关于Java面试
Java基础知识复习
1. 简单讲一下Java跨平台的原理
由于操作系统(Windows、Linux)支持的指令集,不是完全一致的。就会让我们程序在不同的操作系统上执行不同的代码。Java开发了不同操作系统的虚拟机,只要遵循java开发规范,就可以在不同的操作系统上执行同一套代码2.Java中int数据占几个字节?(Java中有几种数据类型:8种)
java占用字节数
| 数据类型 | 大小(二进制位数) | 范围 | 默认值 |
|---|---|---|---|
| byte | 8 | -128~127 | 0 |
| short | 16 | -32768~32768 | 0 |
| int | 32 | -2147483648~2147483647 | 0 |
| long | 64 | -9223372036854775808 ~ 9223372036854775807 | 0 |
| float | 32 | -3.4E38~3.4E38 | 0.0f |
| double | 64 | 1.7E308~1.7E308 | 0.0d |
| char | 16 | 0~65535 | '\u0000' |
| boolean | 1 | true/false | false |
3.面向对象的特征有哪些方面? (回答抽象问题,举例说明)
有四大基本特征:封装、抽象、继承、多态
封装:即将对象封装成一个高度自治和相对封闭的个体,属性由这个对象自己的方法来读取和改变。张三这个人,姓名和年龄,要有自己提供的方法来读取和操作。 name:setName、getName
抽象:找出事务的相似和共性之处,将事务归为一个类。就是把现实生活中的对象抽象为类。
继承:在已经有了一个类的基础上来进行,把之前的类的内容作为自己的内容,并可以加入若干新的内容,或修改原来的方法以满足需求。如:遗产继承
多态:指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向那个类的实例对象,该引用变量发出的方法调用到底是那个类中的实现方法,必须由程序运行期间才能决定。 Object obj = new xxx()
UserDao userDao = new UserDaoJdbcImpl()
UserDao userDao = new UserDaoHibernateImpl() 实现:靠的是父类或接口定义的引用变量可以指向子类或具体实现类的实例对象,而程序调用的方法运行期间才动态绑定。就是引用变量具体指向的具体实现实例对象的方法,也就是内存里正运行的那个对象的方法,而不是引用变量的内型中定义的方法。4.有了基本数据类型,为什么还要包装类型?
基本数据类型:java提供了8种基本数据类型:byte、short、int、long、float、double、char、Boolean。每一个基础数据类型都会对应一个包装类型。如:Byte、Integer、Boolean
装箱&拆箱
装箱:把基本数据转换成包装类型 如: Integer i = 1;自动装箱,实际是调用integer的valueOf(int i)方法来装箱
拆箱:把包装类型转换为基本的数据类型。 Integer j = Integer.valueOf(1); int i = j ; 自动拆箱,调用integer.intValue()方法。
为什么还需要包装类型?java是一个面向对象的语言,基本数据类型不具备面向对象的特性。如:包装类型封装了像MAX_VALUE、MIN_VALUE 等方法。5.说一下“==”和equals方法究竟有什么区别?(经典的面试题,先说清楚一个,再说另外一个) 详细说明
6.讲一下 String 和 StringBuilder 的区别?StringBuffer 和 StringBuilder 的区别?
在java中提供了String 、StringBuffer 、StringBuilder 来表示和操作字符串。字符串就表示多个字符的集合。String 是内容不可变的字符串。String str = new String("aaa") 底层使用的是不可变的字符数组 final char value[]; 。而StringBuilder 和StringBuffer 是内容可以改变的字符串,底层使用的可变的字符数组,没有用final来修饰。所以,拼接字符要用StringBuffer 和StringBuilder ,不能用String 。
StringBuffer 和StringBuilder 的区别是:StringBuilder 是线程不完全的,效率较高。StringBuffer 是线程安全的,效率较低。 ps:线程安全,要加锁,加锁效率低。StringBuffer添加了synchronized线程同步锁。7.讲一下java中的集合
java中的集合分为:值、key—value (Collection 、Map)两种。
存储值得有:List 和 Set 。List 是有序的,可重复的。Set 是无序的,不可以重复的。是否重复根据equals 和 hashcode 判断,也就是一个对象要存储在Set 中必须重写equals 和 hashCode() 方法。
存储key-value的为Map8.ArrayList 和 LinkedList 的区别?
ArrayList 使用的是 Object[] elementData; 数组,LinkedList 使用的是 Node<E> first; 链表。
数组:查询有索引,查询快,插入、删除、修改比较慢(数组在内存中是一块连续的内存,如果删、插、改是需要移动内存,效率低)。 链表不要求内存是连续的,在当前元素中存放上一个 或下一个元素的地址。查询时,需要从头开始,一个一个的找。所以,查询效率低。插入时不需要移动内存,只需改变引用指向即可。所以删除、插入效率高。
ArrayList 使用在查询比较多,但是插入和删除比较少的情况。 而LinkedList 使用在查询比较少,而删除和插入比较多的情况。9.讲一下HashMap 和Hashtable 的区别?HashMap 和
相同点:HashMap 和Hashtable 都可以使用来存储key—value的数据。
区别:HashMap 是可以把null作为key或者value的,而Hashtable 是不可以的。HashMap 是线程不安全的,概率较高。而Hashtable 是线程安全的,效率较低。
想要线程安全,又想要效率高怎么办?
使用 ConcurrentHashMap ,通过把整个Map 分成N个 类似Hashtable ,可以保证线程安全,同事效率提升了N倍,默认提升16倍。10.实现一个拷贝文件的工具类,使用字节流还是字符流?
我们拷贝的文件不确定只包含字符流,有可能有字节流(图片、声音、图像),为了考虑到通用性,要使用字节流。11.线程的有几种实现方式,怎么启动,怎么驱动?线程池?线程并发库?
实现方式:
1.通过继承Thread类实现一个进程 Java只支持单继承,扩展性不强。
2.通过 实现 Runnable 接口
怎么启动:调用new Thread(new MyThread()).start(); MyThread继承thread或者实现 Runnable 接口。启动线程用 start() 方法,执行的是run() 方法。
怎么区分线程?假如在一个系统中有很多线程,每个线程都会打印日志,我想区分是哪个线程打印的日志,怎么办? 只需要在创建线程是设置线程名称 thread.setName("线程1"); 这也是一种规范,创建线程时都需要设置线程名称。12.有没有使用过线程并发库?
简单了解过。较重要,此处不详细记录13.讲一下什么是设计模式,常用的设计模式有哪些?
设计模式:就是经过无数次前人的实践总结出的,在设计过程中可以反复使用的,可以解决特定问题的设计方法。(可以套用的一种模板)
单例(饱汉模式、饥汉模式):
单例模式三部曲:1.构造方法私有化,让除了自己类中能创建外其他地方都不能创建。(饱汉模式是一出来就创建单实例,饥汉模式需要时才创建)
2.在自己类中创建一个单实例。(创建时需要方法同步)
3.提供一个静态方法获取该实例。
工厂模式:Spring IOC 就是使用了工厂模式。对象的创建交给一个工厂去创建。
代理模式:Spring AOP使用的就是代理模式。
包装模式://饱汉模式
public class PersonFactory {
//1.构造方法私有化
private PersonFactory() {
}
//2.创建实例
private static PersonFactory instance = new PersonFactory();
//3.提供一个静态方法获取该实例。
public static PersonFactory getInstance(){
return instance;
}
public static void main(String[] args) {
PersonFactory instance = PersonFactory.getInstance();
System.out.println("instance:"+instance);
}
}
//饥汉模式
public class PersonFactory {
//1.构造方法私有化
private PersonFactory() {
}
//2.创建实例 一开始并没有创建对象,需要时才创建。
private static PersonFactory instance = null ;
//3.提供一个静态方法获取该实例。 记得方法同步
public static synchronized PersonFactory getInstance(){
if(instance == null){
instance = new PersonFactory();
}
return instance;
}
public static void main(String[] args) {
PersonFactory instance = PersonFactory.getInstance();
System.out.println("instance:"+instance);
}
}13.讲一下http get 和 post请求的区别?
get 和 post 都是http的请求方式,用户通过不同的http的提交方式来完成对资源(url) 的操作 。具体来说,get一般用于获取/查询信息。post用于更新资源信息。
区别:
1.get 提交请求的数据会在地址栏显示,而post请求不会再地址栏显示出来。get 提交,请求数据会添加在url 的后面,以 ?分割url和数据,多个参数用& 连接。Post 提交,把数据放在 HTTP 包的包体中。因此,GET提交的数据会在地址栏显示,而POST提交,地址栏不会改变。
2.get 请求,由于浏览器对地址长度的限制而导致传输的数据有限,而 post请求不会因为地址长度限制而导致数据传输受限。
3.安全性:post 的安全性比 get的安全性更高。如果用get传了密码,可以通过历史记录找到密码。14.什么是 Servlet ?
Servlet(Server Applet), 是用Java编写的服务器端程序。而这些Servlet 都要实现Servlet接口。其主要功能在于交互式的浏览和修改数据,生成动态web内容。Servlet 仅支持运行在Java的应用服务器中。实际工作中,重写 HttpServlet 的doGet 和doPost方法,也可以重写 service 方法来满足对get和post请求的响应。15.说一下你对Servlet 的生命周期的理解?
Servlet 有良好的 生命存期的定义。包括加载和实例化,初始化,处理请求和服务结束。这个生命存期由javax.servlet.Servlet 接口的destroy()、init()、service() 方法来表达。
Servlet 启动时,开始加载 Servlet 生命周期,Servlet 被实例化后,容器运行期 init 方法,请求到达时 运行其service 方法,自动派遣与其对应的doxxx(dopost、doget)方法,当服务器决定将实例销毁时调用destroy() 方法。
加载 Servlet 的class —> 实例化Servlet —> 调用Servlet 的init 方法完成初始化 —> 响应请求(Servlet的service 方法)—> Servlet的容器关闭时(Servlet的destroy方法)16.Jsp 和 Servlet 有什么相同和不同点,他们之间的联系是什么?图解JSP与Servlet的关系.
相同:Jsp 是 Servlet 技术的扩展。所有的jsp文件都会被翻译为一个继承HttpServlet的类。也就是jsp最终也是一个servlet。这个servlet 对外提供服务。
不同:Servlet 的应用逻辑是在Java文件中,并且完全从表示层的HTML中分离出来。而jsp的情况是Java和HTML组合成一个扩展名为 .jsp 的文件。jsp 侧重视图,servlet 侧重逻辑。17.Jsp 有哪些内置对象,作用分别是什么,有哪些方法?
9个内置的对象:
request:用户端请求,此时会包含来自GET/POST的请求
response:网页传回用户端的回应。
pageContext:网页的属性是在这里管理的。
session:与请求有关的会话期。
application:servlet正在执行的内容。
out:用来传回应的输出。
config:servlet的架构部件。
page:网页本身。
exception:网页错误
四大作用域:request、pageContext、session、exception 可以通过 jstl 从四大作用域中取值。
jsp如何传值:request、session、application、cookie 也能传值。18.说一下session 和 cookie 的区别?你在项目中哪些地方使用了?
session和cookie 都是会话跟踪技术,cookie 是通过在客户端记录用户信息来确定用户身份,session 是通过在服务器端记录信息来确定用户身份信息。但是,session的实现依赖于cookie,sessionId(session 的唯一标识)需要存放在客户端。
session和cookie的区别:
1.session 数据存放在服务器上,cookie 数据存放在客户端的浏览器上。
2.cookie 不是很安全,别人可以分析放在本地的cookie并进行cookie的欺骗。考虑到安全应该使用session
3.session 会在一定时间内保存在服务器上,当访问增多,会占用服务器性能。考虑到减轻服务器的性能方面,应使用cookie。结论:session占内存,cookie不安全。把安全性比较高的存放在 session,安全性比较低的存放在cookie中。
4.单个cookie 保存的数据不能超过4k,很多浏览器限制一个站点最多保存20个cookie
5.个人建议:将登陆信息存放在session中,其他信息如果需要保留,存放在cookie中。 购物车最好用cookie,但是如果cookie在客户端被禁用,我们需要使用cookie+数据库的方式来实现,当从cookie中不能取出数据时,就从数据库获取。19.MVC的各部分都有哪些技术来实现?
MVC:m-model模型,v-view视图,c-controller控制器。
Model:javabean.。视图:Jsp、html 、freeMaker。控制器:Servlet 。 jsp + Servlet + JavaBean 最经典的mvc模型,实际就是model2的实现方式,就是把视图和逻辑隔离开来。20.数据库
数据库的分类:关系型数据库和非关系型数据库。关系型数据库:mysql 、oracle 、SqlServer 。菲关系型数据库:Redis 、 memcache 、mogodb 、hadop等
21.关系型数据库的三范式
什么是范式?范式就是规范。要想满足第二范式必须先满足第一范式。要满足第三范式必须先满足第二范式。
第一范式(1NF):数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。【列数据不可分割】
第二范式(2NF):要求数据库中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以满足各个实例的唯一标识。【主键】
第三范式(3NF):要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。【外键】
反三范式:有时候为了查询效率,可以设置重复的字段。如:订单(总价)和订单项(单价)22.事务的四个基本特征ACID特性。
事务是并发控制的单位,是用户定义的一个操作序列。这些操作要么都做要么都不做,是一个不可分割的工作单位。如:一个转账必须 A账号扣钱成功,B 账号加钱成功。
事务必须满足四大特征:原子性、隔离性、一致性、持久性/持续性。
原子性:表示事务内操作不可分割,要么都成功,要么都失败。
一致性:要么都成功,要么都失败。失败了要对前面的操作回滚。
隔离性:一个事务开始后,不能受其他事务干扰。
持久性/持续性:表示事务开始了就不能终止。23.MySQL 数据库的默认最大连接数?
为什么需要最大连接数:特定服务器上面的数据库只能支持一定数目同时连接,这是需要我们设置最大连接数(最多同时服务多少连接)。在数据库安装时都会有一个默认的最大连接数。MySQL 最大连接数可以 my.ini文件中查找 max_connects = 100 ,即默认最大连接数为100。23.说一下MySQL的分页和oracle的分页。
为什么需要分页:在很多数据时,不可能完全显示数据,要分段显示。
MySQL 分页:是使用关键字 limit 来分页的。limit off,size 表示从多少索引,取多少位。
oracle 分页:大部分情况我们是记不住的,说思路。要是用三层嵌套查询。oracle 的分页有点记不住,只记得一些大概。是使用了三层嵌套查询,如果在工作中使用了可以到原来的项目中去拷贝或百度查询。24.简单说一下触发器的使用场景
触发器:需要有触发条件,当条件满足以后做什么操作。比如:QQ 你发一条说说,自动通知你的好友。就是在增加说说时做一个触发器,再像通知中写入条目。因为触发器效率高,而xxx公司没有用触发器则效率和数据处理能力都比较低。create table board1(id int primary key auto_increment,name varchar(50),ar
ticleCount int);
create table article1(id int primary key auto_increment,title varchar(50)
,bid int references board1(id));
delimiter |#把分割符;改成|
create trigger insertArticle_Trigger after insert on article1 for each ro
w begin
-> update board1 set articleCount=articleCount+1 where id= NEW.bid;
-> end;
-> |
delimiter ;
insert into board1 value (null,'test',0);
insert into article1 value(null,'test',1);
25.简单讲一下数据库存储过程的使用场景?
存储过程的优点:
1.存储过程只在创建时进行编译,以后每次执行存储过程都不需要重新编译,而一般SQL语句执行一次就编译一次,因此存储过程可以大大提高数据库执行速度。
2.通常,复杂业务逻辑需要多条SQL语句,这些语句要分别从客户机发送到服务器,当客户机和服务器之间的操作很多时,将产生大量的网络传输。如果将这些过程放在一个存储过程中,那么客户机和服务器之间的网络传输就会大大减少,降低了网络负载。
3.存储过程创建一次可以重复使用,从而可以减少数据库开发人员的工作量。
4.安全性,存储过程可以屏蔽对底层数据库对象的直接访问,使用EXEXUTE权限调用存储过程,无需拥有访问底层数据库对象的显式权限。create procedure insert_Student (_name varchar(50),_age int ,out _id int)
begin
insert into student value(null,_name,_age);
select max(stuId) into _id from student;
end;
call insert_Student('wfz',23,@id);
select @id;
26.用JDBC怎么调用存储过程?
贾琏欲执事
加载驱动
获取连接
设置参数
执行
释放连接
package com.huawei.interview.lym;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Types;
public class JdbcTest {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
Connection cn = null;
CallableStatement cstmt = null;
try {
//这里最好不要这么干,因为驱动名写死在程序中了
Class.forName("com.mysql.jdbc.Driver");
//实际项目中,这里应用DataSource数据,如果用框架,
//这个数据源不需要我们编码创建,我们只需Datasource ds = context.lookup()
//cn = ds.getConnection();
cn = DriverManager.getConnection("jdbc:mysql:///test","root","root");
cstmt = cn.prepareCall("{call insert_Student(?,?,?)}");
cstmt.registerOutParameter(3,Types.INTEGER);
cstmt.setString(1, "wangwu");
cstmt.setInt(2, 25);
cstmt.execute();
//get第几个,不同的数据库不一样,建议不写
System.out.println(cstmt.getString(3));
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
finally
{
/*try{cstmt.close();}catch(Exception e){}
try{cn.close();}catch(Exception e){}*/
try {
if(cstmt != null)
cstmt.close();
if(cn != null)
cn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
27.常用SQL
略28.简单说一下你对JDBC的理解
Java database connection (java数据库连接)。数据库管理系统(mysql oracle等)是很多,每个数据库管理系统支持的命令是不一样的。Java只定义接口,让数据库厂商自己实现接口,对于我们者而言。只需要导入对应厂商开发的实现即可。然后以接口方式进行调用.(mysql + mysql驱动(实现)+jdbc)29.简单的写一个JDBC的程序。(写一个访问oracle数据库的JDBC程序)
加载驱动、获取连接、设置参数、执行、释放连接(释放连接要从小到大,必须放到finally)30.JDBC中的PreparedStatement相比Statement的好处?
1. PreparedStatement是预编译的,比Statement速度快。
2.代码的可读性和可维护性要好。stmt.executeUpdate("insert into tb_name (col1,col2,col2,col4) values ('"+var1+"','"+var2+"',"+var3+",'"+var4+"')");
perstmt = con.prepareStatement("insert into tb_name (col1,col2,col2,col4) values (?,?,?,?)");
perstmt.setString(1,var1);
perstmt.setString(2,var2);
perstmt.setString(3,var3);
perstmt.setString(4,var4);
perstmt.executeUpdate();
不用我多说,对于第一种方法,别说其他人去读你的代码,就是你自己过一段时间再去读,都会觉得伤心。 3:安全性 PreparedStatement可以防止SQL注入攻击,而Statement却不能。String sql = "select * from tb_name where name= '"+varname+"' and passwd='"+varpasswd+"'";
如果我们把[' or '1' = '1]作为varpasswd传入进来.用户名随意,看看会成为什么?
select * from tb_name = '随意' and passwd = '' or '1' = '1';
因为'1'='1'肯定成立,所以可以任何通过验证,更有甚者:
把[';drop table tb_name;]作为varpasswd传入进来,则:
select * from tb_name = '随意' and passwd = '';drop table tb_name;有些数据库是不会让你成功的,但也有很多数据库就可以使这些语句得到执行。
而如果你使用预编译语句你传入的任何内容就不会和原来的语句发生任何匹配的关系,只要全使用预编译语句你就用不着对传入的数据做任何过虑。而如果使用普通的statement,有可能要对drop等做费尽心机的判断和过虑。31.数据库连接池的作用
1、限定数据库的个数,不会导致由于数据库连接过多导致系统运行缓慢或崩溃
2、数据库连接不需要每次都去创建或销毁,节约了资源
3、数据库连接不需要每次都去创建,响应时间更快。32.简单说一下html,css,javascript在网页开发中的定位?
HTML 超文本标记语言 定义网页的结构
CSS 层叠样式表,用来美化页面
JavaScript主要用来验证表单,做动态交互(其中ajax)33.简单介绍一下Ajax?
什么是Ajax? 异步的javascript和xml。
作用是什么?通过AJAX与服务器进行数据交换,AJAX可以使网页实现布局更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
怎么来实现Ajax XmlHttpRequest对象,使用这个对象可以异步向服务器发送请求,获取获取响应,完成局部更新。Open send responseText/responseXML 局部响应.。使用场景 登陆失败时不跳转页面,注册时提示用户名是否存在,二级联动等等使用场景34.js和jQuery的关系?
jQuery是一个js框架,封装了js的属性和方法。让用户使用起来更加便利,并且增强了js的功能。使用原生js是要处理很多兼容性的问题(注册事件等),由jQuery封装了底层,就不用处理兼容性问题。原生的js的dom和事件绑定和Ajax等操作非常麻烦,jQuery封装以后操作非常方便。35.jQuery的常用选择器?
ID选择器:通过ID获取一个元素。
Class选择器:通过类(css)获取元素。
标签选择器:通过标签获取元素。
通用选择器(*):获取所有的元素。
div.myCls :获取有myCls这个类的div。
层次选择器:儿子选择器 ‘>’确定,获取下面的子元素;后代选择器:‘空格’ 获取下面后代,包括儿子、孙子等后代。
属性选择器:Tag[attrName=’test’] 获取有属性名为xxxx并且属性的值为test的所有xxx标签。如:<input type=”checkbox” name=”hobby”/> 吃饭<br/>;<input type=”checkbox” name=”hobby”/> 睡觉<br/>。Input[name=’hobby’],表示获取属性名为name并且name属性值为hobby的的所有input标签元素 36.jQuery的页面加载完毕事件?
很多时候我们需要获取元素,但是必须等到该元素被加载完成后才能获取。我们可以把js代码放到该元素的后面,但是这样就会造成js在我们的body中存在不好管理。所有页面加载完毕后所有的元素当然已经加载完毕。一般获取元素做操作都要在页面加载完毕后操作。
第一种:$(document).ready(function(){}); $(document)把原生的document这个dom对象转换为jQuery对象,转换完成后才能调用ready方法。ready(fn),表示的是页面结构被加载完毕后执行传入函数fn
第二种:$(function(){}); 当页面加载完毕后执行里面的函数,这一种相对简单,用得最多。
window.onload的区别:
1、jQuery中的页面加载完毕事件,表示的是页面结构被加载完毕。
2、window.onload 表示的是页面被加载完毕。<img src=”htttp://baidu.com/1.jpg”/> onload必须等等页面中的图片、声音、图像等远程资源被加载完毕后才调用而jQuery中只需要页面结构被加载完毕。37.Jquery的Ajax和原生Js实现Ajax有什么关系?
jQuery中的Ajax也是通过原生的js封装的。封装完成后让我们使用起来更加便利,不用考虑底层实现或兼容性等处理。如果采用原生js实现Ajax是非常麻烦的,并且每次都是一样的。如果我们不使用jQuery我们也要封装Ajax对象的方法和属性。有像jQuery这些已经封装完成,并经过很多企业实际的框架,比较可靠并且开源。我们就不需要封装,直接使用成熟的框架(jQuery)即可。38.简单说一下html5?你对现在的那些新技术有了解?
Html5是最新版本的html,是在原来html4的基础上增强了一些标签。Html增加一些像画板、声音、视频、web存储等高级功能。但是html5有一个不好的地方,那就是html5太强调语义了,导致开发中都不知道要选择那个标签。
做页面布局时,无论头部、主题、导航等模块都使用div来表示,但是html5的规范,需要使用不同的标签来表示。(header footer等)39.简单说一下css3?
Css3是最新版本的css,是对原理css2的功能增强。
Css3中提供一些原来css2中实现起来比较困难或者不能实现的功能。
1、盒子圆角边框
2、盒子和文字的阴影
3、渐变
4、转换 移动、缩放、旋转等
5、过渡、动画都可以使用动画。
6、可以使用媒体查询实现响应式网站。
Css3最大缺点就是要根据不同的浏览器处理兼容性。对应有一些处理兼容性的工具。不用担心.40.BootStrap是什么?
BootStrap是一个移动设备优先的UI框架。我们可以不用谢任何css,js代码就能实现比较漂亮的有交互性的页面。我们程序员对页面的编写是有硬伤的,所有要自己写页面的话就要使用类似于bootstrap这样的UI框架。
平时用得很多的:1、模态框 2、表单,表单项 3、布局 4、删格系统41.什么是框架?
框架(Framework)是一个框子——指其约束性,也是一个架子——指其支撑性。
IT语境中的框架,特指为解决一个开放性问题而设计的具有一定约束性的支撑结构。在此结构上可以根据具体问题扩展、安插更多的组成部分,从而更迅速和方便地构建完整的解决问题的方案
1)框架本身一般不完整到可以解决特定问题,但是可以帮助您快速解决特定问题;没有框架所有的工作都从零开始做,有了框架,为我们提供了一定的功能,我们就可以在框 架的基础上开发,极大的解放了生产力。不同的框架,是为了解决不同领域的问题。一定要为了解决问题才去学习框架。
2)框架天生就是为扩展而设计的;
3)框架里面可以为后续扩展的组件提供很多辅助性、支撑性的方便易用的实用工具(utilities),也就是说框架时常配套了一些帮助解决某类问题的库(libraries)或工具(tools)。
java中就是一系列的jar包,其本质就是对jdk功能的扩展.42.MVC模式
MVC全名是Model View Controller,是模型(model)-视图(view)-控制器(controller)的缩写.
最简单的、最经典就是Jsp(view)+Servlet(controller) + JavaBean(model) 。
1、当控制器收到来自用户的请求
2、控制器调用JavaBean完成业务
3、完成业务后通过控制器跳转JSP页面的方式给用户反馈信息
4、Jsp个 用户做出响应。控制器都是核心43.MVC框架
什么是MVC框架?是为了解决传统MVC模式(Jsp + Servlet + JavaBean)的一些问题而出现的框架。
传统MVC模式问题:
1、所有的Servlet和Servlet映射都要配置在web.xml中,如果项目太大,web.xml就太庞大,并且不能实现模块化管理。
2、Servlet的主要功能就是接受参数、调用逻辑、跳转页面,比如像其他字符编码、文件上传等功能也要写在Servlet中,不能让Servlet主要功能而需要做处理一下特例。
3、接受参数比较麻烦(String name = request.getParameter(“name”),User user=new User user.setName(name)),不能通过model接收,只能单个接收,接收完成后转换封装model.
4、跳转页面方式比较单一(forword,redirect),并且当我的页面名称发生改变时需要修改Servlet源代码.
现在比较常用的MVC框架有:Struts2、Spring MVC44.简单讲一下struts2的执行流程?
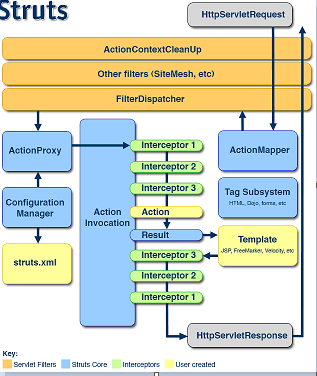
一个请求在Struts2框架中的处理大概分为以下几个步骤:
1、客户端浏览器发送请求
2、这个请求经过一系列的过滤器(Filter)(这些过滤器中有一个叫做ActionContextCleanUp的可选过滤器,这个过滤器对于Struts2和其他框架的集成很有帮助,例如:SiteMesh Plugin);
3、接着FilterDispatcher(StrutsPrepareAndExecuteFilter)被调用,FilterDispatcher(StrutsPrepareAndExecuteFilter)询问ActionMapper来决定这个请求是否需要调用某个Action;
4、如果ActionMapper决定需要调用某个Action,FilterDispatcher(StrutsPrepareAndExecuteFilter)把请求的处理交给ActionProxy;
5、ActionProxy通过Configuration Manager询问框架的配置文件,找到需要调用的Action类;
6、ActionProxy创建一个ActionInvocation的实例。
7、ActionInvocation实例使用命名模式来调用,在调用Action的过程前后,涉及到相关拦截器(Intercepter)的调用。
8、一旦Action执行完毕,ActionInvocation负责根据struts.xml中的配置找到对应的返回结果。返回结果通常是(但不总是,也可能是另外的一个Action链)一个需要被表示的JSP或者FreeMarker的模版。在表示的过程中可以使用Struts2框架中继承的标签。在这个过程中需要涉及到ActionMapper。
面试:
1、浏览器发送请求,经过一系列的过滤器后,到达核心过滤器(StrutsPrepareAndExecuteFilter).
2、StrutsPrepareAndExecuteFilter通过ActionMapper判断当前的请求是否需要某个Action处理,如果不需要,则走原来的流程。如果需要则把请求交给ActionProxy来处理
3、ActionProxy通过Configuration Manager询问框架的配置文件(Struts.xml),找到需要调用的Action类;
4、创建一个ActionInvocation实例,来调用Action的对应方法来获取结果集的name,在调用前后会执行相关拦截器。
5、通过结果集的Name知道对应的结果集来对浏览器进行响应。
拦截、判断、寻找、执行、响应45.Struts2中的拦截器,你都用它干什么?
java里的拦截器是动态拦截Action调用的对象。它提供了一种机制可以使开发者可以定义在一个action执行的前后执行的代码,也可以在一个action执行前阻止其执行,同时也提供了一种可以提取action中可重用部分的方式。
在AOP(Aspect-Oriented Programming)中拦截器用于在某个方法或字段被访问之前,进行拦截然后在之前或之后加入某些操作。
面试: struts2中的的功能(参数处理、文件上传、字符编码等)都是通过系统拦截器实现的。
如果业务需要,当然我们也可以自定义拦截器,进行可插拔配置,在执行Action的方法前后、加入相关逻辑完成业务。
使用场景:
1、用户登录判断,在执行Action的前面判断是否已经登录,如果没有登录的跳转到登录页面。
2、用户权限判断,在执行Action的前面判断是否具有,如果没有权限就给出提示信息。
3、操作日志......
4、......46.简单讲一下SpringMVC的执行流程?

1. 用户向服务器发送请求,请求被Spring 前端控制Servelt DispatcherServlet捕获;
2. DispatcherServlet对请求URL进行解析,得到请求资源标识符(URI)。然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象(包括Handler对象以及Handler对象对应的拦截器),最后以HandlerExecutionChain对象的形式返回;
3. DispatcherServlet 根据获得的Handler,选择一个合适的HandlerAdapter。(附注:如果成功获得HandlerAdapter后,此时将开始执行拦截器的preHandler(...)方法)
4. 提取Request中的模型数据,填充Handler入参,开始执行Handler(Controller)。 在填充Handler的入参过程中,根据你的配置,Spring将帮你做一些额外的工作:
HttpMessageConveter: 将请求消息(如Json、xml等数据)转换成一个对象,将对象转换为指定的响应信息
数据转换:对请求消息进行数据转换。如String转换成Integer、Double等
数据根式化:对请求消息进行数据格式化。 如将字符串转换成格式化数字或格式化日期等
数据验证: 验证数据的有效性(长度、格式等),验证结果存储到BindingResult或Error中
5. Handler执行完成后,向DispatcherServlet 返回一个ModelAndView对象;
6. 根据返回的ModelAndView,选择一个适合的ViewResolver(必须是已经注册到Spring容器中的ViewResolver)返回给DispatcherServlet ;
7. ViewResolver 结合Model和View,来渲染视图
8. 将渲染结果返回给客户端。
面试:
1、 用户向服务器发送请求,请求被Spring 前端控制Servelt DispatcherServlet捕获(捕获)
2、 DispatcherServlet对请求URL进行解析,得到请求资源标识符(URI)。然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象(包括Handler对象以及Handler对象对应的拦截器),最后以HandlerExecutionChain对象的形式返回;(查找handler)
3、 DispatcherServlet 根据获得的Handler,选择一个合适的HandlerAdapter。 提取Request中的模型数据,填充Handler入参,开始执行Handler(Controller), Handler执行完成后,向DispatcherServlet 返回一个ModelAndView对象(执行handler)
4、DispatcherServlet 根据返回的ModelAndView,选择一个适合的ViewResolver(必须是已经注册到Spring容器中的ViewResolver) (选择ViewResolver)
5、通过ViewResolver 结合Model和View,来渲染视图,DispatcherServlet 将渲染结果返回给客户端。(渲染返回)
快速记忆技巧:
核心控制器捕获请求、查找Handler、执行Handler、选择ViewResolver,通过ViewResolver渲染视图并返回
46.说一下struts2和springMVC有什么不同?
目前企业中使用SpringMvc的比例已经远远超过Struts2,那么两者到底有什么区别,是很多初学者比较关注的问题,下面我们就来对SpringMvc和Struts2进行各方面的比较:
1. 核 心控制器(前端控制器、预处理控制器):对于使用过mvc框架的人来说这个词应该不会陌生,核心控制器的主要用途是处理所有的请求,然后对那些特殊的请求 (控制器)统一的进行处理(字符编码、文件上传、参数接受、异常处理等等),spring mvc核心控制器是Servlet,而Struts2是Filter。
2.控制器实例:Spring Mvc会比Struts快一些(理论上)。Spring Mvc是基于方法设计,而Sturts是基于对象,每次发一次请求都会实例一个action,每个action都会被注入 属性,而Spring更像Servlet一样,只有一个实例,每次请求执行对应的方法即可(注意:由于是单例实例,所以应当避免全局变量的修改,这样会产生线程安全问题)。
3. 管理方式:大部分的公司的核心架构中,就会使用到spring,而spring mvc又是spring中的一个模块,所以spring对于spring mvc的控制器管理更加简单方便,而且提供了全 注解方式进行管理,各种功能的注解都比较全面,使用简单,而struts2需要采用XML很多的配置参数来管理(虽然也可以采用注解,但是几乎没有公司那 样使用)。
4.参数传递:Struts2中自身提供多种参数接受,其实都是通过(ValueStack)进行传递和赋值,而SpringMvc是通过方法的参数进行接收。
5.学习难度:Struts有很多新的技术点,比如拦截器、值栈及OGNL表达式,学习成本较高,springmvc 比较简单,很较少的时间都能上手。
6.intercepter 的实现机制:struts有以自己的interceptor机制,spring mvc用的是独立的AOP方式。这样导致struts的配置文件量还是比spring mvc大,虽然struts的配置能继承,所以我觉得论使用上来讲,spring mvc使用更加简洁,开发效率Spring MVC确实比struts2高。spring mvc是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上spring3 mvc就容易实现restful url。struts2是类级别的拦截,一个类对应一个request上下文;实现restful url要费劲,因为struts2 action的一个方法可以对应一个url;而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。spring3 mvc的方法之间基本上独立的,独享request response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架方法之间不共享变量,而struts2搞的就比较乱,虽然方法之间 也是独立的,但其所有Action变量是共享的,这不会影响程序运行,却给我们编码,读程序时带来麻烦。
7.spring mvc处理ajax请求,直接通过返回数据,方法中使用注解@ResponseBody,spring mvc自动帮我们对象转换为JSON数据。而struts2是通过插件的方式进行处理
在SpringMVC流行起来之前,Struts2在MVC框架中占核心地位,随着SpringMVC的出现,SpringMVC慢慢的取代struts2,但是很多企业都是原来搭建的框架,使用Struts2较多。47.说一下Spring中的两大核心?
spring是J2EE应用程序框架,是轻量级的IoC和AOP的容器框架(相对于重量级的EJB),主要是针对javaBean的生命周期进行管理的轻量级容器,可以单独使用,也可以和Struts框架,ibatis框架等组合使用。
1.IOC(Inversion of Control )或DI(Dependency Injection)
IOC控制权反转。原来:我的Service需要调用DAO,Service就需要创建DAO。Spring:Spring发现你Service依赖于dao,就给你注入。
核心原理:就是配置文件+反射(工厂也可以)+容器(map)
2.AOP:面向切面编程
核心原理:使用动态代理的设计模式在执行方法前后或出现异常做加入相关逻辑。
我们主要使用AOP来做:1、事务处理 2、权限判断 3、日志48.讲一下Spring的事务传播特性
1. PROPAGATION_REQUIRED: 如果存在一个事务,则支持当前事务。如果没有事务则开启
2. PROPAGATION_SUPPORTS: 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行
3. PROPAGATION_MANDATORY: 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
4. PROPAGATION_REQUIRES_NEW: 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
5. PROPAGATION_NOT_SUPPORTED: 总是非事务地执行,并挂起任何存在的事务。
6. PROPAGATION_NEVER: 总是非事务地执行,如果存在一个活动事务,则抛出异常
7. PROPAGATION_NESTED:如果一个活动的事务存在,则运行在一个嵌套的事务中. 如果没有活动事务, 则按TransactionDefinition.PROPAGATION_REQUIRED 属性执行
Propagation:
Required 需要 如果存在一个事务,则支持当前事务。如果没有事务则开启
Supports 支持 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行
Mandatory 必要的 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。
required_new 总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。
Not_support 总是非事务地执行,并挂起任何存在的事务。
Never 绝不 总是非事务地执行,如果存在一个活动事务,则抛出异常
Nested 嵌套的 如果有就嵌套、没有就开启事务48.什么是ORM?
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。那么,到底如何实现持久化呢?一种简单的方案是采用硬编码方式(jdbc操作sql方式),为每一种可能的数据库访问操作提供单独的方法。
这种方案存在以下不足:
1.持久化层缺乏弹性。一旦出现业务需求的变更,就必须修改持久化层的接口
2.持久化层同时与域模型与关系数据库模型绑定,不管域模型还是关系数据库模型发生变化,都要修改持久化曾的相关程序代码,增加了软件的维护难度。
ORM提供了实现持久化层的另一种模式,它采用映射元数据来描述对象关系的映射,使得ORM中间件能在任何一个应用的业务逻辑层和数据库层之间充当桥梁。Java典型的ORM框架有:Hibernate,ibatis(mybatis),speedframework。
ORM的方法论基于三个核心原则:
简单:以最基本的形式建模数据。
传达性:数据库结构被任何人都能理解的语言文档化。
精确性:基于数据模型创建正确标准化了的结构。
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。可以简单的方案是采用硬编码方式(jdbc操作sql方式),为每一种可能的数据库访问操作提供单独的方法。这种方法存在很多缺陷,使用使用ORM框架(为了解决解决面向对象与关系数据库存在的互不匹配的现象的框架)来解决.
关于Java面试的更多相关文章
- JAVA面试中问及HIBERNATE与 MYBATIS的对比,在这里做一下总结
我是一名java开发人员,hibernate以及mybatis都有过学习,在java面试中也被提及问道过,在项目实践中也应用过,现在对hibernate和mybatis做一下对比,便于大家更好的理解和 ...
- 转:最近5年133个Java面试问题列表
最近5年133个Java面试问题列表 Java 面试随着时间的改变而改变.在过去的日子里,当你知道 String 和 StringBuilder 的区别就能让你直接进入第二轮面试,但是现在问题变得越来 ...
- java面试宝典(蓝桥学院)
Java面试宝典(蓝桥学院) 回答技巧 这套面试题主要目的是帮助那些还没有java软件开发实际工作经验,而正在努力寻找java软件开发工作的学生在笔试/面试时更好地赢得好的结果.由于这套试题涉及的范围 ...
- JAVA面试精选【Java基础第一部分】
这个系列面试题主要目的是帮助你拿轻松到offer,同时还能开个好价钱.只要能够搞明白这个系列的绝大多数题目,在面试过程中,你就能轻轻松松的把面试官给忽悠了.对于那些正打算找工作JAVA软件开发工作的童 ...
- Java面试必备知识
JAVA面试必备知识 第一,谈谈final, finally, finalize的区别. 第二,Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类,是否可 ...
- java面试和笔试大全 分类: 面试 2015-07-10 22:07 10人阅读 评论(0) 收藏
2.String是最基本的数据类型吗? 基本数据类型包括byte.int.char.long.float.double.boolean和short. java.lang.String类是final类型 ...
- 近5年133个Java面试问题列表
Java 面试随着时间的改变而改变.在过去的日子里,当你知道 String 和 StringBuilder 的区别就能让你直接进入第二轮面试,但是现在问题变得越来越高级,面试官问的问题也更深入. 在我 ...
- java 面试
115个Java面试题和答案——终极列表(上) 本文我们将要讨论Java面试中的各种不同类型的面试题,它们可以让雇主测试应聘者的Java和通用的面向对象编程的能力.下面的章节分为上下两篇,第一 ...
- 【Java面试】基础知识篇
[Java面试]基础知识篇 Java基础知识总结,主要包括数据类型,string类,集合,线程,时间,正则,流,jdk5--8各个版本的新特性,等等.不足的地方,欢迎大家补充.源码分享见个人公告.Ja ...
- JAVA面试中问及HIBERNATE与 MYBATIS的对比,在这里做一下总结(转)
hibernate以及mybatis都有过学习,在java面试中也被提及问道过,在项目实践中也应用过,现在对hibernate和mybatis做一下对比,便于大家更好的理解和学习,使自己在做项目中更加 ...
随机推荐
- C# 如何添加PPT背景(纯色背景、渐变色背景、图片背景)
我们在创建Powerpoint文档时,系统默认的幻灯片是空白背景的,很多时候我们需要自定义幻灯片背景,以达到美观的文档效果.在下面的示例中将介绍给PowerPoint幻灯片设置背景的方法,主要包含以下 ...
- Oracle day02 函数
order by关键字作用:用于对查询结果进行排序 用法: 1.利用asc .desc对排序列进行升序或降序 2.order by后可以添加多个列(逗号分隔),当一个列的值相同时,在按第二 ...
- Spring Cloud Eureka 常用配置及说明
配置参数 默认值 说明 服务注册中心配置 Bean类:org.springframework.cloud.netflix.eureka.server.EurekaServerConfigBean eu ...
- 设计模式之一工厂方法模式(Factory Method)
工厂方法模式分为三种: 一.普通工厂模式,就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建.首先看下关系图: 举例如下:(我们举一个发送邮件和短信的例子) 首先,创建二者的共同接口: pub ...
- 原生js及H5模拟鼠标点击拖拽
一.原生js 1.拖拽的流程动作 鼠标按下 触发onmousedown事件 鼠标移动 触发onmousemove事件 鼠标松开 触发onmouseup事件 2.注意事项: 要防止div移出可视框,要限 ...
- springboot之配置文件
springboot在加载配置文件的时候是有先后顺序的,了解加载配置文件的先后顺序,可以减少编写程序出现错误 1 springboot加载配置文件的先后顺序如下: SpringApplication将 ...
- JSON WEB TOKEN(JWT)的分析
JSON WEB TOKEN(JWT)的分析 一般情况下,客户的会话数据会存在文件中,或者引入redis来存储,实现session的管理,但是这样操作会存在一些问题,使用文件来存储的时候,在多台机器上 ...
- 【Dojo 1.x】笔记目录
学习笔记和教程是不同的,笔记是随心记,学到什么就写什么,我尽量按逻辑顺序写笔记. Dojo是什么? Dojo是这么一个JavaScript框架,区别于jQuery等小型类库,这个类库更合适于构建Web ...
- 【已解决】checkout 配置无效的问题可以进来看下
在日常工作中,我们经常会遇到要更新一个项目,但是由于更改了配置,需要将这些配置commit或者checkout,但是有的同学不想commit怎么办呢,只能通过checkout,那么问题又来了,改了很多 ...
- FFmpeg AVPacket相关主要函数介绍
1.AVPacket相关函数介绍 操作AVPacket的函数大约有30个,主要分为:AVPacket的创建初始化,AVPacket中的data数据管理(clone,free,copy),AVPacke ...