Jsoup获取全国地区数据(省市县镇村)
最近手头在做一些东西,需要一个全国各地的地域数据,从省市区到县镇乡街道的。各种度娘,各种谷歌,都没找到一个完整的数据。最后功夫不负有心人,总算找到一份相对来说比较完整的数据,但是这里的数据也只是精确到镇级别,没有村一级的数据(后来通过分析数据源我知道了为什么,呵呵),在加上博主提供的有些数据存在冗余,对于有强迫症和追求完美的我,心想着我一定要自己动手去把这部分数据给爬取出来。
上述博文中的内容还算丰富,博主是用的是php来实现的,作为2015年度编程语言排行榜的第一位,我们也不能示弱啊,下面我就带着大家一起来看看用java怎么从网页当中爬取我们想要的数据...
第一步、准备工作(数据源+工具):
数据源(截止目前最全面权威的官方数据):http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2013/
爬取数据的工具(爬虫工具):http://jsoup.org/
第二步、数据源分析:
首先jsoup工具的使用我在这里就不做讲解了,感兴趣的可以自己动手去查阅。
做开发就应该多去了解一些软件工具的使用,在平常开发过程中遇到了才知道从何下手,鼓励大家多平时留意一些身边的软件工具,以备不时之需。在做这个东西以前,我也不知道jsoup要怎么用,但我知道jsoup可以用来干嘛,在我需要的用到的时候,再去查阅资料,自己学习。
上述的数据源是2013年中华人民共和国国家统计局发布的,其准确性和权威性不言而喻。
接下来我们分析一下数据源的结构,先从首页说起: 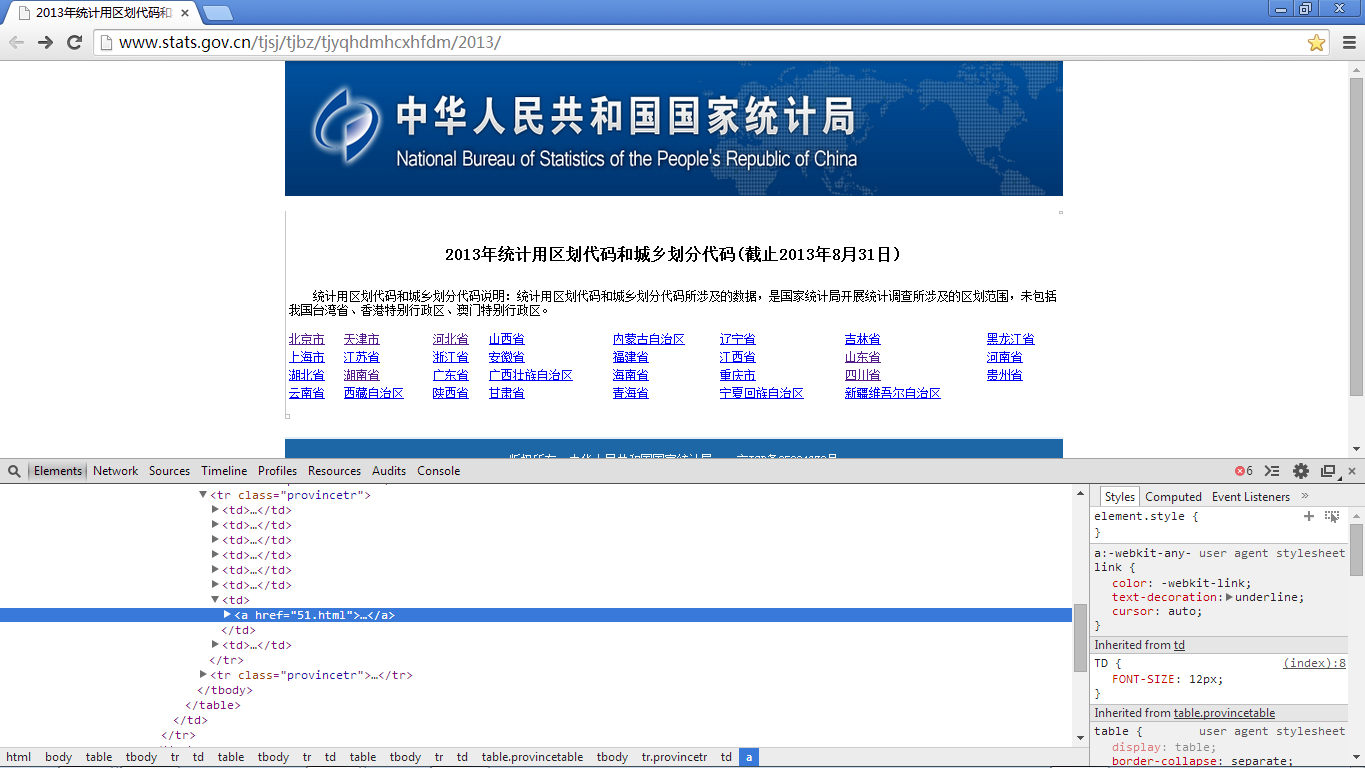
通过分析首页源码我们可以得到如下3点:
- 页面的整个布局是用的table标签来控制的,也就是说我们如果要通过jsoup来选择超链接,那么一定要注意,上图中不是只要标注了省市地区的地方采用的才是表格,整个页面中存在多个表格,因此是不可以直接通过表格
Document connect = connect("http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2013/");
Elements rowProvince = connect.select("table");来解析数据的。
- 页面中有超链接的部分有多少地方。可能是官方考虑到了你们这种程序员需要获取这样的数据的原因吧,页面很干净,除开下方的备案号是多余的超链接,其他的链接可以直接爬取。
- 省份城市的数据规律。包含有效信息的表格的每一行都有一个class属性provincetr,这个属性很重要,至于为什么重要,请接着往下看;每一行数据中存在多个td标签,每一个td标签中包含一个a超链接,而这个超链接正是我们想要的超链接,超链接的文本即使省份(直辖市等)的名称。
再次我们再看一下一般的数据页面(一般的数据页面包括市级、县级、镇级这三级数据展示页面):
之所以要把上述三个页面放在一起,是因为通过分析我们可以发现,这三级数据的数据页面完全一致,唯一不同的就是在html源码数据表格中的数据行tr的class属性不一致,分别对应为:citytr,countrytrhe towntr。其他均一致。这样我们就可以用一个通用的方法解决这三个页面的数据爬取。 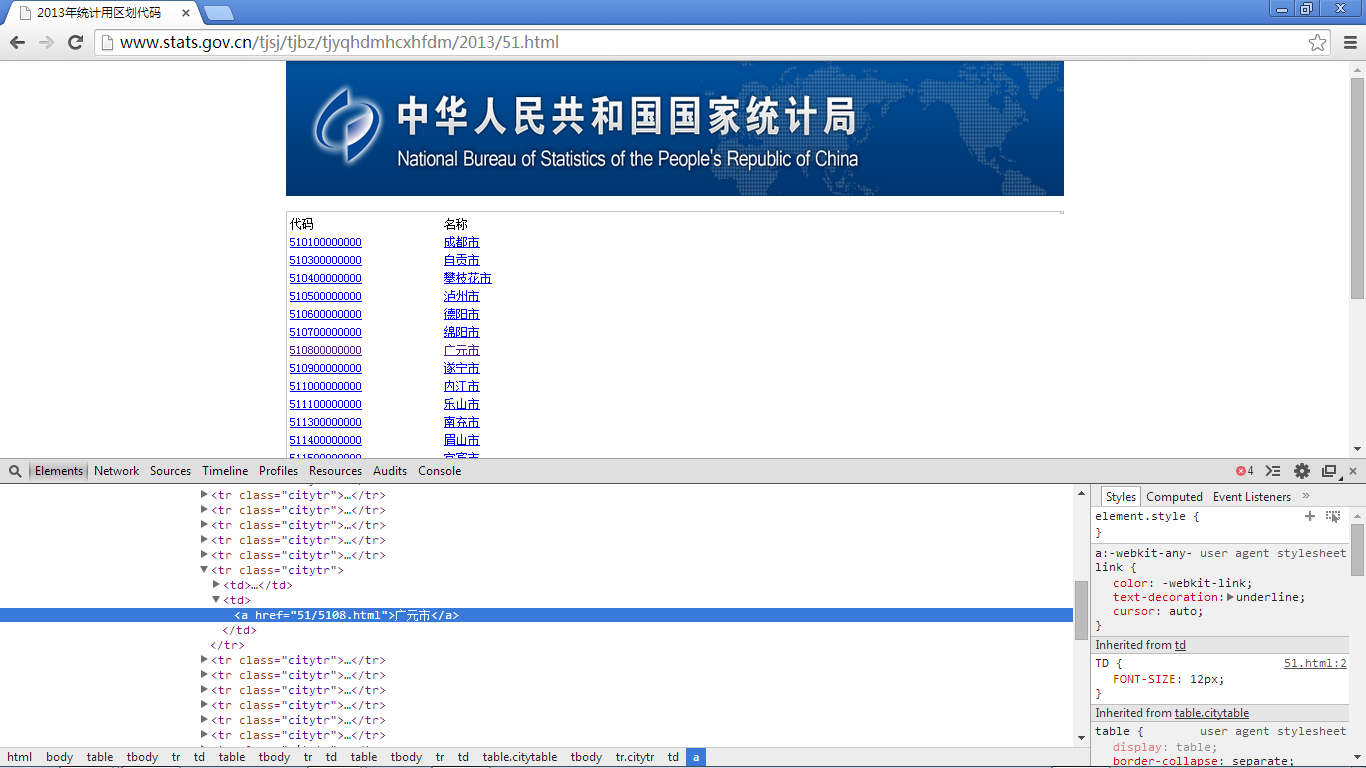
最后看看村一级的数据页面: 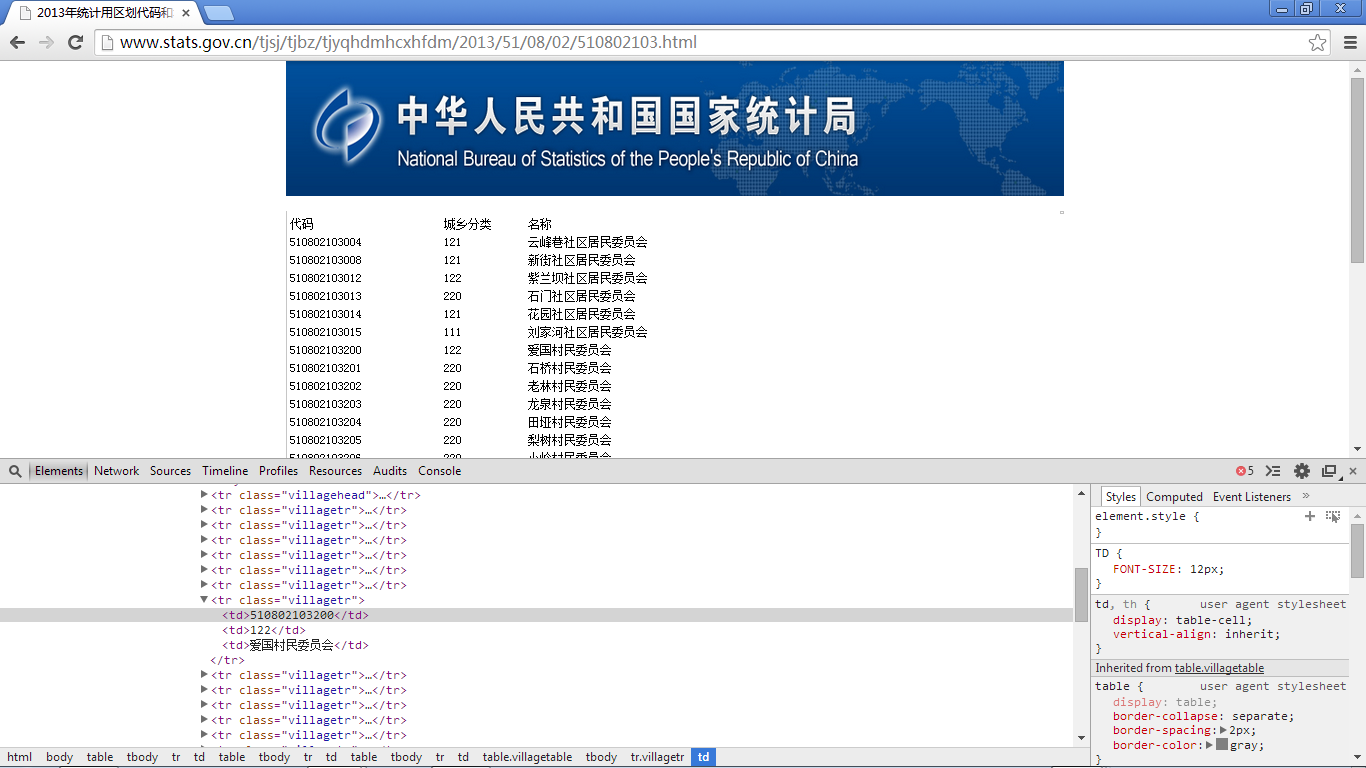
在村一级的数据中,和上述市县镇的数据格式不一致,这一级所表示的数据是最低一级的,所以不存在a链接,因此不能采用上面市县镇数据的爬取方式去爬取;这里展示数据的表格行的class为villagetr,除开这两点以外,在每一行数据中包含三列数据,第一列是citycode,第二列是城乡分类(市县镇的数据格式不存在这一项),第三列是城市名称。
把握了以上各个要点之外,我们就可以开始编码了。
第三步、编码实现:
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; /**
* 全国省市县镇村数据爬取
* @author liushaofeng
* @date 2015-10-11 上午12:19:39
* @version 1.0.0
*/
public class JsoupTest
{
private static Map<Integer, String> cssMap = new HashMap<Integer, String>();
private static BufferedWriter bufferedWriter = null; static
{
cssMap.put(, "provincetr");// 省
cssMap.put(, "citytr");// 市
cssMap.put(, "countytr");// 县
cssMap.put(, "towntr");// 镇
cssMap.put(, "villagetr");// 村
} public static void main(String[] args) throws IOException
{
int level = ; initFile(); // 获取全国各个省级信息
Document connect = connect("http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2013/");
Elements rowProvince = connect.select("tr." + cssMap.get(level));
for (Element provinceElement : rowProvince)// 遍历每一行的省份城市
{
Elements select = provinceElement.select("a");
for (Element province : select)// 每一个省份(四川省)
{
parseNextLevel(province, level + );
}
} closeStream();
} private static void initFile()
{
try
{
bufferedWriter = new BufferedWriter(new FileWriter(new File("d:\\CityInfo.txt"), true));
} catch (IOException e)
{
e.printStackTrace();
}
} private static void closeStream()
{
if (bufferedWriter != null)
{
try
{
bufferedWriter.close();
} catch (IOException e)
{
e.printStackTrace();
}
bufferedWriter = null;
}
} private static void parseNextLevel(Element parentElement, int level) throws IOException
{
try
{
Thread.sleep();//睡眠一下,否则可能出现各种错误状态码
} catch (InterruptedException e)
{
e.printStackTrace();
} Document doc = connect(parentElement.attr("abs:href"));
if (doc != null)
{
Elements newsHeadlines = doc.select("tr." + cssMap.get(level));//
// 获取表格的一行数据
for (Element element : newsHeadlines)
{
printInfo(element, level + );
Elements select = element.select("a");// 在递归调用的时候,这里是判断是否是村一级的数据,村一级的数据没有a标签
if (select.size() != )
{
parseNextLevel(select.last(), level + );
}
}
}
} /**
* 写一行数据到数据文件中去
* @param element 爬取到的数据元素
* @param level 城市级别
*/
private static void printInfo(Element element, int level)
{
try
{
bufferedWriter.write(element.select("td").last().text() + "{" + level + "}["
+ element.select("td").first().text() + "]");
bufferedWriter.newLine();
bufferedWriter.flush();
} catch (IOException e)
{
e.printStackTrace();
}
} private static Document connect(String url)
{
if (url == null || url.isEmpty())
{
throw new IllegalArgumentException("The input url('" + url + "') is invalid!");
}
try
{
return Jsoup.connect(url).timeout( * ).get();
} catch (IOException e)
{
e.printStackTrace();
return null;
}
}
}
数据爬取过程便是一个漫长的过程,只需要慢慢等待吧,呵呵,由于程序运行时间较长,请不要在控制台打印输出,否则可能会影响程序运行....
最终获取到数据的格式如下("{}"中表示城市级别,"[]"中内容表示城市编码):

拿到以上数据以后,自己想干什么都可以自我去实现了,以上的代码可以直接运行,从数据源爬取后,可以直接转换成自己所要的格式。
后续处理的最终结果,请参见博文:http://www.cnblogs.com/liushaofeng89/p/4937714.html
如果你觉得本博文对你有所帮助,请记得点击右下方的"推荐"哦,么么哒...
转载请注明出处:http://www.cnblogs.com/liushaofeng89/p/4873086.html
Jsoup获取全国地区数据(省市县镇村)的更多相关文章
- Jsoup获取全国地区数据(省市县镇村)(续) 纯干货分享
前几天给大家分享了一下,怎么样通过jsoup来从国家统计局官网获取全国省市县镇村的数据.错过的朋友请点击这里.上文说到抓取到数据以后,我们怎么转换成我们想要格式呢?哈哈,解析方式可能很简单,但是有一点 ...
- 省市县镇村五级地址智能提取(标准地址源来自国家统计局官网)SpringBoot+Elasticsearch 5.6
项目目的 根据传入的地址,智能提取所属的省市县镇村5级地址.例如:用户输入“江苏南通嗨安李堡镇陈庄村8组88号”,我们需要提取到江苏省 南通市 海安县(即便用户输入了错字,“海”写成了“嗨”) 李 ...
- Jsoup获取部分页面数据失败 org.jsoup.UnsupportedMimeTypeException: Unhandled content type. Must be text/*, application/xml, or application/xhtml+xml.
用Jsoup在获取一些网站的数据时,起初获取很顺利,但是在访问某浪的数据是Jsoup报错,应该是请求头里面的请求类型(ContextType)不符合要求. 请求代码如下: private static ...
- Jsoup获取部分页面数据失败 Unhandled content type. Must be text/*, application/xml, or application/xhtml+xml
用Jsoup在获取一些网站的数据时,起初获取很顺利,但是在访问某浪的数据是Jsoup报错,应该是请求头里面的请求类型(ContextType)不符合要求. 请求代码如下: private static ...
- 全中国的省市县镇乡村数据获取以及展示java源代码
第一步.准备工作(数据源+工具): 数据源(截止目前最全面权威的官方数据):http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2013/ 爬取数据的工具 ...
- 获取上海地区AQI质量数据Python脚本
一个获取上海地区AQI质量的Python脚本 https://github.com/yanyueoo7/Raspberrypi/blob/master/GetPmData_Shanghai.py #! ...
- 获取全国市以及地理坐标,各大坐标系北斗,百度,WGS-84坐标系的转换,有图,有代码
1 先上坐标取到的值: 获取到的坐标部分如下: '北京市':[116.39564503788,39.92998577808], '天津市':[117.21081309155,39.1439299033 ...
- 全国天气预报数据API调用PHP示例
本代码示例是基于PHP的聚合数据全国天气预报API服务请求的代码样例,使用前你需要: ①:通过https://www.juhe.cn/docs/api/id/39 申请一个天气预报API的appkey ...
- 全国地区sql表
/** * 中国省市区--地区SQL表 */ CREATE TABLE `rc_district` ( `id` smallint(5) unsigned NOT NULL AUTO_INCREMEN ...
随机推荐
- postgres 11 单实例最大支持多少个database?
有人在pg8时代(10年前)问过,当时说10000个没问题,而且每个db会在/base下建立1个文件夹, 文件ext3只支持32000个子文件夹,所以这是上限了. 而现在早就ext4了,根本没有限制了 ...
- UVALive - 5857 Captain Q's Treasure
UVALive - 5857 思路: 状压dp,用map写 代码: #pragma GCC optimize(2) #pragma GCC optimize(3) #pragma GCC optimi ...
- NetSec2019 20165327 Exp6 信息搜集与漏洞扫描
NetSec2019 20165327 Exp6 信息搜集与漏洞扫描 一.实践目标 掌握信息搜集的最基础技能与常用工具的使用方法. 二.实践内容 1.各种搜索技巧的应用 2.DNS IP注册信息的查询 ...
- js统一设置富文本中的图片宽度
var txt = layedit.getContent(ieditor);//获取编辑器内的文本var regex = new RegExp('<img', 'gi');txt = txt.r ...
- 【Java】【10】后台处理Emoji表情
问题:存到数据库的emoji表情,取出来后,在前端显示为乱码 环境:SpringBoot + Oracle(MySQL据说是支持表情的) 解决方案: 引入emoji相关的jar包,使用很方便,不过表情 ...
- ubuntu nginx ssl 证书配置
前几天自己用 egg.js 写了个 api 接口,然后把它部署到服务器上.服务器是ubuntu 16.04 + nginx:因为要用到https,然后今天实践了一下如何配置https. 关于htt ...
- iOS 底层解析weak的实现原理(包含weak对象的初始化,引用,释放的分析)
原文 很少有人知道weak表其实是一个hash(哈希)表,Key是所指对象的地址,Value是weak指针的地址数组.更多人的人只是知道weak是弱引用,所引用对象的计数器不会加一,并在引用对象被释放 ...
- kafka producer batch 发送消息
1. 使用 KafkaProducer 发送消息,是按 batch 发送的,producer 首先把消息放入 ProducerBatch 中: org.apache.kafka.clients.pro ...
- for 循环常见内置参数
系统相关的信息模块: import sys sys.argv 是一个 list,包含所有的命令行参数. sys.stdout sys.stdin sys.stderr 分别表示标准输入输出,错误输出的 ...
- windows下Redis安装及利用java操作Redis
一.windows下Redis安装 1.Redis下载 下载地址:https://github.com/MicrosoftArchive/redis 打开下载地址后,选择版本 然后选择压缩包 下载 R ...