初学Kafka工作原理流程介绍
Apache kafka 工作原理介绍
消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。在分布式计算环境中,为了集成分布式应用,开发者需要对异构网络环境下的分布式应用提供有效的通信手段。为了管理需要共享的信息,对应用提供公共的信息交换机制是重要的。常用的消息队列技术是 Message Queue。
Message Queue 的通讯模式
点对点通讯:点对点方式是最为传统和常见的通讯方式,它支持一对一、一对多、多对多、多对一等多种配置方式,支持树状、网状等多种拓扑结构。
多点广播:MQ 适用于不同类型的应用。其中重要的,也是正在发展中的是"多点广播"应用,即能够将消息发送到多个目标站点 (Destination List)。可以使用一条 MQ 指令将单一消息发送到多个目标站点,并确保为每一站点可靠地提供信息。MQ 不仅提供了多点广播的功能,而且还拥有智能消息分发功能,在将一条消息发送到同一系统上的多个用户时,MQ 将消息的一个复制版本和该系统上接收者的名单发送到目标 MQ 系统。目标 MQ 系统在本地复制这些消息,并将它们发送到名单上的队列,从而尽可能减少网络的传输量。
发布/订阅 (Publish/Subscribe) 模式:发布/订阅功能使消息的分发可以突破目的队列地理指向的限制,使消息按照特定的主题甚至内容进行分发,用户或应用程序可以根据主题或内容接收到所需要的消息。发布/订阅功能使得发送者和接收者之间的耦合关系变得更为松散,发送者不必关心接收者的目的地址,而接收者也不必关心消息的发送地址,而只是根据消息的主题进行消息的收发。
群集 (Cluster):为了简化点对点通讯模式中的系统配置,MQ 提供 Cluster(群集) 的解决方案。群集类似于一个域 (Domain),群集内部的队列管理器之间通讯时,不需要两两之间建立消息通道,而是采用群集 (Cluster) 通道与其它成员通讯,从而大大简化了系统配置。此外,群集中的队列管理器之间能够自动进行负载均衡,当某一队列管理器出现故障时,其它队列管理器可以接管它的工作,从而大大提高系统的高可靠性。
Kafka的基本术语和概念
- Kafka中有以下一些概念。
- Broker:任何正在运行中的Kafka示例都称为Broker。
- Topic:Topic其实就是一个传统意义上的消息队列。
- Partition:即分区。一个Topic将由多个分区组成,每个分区将存在独立的持久化文件,任何一个Consumer在分区上的消费一定是顺序的;当一个Consumer同时在多个分区上消费时,Kafka不能保证总体上的强顺序性(对于强顺序性的一个实现是Exclusive Consumer,即独占消费,一个队列同时只能被一个Consumer消费,并且从该消费开始消费某个消息到其确认才算消费完成,在此期间任何Consumer不能再消费)。
- Producer:消息的生产者。
- Consumer:消息的消费者。
- Consumer Group:即消费组。一个消费组是由一个或者多个Consumer组成的,对于同一个Topic,不同的消费组都将能消费到全量的消息,而同一个消费组中的Consumer将竞争每个消息(在多个Consumer消费同一个Topic时,Topic的任何一个分区将同时只能被一个Consumer消费)。
Kafka的特性
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作;
- 可扩展性:kafka集群支持热扩展;
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败);
- 高并发:支持数千个客户端同时读写;
- 支持实时在线处理和离线处理:可以使用Storm这种实时流处理系统对消息进行实时进行处理,同时还可以使用Hadoop这种批处理系统进行离线处理;
Kafka的Leader的选举机制
- Kafka的Leader是什么
- 首先Kafka会将接收到的消息分区(partition),每个主题(topic)的消息有不同的分区。这样一方面消息的存储就不会受到单一服务器存储空间大小的限制,另一方面消息的处理也可以在多个服务器上并行。
- 其次为了保证高可用,每个分区都会有一定数量的副本(replica)。这样如果有部分服务器不可用,副本所在的服务器就会接替上来,保证应用的持续性。
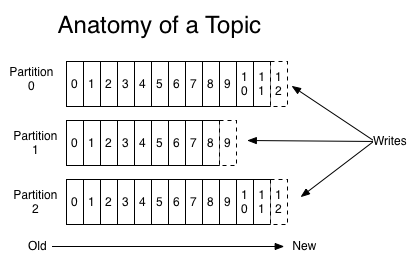
- 但是,为了保证较高的处理效率,消息的读写都是在固定的一个副本上完成。这个副本就是所谓的Leader,而其他副本则是Follower。而Follower则会定期地到Leader上同步数据。
- Leader选举
- 如果某个分区所在的服务器除了问题,不可用,kafka会从该分区的其他的副本中选择一个作为新的Leader。之后所有的读写就会转移到这个新的Leader上。现在的问题是应当选择哪个作为新的Leader。显然,只有那些跟Leader保持同步的Follower才应该被选作新的Leader。
- Kafka会在Zookeeper上针对每个Topic维护一个称为ISR(in-sync replica,已同步的副本)的集合,该集合中是一些分区的副本。只有当这些副本都跟Leader中的副本同步了之后,kafka才会认为消息已提交,并反馈给消息的生产者。如果这个集合有增减,kafka会更新zookeeper上的记录。
- 如果某个分区的Leader不可用,Kafka就会从ISR集合中选择一个副本作为新的Leader。
- 显然通过ISR,kafka需要的冗余度较低,可以容忍的失败数比较高。假设某个topic有f+1个副本,kafka可以容忍f个服务器不可用。
- 为什么不用少数服从多数的方法
- 少数服从多数是一种比较常见的一致性算法和Leader选举法。它的含义是只有超过半数的副本同步了,系统才会认为数据已同步;选择Leader时也是从超过半数的同步的副本中选择。这种算法需要较高的冗余度。譬如只允许一台机器失败,需要有三个副本;而如果只容忍两台机器失败,则需要五个副本。而kafka的ISR集合方法,分别只需要两个和三个副本。
- 如果所有的ISR副本都失败了怎么办
- 此时有两种方法可选,一种是等待ISR集合中的副本复活,一种是选择任何一个立即可用的副本,而这个副本不一定是在ISR集合中。这两种方法各有利弊,实际生产中按需选择。
- 如果要等待ISR副本复活,虽然可以保证一致性,但可能需要很长时间。而如果选择立即可用的副本,则很可能该副本并不一致。
kafka集群partition分布原理分析
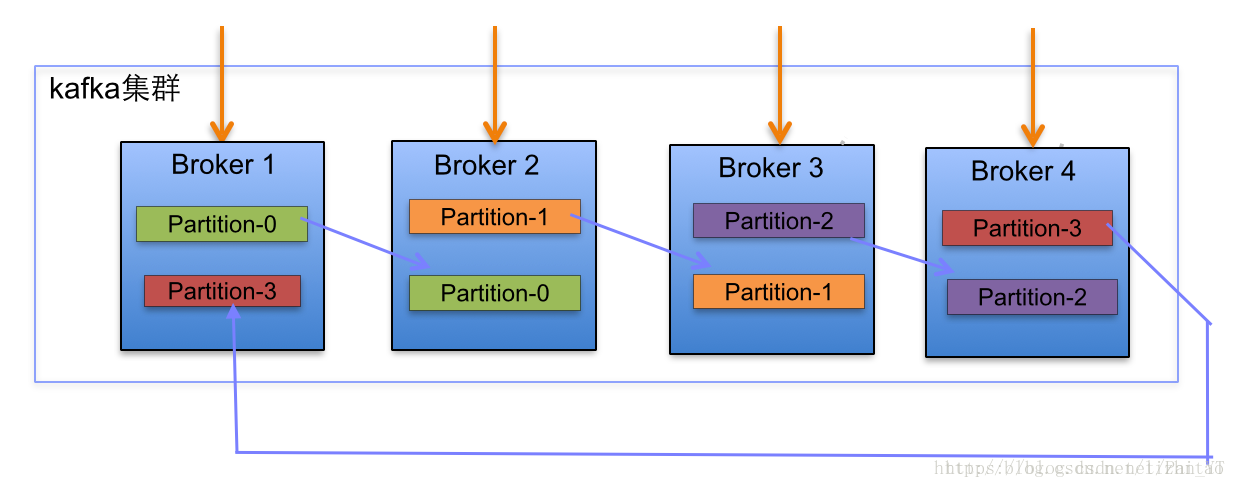
- 在Kafka集群中,每个Broker都有均等分配Partition的Leader机会。
- 上述图Broker Partition中,箭头指向为副本,以Partition-0为例:broker1中parition-0为Leader,Broker2中Partition-0为副本。
- 上述图种每个Broker(按照BrokerId有序)依次分配主Partition,下一个Broker为副本,如此循环迭代分配,多副本都遵循此规则。
- 副本分配算法如下:
- 将所有N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
Zookeeper在kafka的作用
- 无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。
- Kafka使用zookeeper作为其分布式协调框架,很好的将消息生产、消息存储、消息消费的过程结合在一起。
- 同时借助zookeeper,kafka能够生产者、消费者和broker在内的所以组件在无状态的情况下,建立起生产者和消费者的订阅关系,并实现生产者与消费者的负载均衡。
初学Kafka工作原理流程介绍的更多相关文章
- django+uWSGI+nginx的工作原理流程与部署过程
django+uWSGI+nginx的工作原理流程与部署过程 一.前言 知识的分享,不应该只是展示出来,还应该解释这样做是为什么... 献给和我一样懵懂中不断汲取知识,进步的人们. 授人与鱼,不如授人 ...
- HashMap工作原理的介绍!
HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间的区别,那么为何这道面试题如此 ...
- Apache kafka 工作原理介绍
消息队列 消息队列技术是分布式应用间交换信息的一种技术.消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走.通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置.或在继续执行 ...
- kafka工作原理介绍
两张图读懂kafka应用: Kafka 中的术语 broker:中间的kafka cluster,存储消息,是由多个server组成的集群. topic:kafka给消息提供的分类方式.brok ...
- kafka工作原理简介
消息队列 消息队列技术是分布式应用间交换信息的一种技术.消息队列可驻留在内存或磁盘上, 队列存储消息直到它们被应用程序读走.通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置.或在继续执行 ...
- MR1和MR2(Yarn)工作原理流程
一.Mapreduce1 图1 MR1工作原理图 工作流程主要分为以下6个步骤: 1 作业的提交 1)客户端向jobtracker请求一个新的作业ID(通过JobTracker的getNewJobI ...
- uWSGI+django+nginx 的工作原理流程与部署历程
一.前言 献给和我一样懵懂中不断汲取知识,进步的人们. 霓虹闪烁,但人们真正需要的,只是一个可以照亮前路的烛光 二.必要的前提 2.1 准备知识 django 一个基于python的开源web框架,请 ...
- uWSGI+django+nginx的工作原理流程与部署历程
一.前言献给和我一样懵懂中不断汲取知识,进步的人们. 霓虹闪烁,但人们真正需要的,只是一个可以照亮前路的烛光 二.必要的前提2.1 准备知识 django一个基于python的开源web框架,请确保自 ...
- kafka工作原理
https://blog.csdn.net/qq_29186199/article/details/80827085 https://www.jianshu.com/p/4bf007885116 ht ...
随机推荐
- 2018年Fintech金融科技关键词和入行互金从业必懂知识
2018年过去大半,诸多关键词进入眼帘: 5G,消费降级,数据裸奔,新零售,AI,物联网,云计算,合规监管,风控,割韭菜,区块链,生物识别,国民空闲时间以及金融科技. 这些词充斥着我们的生活和时间,而 ...
- 简单的SQL注入之2
Topic Link http://ctf5.shiyanbar.com/web/index_2.php 一.方法One sqlmap直接跑出来 1)暴库 2)爆表 3)爆段 4) 结果 二.方法Tw ...
- 补习系列(6)- springboot 整合 shiro 一指禅
目标 了解ApacheShiro是什么,能做什么: 通过QuickStart 代码领会 Shiro的关键概念: 能基于SpringBoot 整合Shiro 实现URL安全访问: 掌握基于注解的方法,以 ...
- 图解ARP协议(三)ARP防御篇-如何揪出“内鬼”并“优雅的还手”
一.ARP防御概述 通过之前的文章,我们已经了解了ARP攻击的危害,黑客采用ARP软件进行扫描并发送欺骗应答,同处一个局域网的普通用户就可能遭受断网攻击.流量被限.账号被窃的危险.由于攻击门槛非常低, ...
- Nginx的负载均衡
什么是负载均衡 负载均衡主要通过专门的硬件设备或者通过软件算法实现.通过硬件设备实现的负载均衡效果好.效率高.性能稳定,但是成本比较高.通过软件实现的负载均衡主要依赖于均衡算法的选择和程序的健壮性.均 ...
- Python3+Selenium2完整的自动化测试实现之旅(五):自动化测试框架、Python面向对象以及POM设计模型简介
前言 之前的系列博客,陆续学习整理了自动化测试环境的搭建.IE和Chrome浏览器驱动的配置.selenium-webdriver模块封装的元素定位以及控制浏览器.处理警示框.鼠标键盘等方法的使用,这 ...
- Puppet部署Nginx返代示例
一.创建目录并编辑Nginx安装模块 mkdir -pv /etc/puppet/modules/nginx/{manifests,files,templates,spec,tests,lib} ]# ...
- percona-toolkit 之 【pt-archiver】
背景: 工作上需要删除或则归档一张大表,这时候用pt-archiver可以很好的满足要求,其不仅可以归档数据,还有删除.导出到文件等功能.并且在主从架构当中,可以兼顾从库(一个或则多个)进行归档,避免 ...
- jstat命令查看jvm的GC情况 (以Linux为例)
jstat命令可以查看堆内存各部分的使用量,以及加载类的数量.命令的格式如下: jstat [-命令选项] [vmid] [间隔时间/毫秒] [查询次数] 注意!!!:使用的jdk版本是jdk8. ...
- 【转】Android开发笔记(序)写在前面的目录
原文:http://blog.csdn.net/aqi00/article/details/50012511 知识点分类 一方面写写自己走过的弯路掉进去的坑,避免以后再犯:另一方面希望通过分享自己的经 ...