集成方法 Boosting原理
1.Boosting方法思路
Boosting方法通过将一系列的基本分类器组合,生成更好的强学习器
基本分类器是通过迭代生成的,每一轮的迭代,会使误分类点的权重增大

Boosting方法常用的算法是AdaBoost(Adaptive Boosting)、GBRT (Gradient Tree Boosting)
2.AdaBoost算法
算法要解决的2个问题(分类)
- 如何改变训练集的权值
提高前一轮分类错误样本的权值,降低分类正确样本的权值
- 如何将基本分类器组合成强学习器
加权多数表决法,通过投票来决定最后的结果,分类误差率小的基本分类器在投票中起较大作用,分类误差率大的基本分类器在投票中起较小作用。
算法思想
输入:训练集D;弱学习算法;训练轮数T
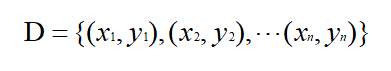
1)初始化权值分布D1(x) = 1/n
2)(for i=1;i<T;i++){
a.计算不同基本分类器G的分类误差率e,找到最小分类误差率ei;
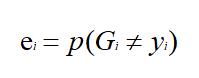
b.根据最小分类误差率ei,选择最小的基本分类器Gi
c.计算Gi的权值αi;
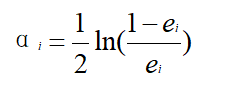
d.更新权值分布为Di+1(x);
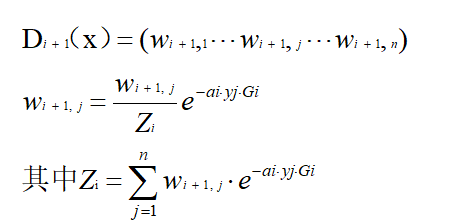
e.计算最终分类器G(x),并用G(x)分类,没有误分类点退出循环
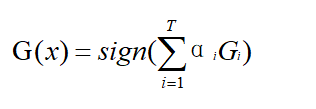
}
例子
例子来源于李航《统计学习方法》P140,数据表如下
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
首先是算法的输入,训练集D就是上边的表格,弱学习算法采用决策树桩(选一个数v,比v大的分一类,比v小的分一类),训练轮数输入5
1)初始化权值分布$D_1(x) =({1 \over 10},{1 \over 10},{1 \over 10},{1 \over 10},{1 \over 10},{1 \over 10},{1 \over 10},{1 \over 10},{1 \over 10},{1 \over 10})$
2)第一轮,i=1
a.由于弱学习算法是决策树桩,v可取的值为0.5,1.5,2.5,…,8.5
case1:当x<v时,y=1;x>v时,y=-1;
当v取0.5时,x=1,2,6,7,8,9分错类,故e = ${0.1*1+0.1*1+0.1*1+0.1*1+0.1*1} = 0.5$
同理可求v取1.5,2.5,…,8.5时的分类误差率,不同v求得的分类误差率如下
| 0.5 | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 |
| 0.5 | 0.4 | 0.3 | 0.4 | 0.5 | 0.6 | 0.5 | 0.4 | 0.3 |
当v=2.5时,x=6,7,8分错类,分类误差率最低为e1 = ${0.1*1+0.1*1+0.1*1} = 0.3$
case2:当x<v时,y=-1;x>v时,y=1;不同v求得的分类误差率如下
| 0.5 | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 |
| 0.5 | 0.6 | 0.7 | 0.6 | 0.5 | 0.4 | 0.5 | 0.6 | 0.7 |
b.因此可以得到基本分类器
$$G_1(x) = \begin{cases}1,&x<2.5\\-1,&x>2.5\end{cases}$$
c.计算G1(x)的权值α1
$$α_1 = {1 \over 2} ln {1- e_1 \over e_1} = 0.4236$$
d.更新权值分布为D2(x)
$$Z_1=0.1*e^{-0.4236*1*1}+0.1*e^{-0.4236*1*1}+...+0.1*e^{-0.4236*-1*-1}=0.7e^{-0.4236}+0.3e^{0.4236}$$
$$w_{21}={0.1e^{-0.4236} \over 0.7e^{-0.4236}+0.3e^{0.4236}} = 0.07143$$
同理可以计算其他w2j,最后得到更新后的权值分布D2,这个D2留着在下一轮用
$$D_2=(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,0.16667,0.16667,0.16667,0.07143)$$
e.计算第一轮最终分类器G(x)
$$G(x) =0.4236G_1(x) $$
用sign[G(x)]分类有x=6,7,8三个误分类点
第二轮,i=2
a.由于弱学习算法是决策树桩,v可取的值为0.5,1.5,2.5,…,8.5
case1:当x<v时,y=1;x>v时,y=-1;
| 0.5 | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 |
| 0.643 | 0.571 | 0.5 | 0.571 | 0.643 | 0.714 | 0.548 | 0.381 | 0.214 |
当v=8.5时,x=4,5,6分错类,分类误差率最低为e2 = ${0.07143*1+0.07143*1+0.07143*1} =0.2143$
case2:当x<v时,y=-1;x>v时,y=1;不同v求得的分类误差率如下
| 0.5 | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 |
| 0.357 | 0.429 | 0.5 | 0.429 | 0.357 | 0.286 | 0.452 | 0.619 | 0.786 |
b.因此可以得到基本分类器
$$G_2(x) = \begin{cases}1,&x<8.5\\-1,&x>8.5\end{cases}$$
c.计算G2(x)的权值α2
$$α_2 = {1 \over 2} ln {1- e_2 \over e_2} = 0.6496$$
d.更新权值分布为D3(x)
$$D_3=(0.0455,0.0455,0.0455,0.1667,0.1667,0.1667,0.1060,0.1060,0.1060,0.0455)$$
e.计算第二轮最终分类器G(x)
$$G(x) =0.4236G_1(x) + 0.6496G_2(x)$$
用sign[G(x)]分类有x=3,4,5三个误分类点
第三轮,i=3
a.由于弱学习算法是决策树桩,v可取的值为0.5,1.5,2.5,…,8.5
case1:当x<v时,y=1;x>v时,y=-1;
| 0.5 | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 |
| 0.409 | 0.364 | 0.318 | 0.485 | 0.652 | 0.818 | 0.712 | 0.606 | 0.5 |
case2:当x<v时,y=-1;x>v时,y=1;不同v求得的分类误差率如下
| 0.5 | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 |
| 0.591 | 0.636 | 0.682 | 0.515 | 0.348 | 0.182 | 0.288 | 0.394 | 0.5 |
当v=5.5时,x=0,1,2,9分错类,分类误差率最低为e3 = ${0.0455*1+0.0455*1+0.0455*+0.0455*1} =0.182$
b.因此可以得到基本分类器
$$G_3(x) = \begin{cases}-1,&x<5.5\\1,&x>5.5\end{cases}$$
c.计算G3(x)的权值α3
$$α_3 = {1 \over 2} ln {1- e_3 \over e_3} = 0.7514$$
d.更新权值分布为D4(x)
$$D_4=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)$$
e.计算第三轮最终分类器G(x)
$$G(x) =0.4236G_1(x) + 0.6496G_2(x)+0.7514G_3(x)$$
用sign[G(x)]分类有0个误分类点,故最终的分类器是
$$G(x) =0.4236G_1(x) + 0.6496G_2(x)+0.7514G_3(x)$$
集成方法 Boosting原理的更多相关文章
- 集成方法 Bagging原理
1.Bagging方法思路 Bagging独立的.并行的生成多个基本分类器,然后通过投票方式决定分类的类别 Bagging使用了自助法确定每个基本分类器的训练数据集,初始样本集中63.2%的数据会被采 ...
- 集成学习之Boosting —— Gradient Boosting原理
集成学习之Boosting -- AdaBoost原理 集成学习之Boosting -- AdaBoost实现 集成学习之Boosting -- Gradient Boosting原理 集成学习之Bo ...
- 常用的模型集成方法介绍:bagging、boosting 、stacking
本文介绍了集成学习的各种概念,并给出了一些必要的关键信息,以便读者能很好地理解和使用相关方法,并且能够在有需要的时候设计出合适的解决方案. 本文将讨论一些众所周知的概念,如自助法.自助聚合(baggi ...
- 【机器学习实战】第7章 集成方法 ensemble method
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGBT)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 决策树和基于决策树的集成方法(DT,RF,GBDT,XGB)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 内容: 1.算法概述 1.1 决策树(DT)是一种基本的分类和回归方法.在分类问题中它可以认为是if-the ...
- 集成学习方法Boosting和Bagging
集成学习是通过构架并结合多个学习器来处理学习任务的一种思想, 目前主要分为两大类:Boosting和Bagging. 对于任意一种集成方法, 我们都希望学习出来的基分类器具有较高的准确性和多样性, 基 ...
- SpringBoot集成MyBatis底层原理及简易实现
MyBatis是可以说是目前最主流的Spring持久层框架了,本文主要探讨SpringBoot集成MyBatis的底层原理.完整代码可移步Github. 如何使用MyBatis 一般情况下,我们在Sp ...
随机推荐
- linux性能监控命令(vmstat、sar、iostat、netstat)
1.常用系统命令Vmstat.sar.iostat.netstat.free.ps.top等 2.常用组合方式• 用vmstat.sar.iostat检测是否是CPU瓶颈• 用free.vmstat检 ...
- iOS 简易型标签的实现(UICollectionView)
https://blog.csdn.net/sinat_39362502/article/details/80900984 2018年07月03日 16:49:05 Recorder_MZou 阅读数 ...
- Kubernetes — 深入解析Pod对象:基本概念(一)
在上一篇文章中,我详细介绍了 Pod 这个 Kubernetes 项目中最重要的概念. 现在,你已经非常清楚:Pod,而不是容器,才是 Kubernetes 项目中的最小编排单位.将这个设计落实到 A ...
- 第二章· Redis管理实战
数据类型 管理实战 数据类型 String: 字符串类型 Hash: 哈希类型 List: 列表类型 Set: 集合类型 Sorted set: 顺序集合类型 管理实战 通用操作
- Android——分割线中夹文字
内容不多,只是感觉平时很容易遇上,那就做个笔记吧! 其实很简单,如下: <RelativeLayout android:layout_width="match_parent" ...
- angular4 数据绑定
HTML属性绑定 1.基本Html属性绑定 <td [attr.colspan]="tableColspan">something</td> 2.css类绑 ...
- ☆ [洛谷P2633] Count on a tree 「树上主席树」
题目类型:主席树+\(LCA\) 传送门:>Here< 题意:给出一棵树.每个节点有点权.问某一条路径上排名第\(K\)小的点权是多少 解题思路 类似区间第\(K\)小,但放在了树上. 考 ...
- ☆ [HNOI2012] 永无乡 「平衡树启发式合并」
题目类型:平衡树启发式合并 传送门:>Here< 题意:节点可以连边(不能断边),询问任意两个节点的连通性与一个连通块中排名第\(k\)的节点 解题思路 如果不需要询问排名,那么并查集即可 ...
- 51nod 1318 最大公约数与最小公倍数方程组(2-SAT)
题意 给你 \(n\) 个元素,\(m\) 个方程. 每个方程形如 \[ \begin{align} \gcd(x_i, y_i)=c_i\\ \mathrm{lcm}(x_i,y_i) = d_i ...
- Java【第一篇】基本语法之--关键字、标识符、变量
关键字 定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词)特点:关键字中所有字母都为小写 标识符 Java 对各种变量.方法和类等要素命名时使用的字符序列称为标识符凡是自己可以起名字的地 ...