ES ik分词器使用技巧
match查询会将查询词分词,然后对分词的结果进行term查询。
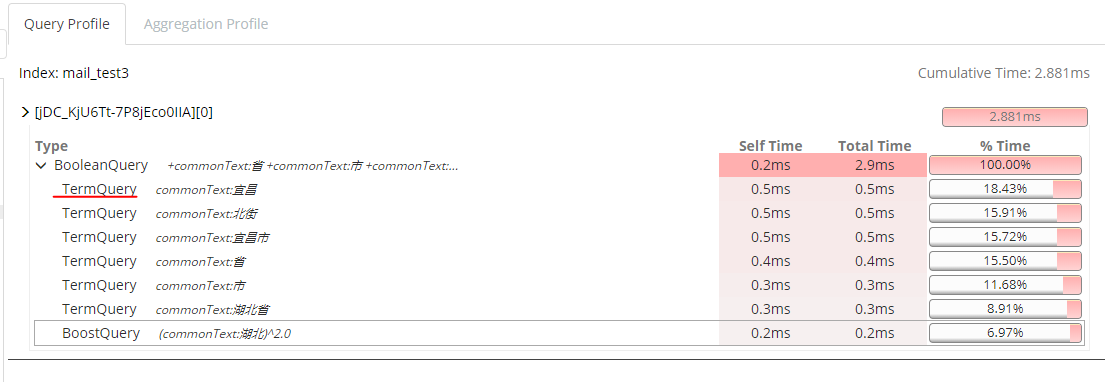
然后默认是将每个分词term查询之后的结果求交集,所以只要分词的结果能够命中,某条数据就可以被查询出来,而分词是在新建索引时指定的,只有text类型的数据才能设置分词策略。
新建索引,并指定分词策略:
PUT mail_test3
{
"settings": {
"index": {
"refresh_interval": "30s",
"number_of_shards": "1",
"number_of_replicas": "0"
}
},
"mappings": {
"default": {
"_all": {
"enabled": false
},
"_source": {
"enabled": true
},
"properties": {
"addressTude": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"copy_to": [
"commonText"
],
"fielddata": true
},
"captureTime": {
"type": "long"
},
"commonText": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fielddata": true
},
"commonNum":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fielddata": true
},
"imsi": {
"type": "keyword",
"copy_to": ["commonNum"]
},
"uuid": {
"type": "keyword"
}
}
}
}
}
analyzer 指的是在建索引时的分词策略,search_analyzer 指的是在查询时的分词策略。ik分词器还有一种ik_smart 的分词策略,可以比较两种分词策略的差别:
ik_smart分词策略:
GET mail_test3/_analyze
{
"analyzer": "ik_smart",
"text": "湖南省湘潭市江山路96号-11-8"
}
结果:
{
"tokens": [
{
"token": "湖南省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "湘潭市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 1
},
{
"token": "江",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 2
},
{
"token": "山路",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 3
},
{
"token": "96号",
"start_offset": 9,
"end_offset": 12,
"type": "TYPE_CQUAN",
"position": 4
},
{
"token": "11-8",
"start_offset": 13,
"end_offset": 17,
"type": "LETTER",
"position": 5
}
]
}
ik_max_word分词策略:
GET mail_test1/_analyze
{
"analyzer": "ik_max_word",
"text": "湖南省湘潭市江山路96号-11-8"
}
分词结果:
{
"tokens": [
{
"token": "湖南省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "湖南",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "省",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "湘潭市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
},
{
"token": "湘潭",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
},
{
"token": "市",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 5
},
{
"token": "江山",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 6
},
{
"token": "山路",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 7
},
{
"token": "96",
"start_offset": 9,
"end_offset": 11,
"type": "ARABIC",
"position": 8
},
{
"token": "号",
"start_offset": 11,
"end_offset": 12,
"type": "COUNT",
"position": 9
},
{
"token": "11-8",
"start_offset": 13,
"end_offset": 17,
"type": "LETTER",
"position": 10
},
{
"token": "11",
"start_offset": 13,
"end_offset": 15,
"type": "ARABIC",
"position": 11
},
{
"token": "8",
"start_offset": 16,
"end_offset": 17,
"type": "ARABIC",
"position": 12
}
]
}
ik_max_word分词器的分词结果更多,分词的粒度更细,而ik_smart的分词结果粒度更粗,但较为智能。一般的策略是建立索引使用ik_max_word,查询时使用ik_smart,这样就能尽可能多的查到结果,而且上文提到,match查询最终是转化为term查询,因此只要某个分词结果命中,结果中就会有该条数据。
如果对搜索结果的精度较高,可以在查询中加入operator参数,然后让分词结果的每个term查询结果之间求交集,这样能尽可能地提高精度。
这里的operator设置为or和and的差别较大,可以测试进行比较:
GET mail_test3/_search
{
"query": {
"match": {
"commonText": {
"query": "湖北省宜昌市天台东二街",
"operator": "and"
}
}
}
}
ES ik分词器使用技巧的更多相关文章
- ES系列一、CentOS7安装ES 6.3.1、集成IK分词器
Elasticsearch 6.3.1 地址: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3. ...
- 安装ik分词器以及版本和ES版本的兼容性
一.查看自己ES的版本号与之对应的IK分词器版本 https://github.com/medcl/elasticsearch-analysis-ik/blob/master/README.md 二. ...
- es之IK分词器
1:默认的分析器-- standard 使用默认的分词器 curl -XGET 'http://hadoop01:9200/_analyze?pretty&analyzer=standard' ...
- Elasticsearch5.1.1+ik分词器+HEAD插件安装小记
一.安装elasticsearch 1.首先需要安装好java,并配置好环境变量,详细教程请看 http://tecadmin.net/install-java-8-on-centos-rhel-an ...
- elasticsearch 之IK分词器安装
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik 安装好ES之后就可以安装分词器插件了 记住选择ES对应的版本 对应的有版本选择下载 ...
- 如何开发自己的搜索帝国之安装ik分词器
Elasticsearch默认提供的分词器,会把每个汉字分开,而不是我们想要的根据关键词来分词,我是中国人 不能简单的分成一个个字,我们更希望 “中国人”,“中国”,“我”这样的分词,这样我们就需要 ...
- elasticsearch安装ik分词器
一.概要: 1.es默认的分词器对中文支持不好,会分割成一个个的汉字.ik分词器对中文的支持要好一些,主要由两种模式:ik_smart和ik_max_word 2.环境 操作系统:centos es版 ...
- ElasticSearch6.5.0 【安装IK分词器】
不得不夸奖一下ES的周边资源,比如这个IK分词器,紧跟ES的版本,卢本伟牛逼!另外ES更新太快了吧,几乎不到半个月一个小版本就发布了!!目前已经发了6.5.2,估计我还没怎么玩就到7.0了. 下载 分 ...
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
随机推荐
- Java开发知识之Java面相对象
Java开发知识之Java面相对象上 一丶什么是面相对象 了解什么什么是面相对象.那么首先要了解什么是面相过程. 面相过程的意思就是. 什么事情都亲力亲为. 比如上一讲的排序算法. 我们自己写的. 这 ...
- linux下sh脚本/bin/bash^M问题解决
如果是在windows下编辑的脚本,到了linux下运行时会报出这样的错误/bin/bash^M:bad interpreter: No such file or directory这时因为编码的问题 ...
- 老代码多=过度耦合=if else?阿里巴巴工程师这样捋直老代码
简介 在业务开发的过程中,往往存在平台代码和业务代码耦合严重难以分离.业务和业务之间代码交织缺少拆解的现象.平台和业务代码交织导致不易修改,不同业务的代码交织增加了不同负责团队之间的协同成本.因此不论 ...
- 线程的私有领地 ThreadLocal
从名字上看,『ThreadLocal』可能会给你一种本地线程的概念印象,可能会让你联想到它是一个特殊的线程. 但实际上,『ThreadLocal』却营造了一种「线程本地变量」的概念,也就是说,同一个变 ...
- oracle数据库密码过期修改注意事项
近期的工作中,因数据库密码临近过期,需要进行修改,因对oracle数据库底层结构不了解,导致安装网上的教程操作是出现一些问题,特记录下来 传统的修改语句为 输入:win+R进入cmd 输入sqlpl ...
- 读书笔记--《Effective C#》总结
值得推荐的一本书,适合初中级C#开发人员 第1章 C#语言元素 原则1:尽可能的使用属性(property),而不是数据成员(field) ● 属性(property)一直是C#语言中比较有特点的存在 ...
- response.writeHead
response.writeHead(statusCode[, statusMessage][, headers]) 查看英文版 版本历史 statusCode <number> stat ...
- vue中使用Element主题自定义肤色
一.搭建好项目的环境. 二.根据ElementUI官网的自定义主题(http://element.eleme.io/#/zh-CN/component/custom-theme)来安装[主题生成工具] ...
- js中的new()到底做了些什么??
要创建 Person 的新实例,必须使用 new 操作符.以这种方式调用构造函数实际上会经历以下 4个步骤:(1) 创建一个新对象:(2) 将构造函数的作用域赋给新对象(因此 this 就指向了这个新 ...
- 后端开发者的Vue学习之路(二)
目录 上篇内容回顾: 数据绑定 表单输入框绑定 单行文本输入框 多行文本输入框 复选框checkbox 单选框radio 选择框select 数据绑定的修饰符 .lazy .number .trim ...