使用Spark进行搜狗日志分析实例——统计每个小时的搜索量
package sogolog import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* 统计每小时搜索次数
*/
/*
搜狗日志示例
访问时间(时:分:秒) 用户ID [查询词] 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL
00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html
00:00:00 07594220010824798 [哄抢救灾物资] 1 1 news.21cn.com/social/daqian/2008/05/29/4777194_1.shtml
00:00:00 5228056822071097 [75810部队] 14 5 www.greatoo.com/greatoo_cn/list.asp?link_id=276&title=%BE%DE%C2%D6%D0%C2%CE%C5
00:00:00 6140463203615646 [绳艺] 62 36 www.jd-cd.com/jd_opus/xx/200607/706.html
*/
object CountByHours {
def main(args: Array[String]): Unit = { //1、启动spark上下文、读取文件
val conf = new SparkConf().setAppName("sougo count by hours").setMaster("local")
val sc = new SparkContext(conf)
var orgRdd = sc.textFile("C:\\Users\\KING\\Desktop\\SogouQ.reduced\\SogouQ.reduced")
println("总行数:"+orgRdd.count()) //2、map操作,遍历处理每一行数据
var map:RDD[(String,Integer)] = orgRdd.map(line=>{
//拿到小时
var h:String = line.substring(0,2)
(h,1)
}) //3、reduce操作,将上面的 map结果按KEY进行合并、叠加
var reduce:RDD[(String,Integer)] = map.reduceByKey((x,y)=>{
x+y
}) //打印出按小时排序后的统计结果
reduce.sortByKey().collect().map(println)
}
}
运行结果:
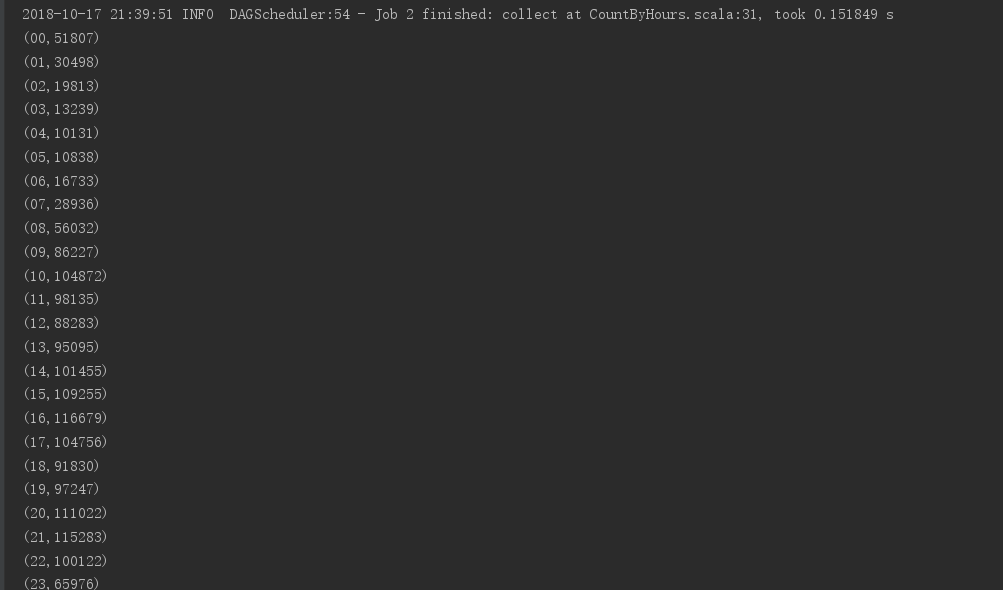
搜狗日志下载地址:http://www.sogou.com/labs/resource/q.php
使用Spark进行搜狗日志分析实例——统计每个小时的搜索量的更多相关文章
- 使用Spark进行搜狗日志分析实例——map join的使用
map join相对reduce join来说,可以减少在shuff阶段的网络传输,从而提高效率,所以大表与小表关联时,尽量将小表数据先用广播变量导入内存,后面各个executor都可以直接使用 pa ...
- 使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
package sogolog import org.apache.hadoop.io.{LongWritable, Text} import org.apache.hadoop.mapred.Tex ...
- ELK 日志分析实例
ELK 日志分析实例一.ELK-web日志分析二.ELK-MySQL 慢查询日志分析三.ELK-SSH登陆日志分析四.ELK-vsftpd 日志分析 一.ELK-web日志分析 通过logstash ...
- 基于Spark的网站日志分析
本文只展示核心代码,完整代码见文末链接. Web Log Analysis 提取需要的log信息,包括time, traffic, ip, web address 进一步解析第一步获得的log信息,如 ...
- Spark之搜狗日志查询实战
1.下载搜狗日志文件: 地址:http://www.sogou.com/labs/resource/chkreg.php 2.利用WinSCP等工具将文件上传至集群. 3.创建文件夹,存放数据: mk ...
- 日志分析-mime统计
提取日志中未落入标准字段的mime,分adx,adtype 统计mime的数量和包含js的数量占比 require 'date' require 'net/http' require 'uri' re ...
- spark提交异常日志分析
java.lang.NoSuchMethodError: org.apache.spark.sql.SQLContext.sql(Ljava/lang/String;)Lorg/apache/spar ...
- nginx日志分析及其统计PV、UV、IP
一.nginx日志结构 nginx中access.log 的日志结构: $remote_addr 客户端地址 211.28.65.253 $remote_user 客户端用户名称 -- $time_l ...
- 日志分析_统计每日各时段的的PV,UV
第一步: 需求分析 需要哪些字段(时间:每一天,各个时段,id,url,guid,tracTime) 需要分区为天/时 PV(统计记录数) UV(guid去重) 第二步: 实施步骤 建Hive表,表列 ...
随机推荐
- Java集合源码分析之LinkedList
1. LinkedList简介 public class LinkedList<E> extends AbstractSequentialList<E> implements ...
- bzoj1452 [JSOI2009]Count ——二维树状数组
中文题面,给你一个矩阵,每一个格子有数字,有两种操作. 1. 把i行j列的值更改 2. 询问两个角坐标分别为(x1,y1) (x2,y2)的矩形内有几个值为z的点. 这一题的特点就是给出的z的数据范围 ...
- 关于win10触控板两指点击无效的问题
一.前言 最近发现公司的本本两指点击触控板没有反应,单指和三指点击触控板都是正常的.网上也搜了 一些解决的方法,最开始因为没有明确自己的触控板是Synaptics还是Elan的,导致没有解决.首先我们 ...
- 8_管理及IO重定向
五大类:运算器.控制器:CPU存储器:RAM输入设备/输出设备 程序:是由指令和数据组成的 控制器:读取指令运算器:存储器: 地址总线:内存寻址数据总线:传输数据控制总线:控制指令 寄存器:CPU暂时 ...
- spring data jpa、Hibernate开启全球唯一UUID设置
spring data jpa.Hibernate开启全球唯一UUID设置 原文链接:https://www.cnblogs.com/blog5277/p/10662079.html 原文作者:博客园 ...
- windows下面Nginx日志切割
Nginx本身并不支持日志切割,那么就会造成日志非常的大,为了解决这个问题我们用到了windows的计划任务和dos命令.具体思路: 1.写一个dos文件,通过windows的计划任务定时执行(每天执 ...
- ajax得到后端数据一直提示为[object Object]解决方法
前段ajax <script type="text/javascript"> function requestJson() { $.ajax({ type : &quo ...
- git同时存在两个账号(在同一台电脑上)——三步完成
目录 1.首先是常规设置 2.同时添加两个账号 3.最后一步,配置~/.ssh/config文件 4.补充:有时因为设置了全局账号,因此需要清除 由于本人有连个git账号,个人github账号和公司g ...
- [转] jquery作者John Resig编写的微模板引擎:JavaScript Micro-Templating
I've had a little utility that I've been kicking around for some time now that I've found to be quit ...
- Windows编译安装使用cephfs客户端
本文介绍如何将cephfs映射到windows的一个盘上,以磁盘映射的方式访问cephfs. 1.下载必要安装包 tdm-gcc:(安装时选32位)https://sourceforge.net/pr ...