目标检测方法——R-FCN
R-FCN论文阅读(R-FCN: Object Detection via Region-based Fully Convolutional Networks )
目录
- 作者及相关链接
- 方法概括
- 方法细节
- 实验结果
- 总结
- 参考文献
作者及相关链接
- 作者:
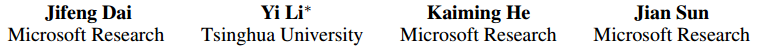
方法概括
R-FCN解决问题——目标检测
整个R-FCN的结构
- 一个base的conv网络如ResNet101, 一个RPN(Faster RCNN来的),一个position sensitive的prediction层,最后的ROI pooling+投票的决策层
R-FCN的idea出发点(关键思想)
- 分类需要特征具有平移不变性,检测则要求对目标的平移做出准确响应。现在的大部分CNN在分类上可以做的很好,但用在检测上效果不佳。SPP,Faster R-CNN类的方法在ROI pooling前都是卷积,是具备平移不变性的,但一旦插入ROI pooling之后,后面的网络结构就不再具备平移不变性了。因此,本文想提出来的position sensitive score map这个概念是能把目标的位置信息融合进ROI pooling。


- 对于region-based的检测方法,以Faster R-CNN为例,实际上是分成了几个subnetwork,第一个用来在整张图上做比较耗时的conv,这些操作与region无关,是计算共享的。第二个subnetwork是用来产生候选的boundingbox(如RPN),第三个subnetwork用来分类或进一步对box进行regression(如Fast RCNN),这个subnetwork和region是有关系的,必须每个region单独跑网络,衔接在这个subnetwork和前两个subnetwork中间的就是ROI pooling。我们希望的是,耗时的卷积都尽量移到前面共享的subnetwork上。因此,和Faster RCNN中用的ResNet(前91层共享,插入ROI pooling,后10层不共享)策略不同,本文把所有的101层都放在了前面共享的subnetwork。最后用来prediction的卷积只有1层,大大减少了计算量。

方法细节
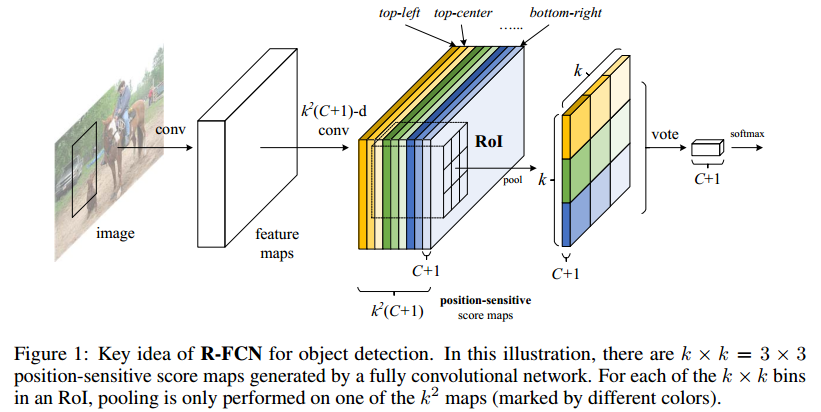
- Backbone architecture: ResNet 101——去掉原始ResNet101的最后一层全连接层,保留前100层,再接一个1*1*1024的全卷积层(100层输出是2048,为了降维,再引入了一个1*1的卷积层)。
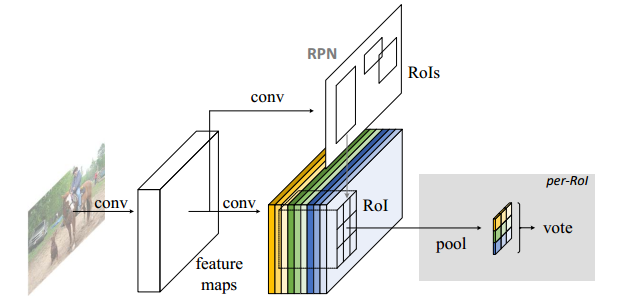
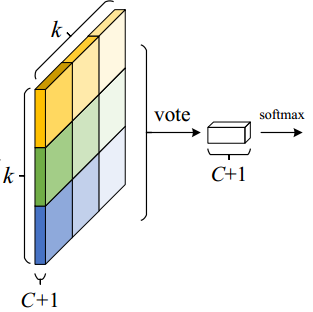
- k^2(C+1)的conv: ResNet101的输出是W*H*1024,用K^2(C+1)个1024*1*1的卷积核去卷积即可得到K^2(C+1)个大小为W*H的position sensitive的score map。这步的卷积操作就是在做prediction。k = 3,表示把一个ROI划分成3*3,对应的9个位置分别是:上左(左上角),上中,上右,中左,中中,中右,下左,下中,下右(右下角),如图Figuire 3。


- k^2(C+1)个feature map的物理意义: 共有k*k = 9个颜色,每个颜色的立体块(W*H*(C+1))表示的是不同位置存在目标的概率值(第一块黄色表示的是左上角位置,最后一块淡蓝色表示的是右下角位置)。共有k^2*(C+1)个feature map。每个feature map,z(i,j,c)是第i+k(j-1)个立体块上的第c个map(1<= i,j <=3)。(i,j)决定了9种位置的某一种位置,假设为左上角位置(i=j=1),c决定了哪一类,假设为person类。在z(i,j,c)这个feature map上的某一个像素的位置是(x,y),像素值是value,则value表示的是原图对应的(x,y)这个位置上可能是人(c=‘person’)且是人的左上部位(i=j=1)的概率值。
- ROI pooling: 就是faster RCNN中的ROI pooling,也就是一层的SPP结构。主要用来将不同大小的ROI对应的feature map映射成同样维度的特征,思路是不论对多大的ROI,规定在上面画一个n*n 个bin的网格,每个网格里的所有像素值做一个pooling(平均),这样不论图像多大,pooling后的ROI特征维度都是n*n。注意一点ROI pooling是每个feature map单独做,不是多个channel一起的。
- ROI pooling的输入和输出:ROI pooling操作的输入(对于C+1个类)是k^2*(C+1)*W' *H'(W'和H'是ROI的宽度和高度)的score map上某ROI对应的那个立体块,且该立体块组成一个新的k^2*(C+1)*W' *H'的立体块:每个颜色的立体块(C+1)都只抠出对应位置的一个bin,把这k*k个bin组成新的立体块,大小为(C+1)*W'*H'。例如,下图中的第一块黄色只取左上角的bin,最后一块淡蓝色只取右下角的bin。所有的bin重新组合后就变成了类似右图的那个薄的立体块(图中的这个是池化后的输出,即每个面上的每个bin上已经是一个像素。池化前这个bin对应的是一个区域,是多个像素)。ROI pooling的输出为为一个(C+1)*k*k的立体块,如下图中的右图。更详细的有关ROI pooling的操作如公式(1)所示:
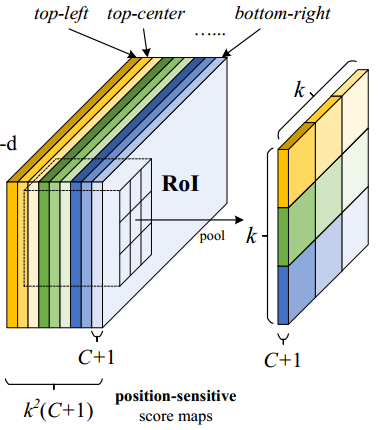

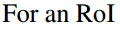

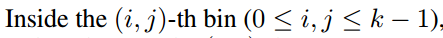
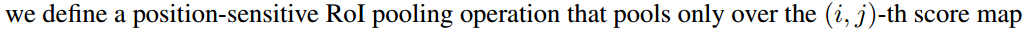
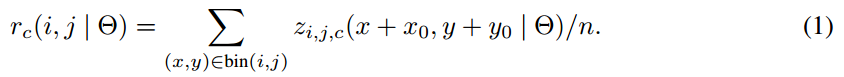
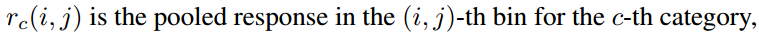

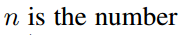
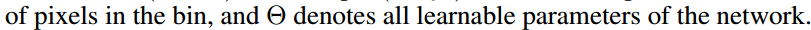
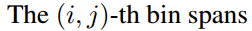
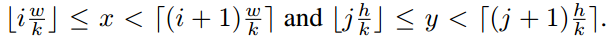
- vote投票:k*k个bin直接进行求和(每个类单独做)得到每一类的score,并进行softmax得到每类的最终得分,并用于计算损失
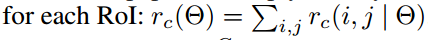

- 损失函数:和faster RCNN类似,由分类loss和回归loss组成,分类用交叉熵损失(log loss),回归用L1-smooth损失

- 训练的样本选择策略:online hard example mining (OHEM,参考文献1) 。主要思想就是对样本按loss进行排序,选择前面loss较小的,这个策略主要用来对负样本进行筛选,使得正负样本更加平衡。
- 训练细节:
- decay = 0.0005
- momentum = 0.9
- single-scale training: images are resized such that the scale (shorter side of image) is 600 pixels [6, 18].
- 8 GPUs (so the effective mini-batch size is 8×), each GPU holds 1 image and selects B = 128 RoIs for backprop.
- fine-tune learning rate = 0.001 for 20k mini-batches, 0.0001 for 10k mini-batches on VOC.
- the 4-step alternating training between training RPN and training R-FCN.(类似于Faster RCNN)
- 使用atrous(hole算法)

实验结果
VOC2007和VOC2010上与Faster R-CNN的对比:R-FCN比Faster RCNN好!



深度影响对比:101深度最好!

候选区域选择算法对比:RPN比SS,EB好!

COCO库上与Faster R-CNN的对比:R-FCN比Faster RCNN好!

效果示例:

总结
- R-FCN是在Faster R-CNN的框架上进行改造,第一,把base的VGG16换车了ResNet,第二,把Fast R-CNN换成了先用卷积做prediction,再进行ROI pooling。由于ROI pooling会丢失位置信息,故在pooling前加入位置信息,即指定不同score map是负责检测目标的不同位置。pooling后把不同位置得到的score map进行组合就能复现原来的位置信息。
参考文献
- A. Shrivastava, A. Gupta, and R. Girshick. Training region-based object detectors with online hard example mining. In CVPR, 2016.
目标检测方法——R-FCN的更多相关文章
- 目标检测方法总结(R-CNN系列)
目标检测方法系列--R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD 目录 相关背景 从传统方法到R-CNN 从R-CNN到SPP Fast R-CNN ...
- CVPR2019目标检测方法进展综述
CVPR2019目标检测方法进展综述 置顶 2019年03月20日 14:14:04 SIGAI_csdn 阅读数 5869更多 分类专栏: 机器学习 人工智能 AI SIGAI 版权声明:本文为 ...
- 目标检测方法——SSD
SSD论文阅读(Wei Liu--[ECCV2016]SSD Single Shot MultiBox Detector) 目录 作者及相关链接 文章的选择原因 方法概括 方法细节 相关背景补充 实验 ...
- 【目标检测】基于传统算法的目标检测方法总结概述 Viola-Jones | HOG+SVM | DPM | NMS
"目标检测"是当前计算机视觉和机器学习领域的研究热点.从Viola-Jones Detector.DPM等冷兵器时代的智慧到当今RCNN.YOLO等深度学习土壤孕育下的GPU暴力美 ...
- 不带Anchors和NMS的目标检测
前言: 目标检测是计算机视觉中的一项传统任务.自2015年以来,人们倾向于使用现代深度学习技术来提高目标检测的性能.虽然模型的准确性越来越高,但模型的复杂性也增加了,主要是由于在训练和NMS后处理过 ...
- 第十八节、基于传统图像处理的目标检测与识别(HOG+SVM附代码)
其实在深度学习中我们已经介绍了目标检测和目标识别的概念.为了照顾一些没有学过深度学习的童鞋,这里我重新说明一次:目标检测是用来确定图像上某个区域是否有我们要识别的对象,目标识别是用来判断图片上这个对象 ...
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD, R-FCN系列深度学习检测方法梳理
1. R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation 技术路线:selec ...
- 目标检测算法(1)目标检测中的问题描述和R-CNN算法
目标检测(object detection)是计算机视觉中非常具有挑战性的一项工作,一方面它是其他很多后续视觉任务的基础,另一方面目标检测不仅需要预测区域,还要进行分类,因此问题更加复杂.最近的5年使 ...
- 第三十五节,目标检测之YOLO算法详解
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object de ...
随机推荐
- java动态代理实现与原理详细分析
关于Java中的动态代理,我们首先需要了解的是一种常用的设计模式--代理模式,而对于代理,根据创建代理类的时间点,又可以分为静态代理和动态代理. 一.代理模式 代理模式是常用的java设计模式, ...
- Centos7安装InfluxDB1.7
Centos7安装InfluxDB1.7 本操作参照InfluxDB官网:InfuxDB 使用的Red Hat和CentOS用户可以安装InfluxDB最新的稳定版本 yum包管理器: cat < ...
- linux(debian) arm-linux-g++ v4.5.1交叉编译 embedded arm 版本的QtWebkit (browser) 使用qt 4.8.6 版本 以及x64上编译qt
最近需要做一个项目 在arm 架构的linux下 没有桌面环境的情况下拉起 有界面的浏览器使用. 考虑用qt 的界面和 qtwebikt 的库去实现这一系列操作. 本文参考: Qt移植到ARM Lin ...
- HTML5:离线存储
最近由于找工作一直没时间也没有精力更新博客,找工作真是一件苦逼的事情啊...不抱怨了,我们来看看HTML5的新特性---离线存储吧. 随着Web App的发展,越来越多的移动端App使用HTML5的方 ...
- mobile_轮播图_transform 版本_transform 读写二合一
轮播图_transform 版本 关键点: 2D 变换 transform 不会改变 元素 在 文档流 中的位置 定位 position 会改变 元素 在 文档流 中的位置 语句解析太快,使用 set ...
- Spring Boot @EnableWebMvc 与 mvc 配置
注意: 1.小心使用 @EnableWebMvc 注解 根据官方文档,尽量不要使用 @EnableWebMvc 注解,因为它会关闭默认配置. ① 你希望关闭默认配置,自己完全重新实现一个 @Enab ...
- 变量类型-Tuple
教程:一:元组的创建 元组(tuple)与列表类似,不同之处在于元组的元素不能修改 (1)tuple写在圆括号之间,元素用逗号隔开 (2)元组元素的类型可以不同 (3) ...
- 十四、JavaWeb监听器
JavaWeb监听器 三大组件: l Servlet l Listener l Filter Listener:监听器 初次相见:AWT 二次相见:SAX 监听器: l 它是一个接口,内容由我们来实现 ...
- myeclipse连接mysql失败出错,已解决问题
问题描述: 解决方案:
- Javascript获取服务器时间
//获取服务器时间 var getServerDate = function () { var xmlHttpRequest = null, serverDate = new Date ...