Redis学习笔记(4)——Redis五大数据结构介绍以及应用场景
出处:https://www.jianshu.com/p/f09480c05e42
Redis是典型的Key-Value类型数据库,Key为字符类型,Value的类型常用的为五种类型:String、Hash 、List 、 Set 、 Ordered Set下面我们详细介绍一下。
一、Redis的内部内存管理原理
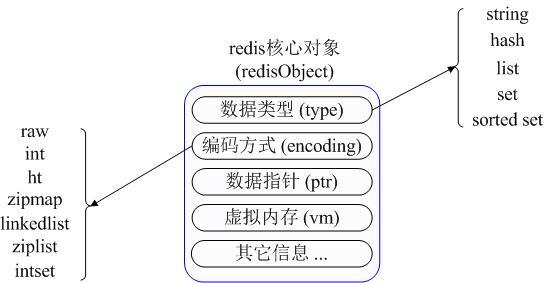
1、Redis 内部使用一个 redisObject 对象来表示所有的 key 和 value。
2、type :代表一个 value 对象具体是何种数据类型。
3、encoding :是不同数据类型在 redis 内部的存储方式,比如:type=string 代表 value 存储的是一个普通字符串,那么对应的 encoding 可以是 raw 或者是 int,如果是 int 则代表实际 redis 内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
4、vm 字段:只有打开了 Redis 的虚拟内存功能,此字段才会真正的分配内存,该功能默认是关闭状态的。 Redis 使用 redisObject 来表示所有的 key/value 数据是比较浪费内存的,当然这些内存管理成本的付出主要也是为了给 Redis 不同数据类型提供一个统一的管理接口,实际作者也提供了多种方法帮助我们尽量节省内存使用。
1、String(字符串类型的Value)
可以是String,也可是是任意的byte[]类型的数组,如图片等。String 在 redis 内部存储默认就是一个字符串,被 redisObject 所引用,当遇到 incr,decr 等操作时会转成数值型进行计算,此时 redisObject 的 encoding 字段为int。
1.1、大小限制:最大为512Mb,基本可以存储任意图片啦。常用命令的时间复杂度为O(1),读写一样的快。常用命令:get、set、incr、decr、mget等,参照Redis常用命令中文版http://doc.redisfans.com/string/index.html。
1.2、应用场景:String是最常用的一种数据类型,普通的key/ value 存储都可以归为此类,即可以完全实现目前 Memcached 的功能,并且效率更高。还可以享受Redis的定时持久化,操作日志及 Replication等功能。除了提供与 Memcached 一样的get、set、incr、decr 等操作外,Redis还提供了下面一些操作:
- 获取字符串长度
- 往字符串append内容
- 设置和获取字符串的某一段内容
- 设置及获取字符串的某一位(bit)
- 批量设置一系列字符串的内容
1.3、使用场景:常规key-value缓存应用。常规计数: 微博数, 粉丝数。
2 、Hash(HashMap,哈希映射表)
Redis 的 Hash 实际是内部存储的 Value 为一个 HashMap,并提供了直接存取这个 Map 成员的接口。Hash将对象的各个属性存入Map里,可以只读取/更新对象的某些属性。另外不同的模块可以只更新自己关心的属性而不会互相并发覆盖冲突。
不同程序通过 key(用户 ID) + field(属性标签)就可以并发操作各自关心的属性数据

2.1、实现原理:Redis Hash 对应 Value 内部实际就是一个 HashMap,实际这里会有2种不同实现,** 这个 Hash 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的 HashMap 结构,对应的 value redisObject 的 encoding 为 zipmap,当成员数量增大时会自动转成真正的 HashMap,此时 encoding 为 ht**。一般操作复杂度是O(1),要同时操作多个field时就是O(N),N是field的数量。
2.2、使用场景:存储部分变更数据,如用户信息等。
2.3、常用操作:
- O(1)操作:hget、hset等等
- O(n)操作:hgetallRedis 可以直接取到全部的属性数据,但是如果内部 Map 的成员很多,那么涉及到遍历整个内部 Map 的操作,由于 Redis 单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。


3、 List(双向链表)
Redis list 的应用场景非常多,也是 Redis 最重要的数据结构之一,比如 twitter 的关注列表,粉丝列表等都可以用 Redis 的 list 结构来实现,还提供了生产者消费者阻塞模式(B开头的命令),常用于任务队列,消息队列等。
3.1、实现方式:Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
用作消息队列中防止数据丢失的解决方法
3.2、用作消息队列中放置数据丢失的解决方法
如果消费者把job给Pop走了又没处理完就死机了怎么办?
3.2.1 消息生产者保证不丢失
加多一个sorted set,分发的时候同时发到list与sorted set,以分发时间为score,用户把job做完了之后要用ZREM消掉sorted set里的job,并且定时从sorted set中取出超时没有完成的任务,重新放回list。 如果发生重复可以在sorted set中在查询确认一遍,或者将消息的消费接口设计成幂等性。
3.2.2消息消费者保证不丢失
为每个worker多加一个的list,弹出任务时改用RPopLPush,将job同时放到worker自己的list中,完成时用LREM消掉。如果集群管理(如zookeeper)发现worker已经挂掉,就将worker的list内容重新放回主list
3.3、常用操作
3.3.1、复合操作:RPopLPush/ BRPopLPush,弹出来返回给client的同时,把自己又推入另一个list,是原子操作。

- 3.3.2、
按值进行的操作:LRem(按值删除元素)、LInsert(插在某个值的元素的前后),复杂度是O(N),N是List长度,因为List的值不唯一,所以要遍历全部元素,而Set只要O(log(N))。

4、 set(HashSet)
Set就是HashSet,可以将重复的元素随便放入而Set会自动去重,底层实现也是HashMap,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。
4.1、实现原理
set 的内部实现是一个 value 永远为 null 的 HashMap,实际就是通过计算 hash 的方式来快速排重的,这也是 set 能提供判断一个成员是否在集合内的原因。
4.2、常见操作
增删改查:SAdd/SRem/SIsMember/SCard/SMove/SMembers等等。除了SMembers都是O(1)。
集合操作:SInter/SInterStore/SUnion/SUnionStore/SDiff/SDiffStore,各种集合操作。交集运算可以用来显示在线好友(在线用户 交集 好友列表),共同关注(两个用户的关注列表的交集)。O(N),并集和差集的N是集合大小之和,交集的N是小的那个集合的大小的2倍。
5、 Sorted Set(插入有序Set集合)
set 不是自动有序的,而** sorted set 可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序**。当你需要一个有序的并且不重复的集合列表,那么可以选择 sorted set 数据结构,比如 twitter 的 public timeline 可以以发表时间作为 score 来存储,这样获取时就是自动按时间排好序的。
5.1实现方式
内部使用 HashMap 和跳跃表(SkipList)来保证数据的存储和有序
Sorted Set的实现是HashMap(element->score, 用于实现ZScore及判断element是否在集合内),和SkipList(score->element,按score排序)的混合体。SkipList有点像平衡二叉树那样,不同范围的score被分成一层一层,每层是一个按score排序的链表。
5.2、常用操作
ZAdd/ZRem是O(log(N));ZRangeByScore/ZRemRangeByScore是O(log(N)+M),N是Set大小,M是结果/操作元素的个数。复杂度的log取对数很关键,可以使,1000万大小的Set,复杂度也只是几十不到。但是,如果一次命中很多元素M很大则复杂度很高。
ZRange/ZRevRange,按排序结果的范围返回元素列表,可以为正数与倒数。
ZRangeByScore/ZRevRangeByScore,按score的范围返回元素,可以为正数与倒数。
ZRemRangeByRank/ZRemRangeByScore,按排序/按score的范围限删除元素。
ZCount,统计按score的范围的元素个数。
ZRank/ZRevRank ,显示某个元素的正/倒序的排名。
ZScore/ZIncrby,显示元素的Score值/增加元素的Score。
ZAdd(Add)/ZRem(Remove)/ZCard(Count),ZInsertStore(交集)/ZUnionStore(并集),与Set相比,少了IsMember和差集运算。
6、 Redis使用与内存优化
上面的一些实现上的分析可以看出 redis 实际上的内存管理成本非常高,即占用了过多的内存,属于用空间换时间。作者对这点也非常清楚,所以提供了一系列的参数和手段来控制和节省内存
建议不要开启VM(虚拟内存)选项
VM 选项是作为 Redis 存储超出物理内存数据的一种数据在内存与磁盘换入换出的一个持久化策略,将严重地拖垮系统的运行速度,所以要关闭 VM 功能,请检查你的 redis.conf 文件中 vm-enabled 为 no。
设置最大内存选项
最好设置下 redis.conf 中的 maxmemory 选项,该选项是告诉 Redis 当使用了多少物理内存后就开始拒绝后续的写入请求,该参数能很好的保护好你的 Redis 不会因为使用了过多的物理内存而导致 swap,最终严重影响性能甚至崩溃。
一般还需要设置内存饱和回收策略
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
Redis学习笔记(4)——Redis五大数据结构介绍以及应用场景的更多相关文章
- Redis学习笔记之Redis中5种数据结构的使用场景介绍
原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 redis 中一共有5种数据结构 ...
- Redis学习笔记之Redis基本数据结构
Redis基础数据结构 Redis有5种基本数据结构:String(字符串).list(列表).set(集合).hash(哈希).zset(有序集合) 字符串string 字符串类型是Redis的va ...
- Redis学习笔记(1) Redis介绍及基础
1. Redis的特性 (1) 存储结构 Redis(Remote Dictionary Server,远程字典服务器)是以字典结构存储数据,并允许其他应用通过TCP协议读写字典中的内容.Redis支 ...
- Redis学习笔记之Redis单机,伪集群,Sentinel主从复制的安装和配置
0x00 Redis简介 Redis是一款开源的.高性能的键-值存储(key-value store).它常被称作是一款数据结构服务器(data structure server). Redis的键值 ...
- Redis学习笔记(4) Redis事务、生存时间及排序
1. Redis事务 Redis中的事务(transaction)是一组命令的集合,一个事务中的命令要么都执行,要么都不执行.事务的原理是先将属于一个事务的命令发送给Redis,然后再让Redis依次 ...
- redis学习笔记之redis简介
redis简介 Redis是一个开源的,高性能的,基于键值对的缓存与存储系统,通过设置各种键值数据类型来适应不同场景下的缓存与存储需求.同事redis的诸多高层级功能使其可以胜任消息队列,任务队列等不 ...
- StackExchange.Redis学习笔记(一) Redis的使用初探
Redis Redis将其数据库完全保存在内存中,仅使用磁盘进行持久化. 与其它键值数据存储相比,Redis有一组相对丰富的数据类型. Redis可以将数据复制到任意数量的从机中 Redis的安装 官 ...
- Redis学习笔记(一):基础数据结构
一. 引言 <Redis设计与实现>一书主要分为四个部分,其中第一个部分主要讲的是Redis的底层数据结构与对象的相关知识. Redis是一种基于C语言编写的非关系型数据库,它的五种基本对 ...
- Redis学习笔记(七)——数据结构之有序集合(sorted set)
一.介绍 Redis有序集合和集合一样都是string类型元素的机会,且不允许重复的成员. 不同的是每个元素都会关联一个double类型的分数.Redis正是通过分数来为集合中的成员进行从小到放大的排 ...
随机推荐
- 玩转C线性表和单向链表之Linux双向链表优化
前言: 这次介绍基本数据结构的线性表和链表,并用C语言进行编写:建议最开始学数据结构时,用C语言:像栈和队列都可以用这两种数据结构来实现. 一.线性表基本介绍 1 概念: 线性表也就是关系户中最简单的 ...
- Django中的模板渲染是什么
首先建立一个页面 在views.py中增加一个方法 配置URL 如何实现的呢 这就是渲染,传递的数据不同显示的数据也不同.Django里的渲染引擎和Jinja的虽然不同但是语法基本通用.现在明白什么叫 ...
- Chapter 4 Invitations——23
The next morning, when I pulled into the parking lot, I deliberately parked as far as possible from ...
- JSP面试题都在这里
下面是我整理下来的JSP知识点: 图上的知识点都可以在我其他的文章内找到相应内容. JSP常见面试题 jsp静态包含和动态包含的区别 jsp静态包含和动态包含的区别 在讲解request对象的时候,我 ...
- 如何优雅地查看 JS 错误堆栈?
本文由云+社区发表 在前端,我们经常会通过 window.onerror 事件来捕获未处理的异常.假设捕获了一个异常,上报的堆栈是这个: TypeError: Cannot read property ...
- NFS的安装
NFS的安装鸟哥地址:http://vbird.dic.ksu.edu.tw/linux_server/0330nfs_2.php 13.2 NFS Server 端的设定 既然要使用 NFS 的话, ...
- Docker最全教程——从理论到实战(六)
托管到腾讯云容器服务 托管到腾讯云容器服务,我们的公众号“magiccodes”已经发布了相关的录屏教程,大家可以结合本篇教程一起查阅. 自建还是托管? 在开始之前,我们先来讨论一个问题——是自建 ...
- 计算机网络通信TCP/IP协议浅析 网络发展简介(二)
本文对计算机网络通信的原理进行简单的介绍 首先从网络协议分层的概念进行介绍,然后对TCP.IP协议族进行了概念讲解,然后对操作系统关于通信抽象模型进行了简单介绍,最后简单描述了socket 分层的 ...
- 第一个Mybatis程序示例 Mybatis简介(一)
在JDBC小结中(可以参阅本人JDBC系列文章),介绍到了ORM,其中Mybatis就是一个不错的ORM框架 MyBatis由iBatis演化而来 iBATIS一词来源于“internet”和“aba ...
- Java并发专题(一)认识线程
1.1 认识线程 线程是轻量级进程,也是程序执行的一个路径,每一个线程都有自己的局部变量表.程序计数器(指向正在执行的指令指针)以及各自的生命周期,现代操作系统中一般不止一个线程在运行.比如说,当我们 ...