@NotNull,@Pattern,他们位于javax.validation.co ...
- CROSS APPLY AND CROSS APPLY
随着业务千奇百怪,DBA数据库设计各有不同,一对多关系存JSON或字符串逗号分隔... 今天小编给大家分享一下针对这个问题的解决办法 问题一.存储过程接受参数格式为XXX,XXX 解决办法:将字符转成 ...
- ssis error at other ssis.pipeline "ole db destination" failed validation and returned validation status
我在修改一个ssis的包,发现这个destination的表被改过了.所以就重建了表.就导致了这个错误. 打开包重新检查下表结构的匹配就好了
- Cross Validation done wrong
Cross Validation done wrong Cross validation is an essential tool in statistical learning 1 to estim ...
- [机器学习] 训练集(train set) 验证集(validation set) 测试集(test set)
在有监督(supervise)的机器学习中,数据集常被分成2~3个即: 训练集(train set) 验证集(validation set) 测试集(test set) 一般需要将样本分成独立的三部分 ...
- AI---训练集(train set) 验证集(validation set) 测试集(test set)
在有监督(supervise)的机器学习中,数据集常被分成2~3个即: 训练集(train set) 验证集(validation set) 测试集(test set) 一般需要将样本分成独立的三部分 ...
- Error creating bean with name 'org.springframework.validation.beanvalidation.LocalValidatorFactory
Error creating bean with name ‘org.springframework.validation.beanvalidation.LocalValidatorFactoryBe ...
- <转>SQL Server CROSS APPLY and OUTER APPLY
Problem SQL Server 2005 introduced the APPLY operator, which is like a join clause and it allows joi ...
- Caused by: java.lang.NoClassDefFoundError: javax/validation/ParameterNameProvider
问题现象:今天部署代码的时候发现,在beta环境可以正常部署,但是到了test环境就一直不成功,我以为是环境问题,就重新部署,但是没效,看了看日志发现问题是:Caused by: java.lang. ...
- MVC学习系列12---验证系列之Fluent Validation
前面两篇文章学习到了,服务端验证,和客户端的验证,但大家有没有发现,这两种验证各自都有弊端,服务器端的验证,验证的逻辑和代码的逻辑混合在一起了,如果代码量很大的话,以后维护扩展起来,就不是很方便.而客 ...
随机推荐
- java之过滤器
form.jsp <%@ page language="java" contentType="text/html; charset=UTF-8" page ...
- 20190411RAID磁盘阵列及CentOS7系统启动流程
RAID磁盘阵列及CentOS7系统启动流程(week2_day3) RAID概念 磁盘阵列(Redundant Arrays of Independent Disks,RAID),有“独立磁盘构 ...
- 随手记一 2018/04/23 Ajax基础了解
1.什么是ajax? 主要目的是用来实现客户端和服务器之间的异步通信,实现页面的局部刷新 2.同步和异步! 同步:当多个线程同时向一个数据发送请求时,必须是A先执行完毕才可以给B,会出现阻塞的情况,但 ...
- Java线程池ThreadPoolExecutor原理和用法
1.ThreadPoolExecutor构造方法 public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAli ...
- IDEA 创建 web项目
创建web步骤: 1.创建一个project File -> New Project -> 选择Java,Project SDK为1.7,勾选Web Application(创建web.x ...
- nodejs-使用multer实现多张图片上传,express搭建脚手架
nodejs-使用multer实现多张图片上传,express搭建脚手架 在工作中,我们经常会看到用户有多张图片上传,并且预览展示的需求.那么在具体实现中又该怎么做呢? 本实例需要nodejs基础,本 ...
- 王之泰201771010131《面向对象程序设计(java)》第十二周学习总结
第一部分:理论知识学习部分 第10章 图形程序设计 10.1 AWT与Swing简介 1.用户界面(User Interface) 的概念:用户与计算机系统(各种程序)交互的接口2.图形用户界面(Gr ...
- aop (权限控制之功能权限)
在实际web开发过程中通常会存在功能权限的控制,不如这个角色只允许拥有查询权限,这个角色拥有CRUD权限,当然按钮权限显示控制上可以用button.tld来控制,本文就不说明. 具体控制流程就是通过登 ...
- Pandas-数据的合并与拼接
Pandas包的merge.join.concat方法可以完成数据的合并和拼接,merge方法主要基于两个dataframe的共同列进行合并,join方法主要基于两个dataframe的索引进行合并, ...
- DAY 23 面向对象(二)
一.对象独有的名称空间 在产生对象时就赋初值 class Student: def __init__(self,name,sex): self.name = name self.sex = sex # ...