D3算法编写决策树
前言
所谓构建决策树,
就是递归的对数据集参数进行“最优特征”的选择。然后按最优特征分类成各个子数据集,继续递归。
最优特征的选择:依次计算按照各个特征进行分类以后数据集的熵,各个子数据集的熵比较后,其中拥有最小的熵的数据集就是最优的分类结果,此次分类的特征就是最优特征。
熵的计算:熵计算的是数据集的纯净程度,数据集的熵的大小只和数据集中各数据样本的最终分类结果的分布有关。假设数据集中所有数据都是“同一种类”的数据,那么其熵就是0,表示是最纯净的数据。
(所以最优特征的选择就变成了,先计算分类前的数据集的熵,再计算按某种特征分类后其各个子数据集的熵的期望,然后取原数据集熵与分类后的熵期望之差作为评价分类效果的标准。)
(此处之所以计算分类后所有子数据集的熵的期望其实很好理解。期望也可以看成一堆离散数据的平均值,假设我们把原数据集分成了三堆子数据集,这三堆子数据集哪一堆也不能代表分类后的结果,只有三堆总结果再求个期望也就是三堆的平均值,才能代表分类后的结果)

熵的计算
我们用数据集中各结果分类出现的概率来作为计算熵的决定因素。
假设整个样本数据集中样本都有着“统一的分类结果”时,出现该分类结果的概率是100%,其熵就是0。
而如果数据集中有10个样本,每个样本都有一个独立的结果分类,那么出现每一种结果的概率都是10%,这种结果的不确定性自然要比上一个大(上一个可是100%的确定结果),其最终熵值肯定也要更大。
至此我们可以看出,我们需要找到一个函数能把事件出现的概率映射成熵值。
这个函数就是以下这个函数

其函数图像为
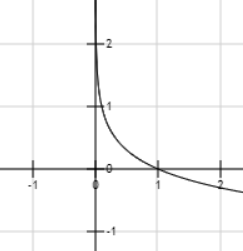
x轴是事件出现的概率
y轴是熵的值
通过图像我们可以看出随着事件出现的概率越来越大,熵也越来越小,直至到0。
假设数据集中一共有出现三种分类结果的可能,该数据集的熵自然是算出这三种分类结果的熵后在求其三者的期望,使用期望作为该数据集的熵。
python代码实现如下:
from math import log """
数据集,
二维数组中的前三个元素都是特征,
最后一个元素是样本的分类结果。
"""
data = [["有眼镜", "短发", "胖", "男"],
["有眼镜", "长发", "瘦", "女"],
["有眼镜", "短发", "胖", "女"],
["没眼镜", "长发", "胖", "男"],
["没眼镜", "短发", "瘦", "男"]] """
data:需要计算熵的数据集
return:该数据集的熵 计算数据集的熵
"""
def calcShannon(data):
# 熵
shannonMean = 0
# 数据总量
sumDataNum = len(data)
# 数据集的所有分类情况
classify = [man[-1] for man in data]
# 循环每一种分类结果,计算该分类结果的熵,并求期望
for resClassify in set(classify):
# 该分类结果的“发生”概率
p = classify.count(resClassify) / sumDataNum
# 计算该分类结果的熵
shannon = -log(p, 2)
# 求期望
shannonMean += p * shannon
return shannonMean print(calcShannon(data))
构建决策树
我们的最终目的是要构建出下图结构的决策树。
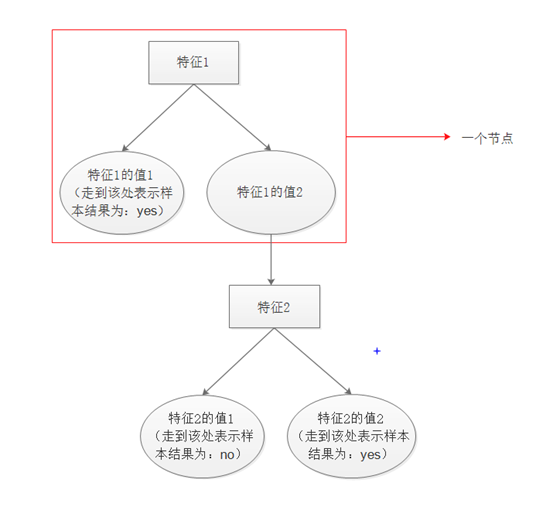
上图转换成python字典数据格式为:
{特征1:{值1:yes,值2:{特征2:{值1:no,值2:yes}}}}
完整python代码如下:
from math import log """
数据集,
二维数组中的前三个元素都是特征,
最后一个元素是样本的分类结果。
"""
data = [["有眼镜", "短发", "胖", "男"],
["有眼镜", "长发", "瘦", "女"],
["有眼镜", "短发", "胖", "女"],
["没眼镜", "长发", "胖", "男"],
["没眼镜", "短发", "瘦", "男"],
["有眼镜", "长发", "瘦", "女"],
["有眼镜", "长发", "胖", "男"]] """
样本参数中各个特征的描述信息
"""
labels = ["是否戴眼镜", "头发长短", "身材"] """
计算数据集的熵 data:需要计算熵的数据集 return:该数据集的熵
"""
def calcShannon(data):
# 熵
shannonMean = 0
# 数据总量
sumDataNum = len(data)
# 数据集的所有分类情况
classify = [man[-1] for man in data]
# 循环每一种分类结果,计算该分类结果的熵,并求期望
for resClassify in set(classify):
# 该分类结果的“发生”概率
p = classify.count(resClassify) / sumDataNum
# 计算该分类结果的熵
shannon = -log(p, 2)
# 求期望
shannonMean += p * shannon
return shannonMean """
统计分类数组中出现最多的项,并返回该项的值
"""
def statisticsMostClassify(classify):
map = {}
for resClassify in classify:
value = map.get(resClassify)
if value:
map[resClassify] = value + 1
else:
map[resClassify] = 1
mostClassify = sorted(map.items(), key=lambda item: item[1])
return mostClassify[-1][0] """
对数据进行分类,并返回分类后的结果(如按照a特征分类后,分类后的结果数据集中就没有a特征值了) index:按照第几个特征开始分类,从0开始
value:按照该特征的什么值进行分类
data:待分类数据
"""
def categorizationOfData(index, value, data):
resData = []
# 循环每一个样本,如果第index个特征的值符合指定特征,就把该特征删除后保存
for man in data:
if man[index] == value:
tmpMan = man[:]
tmpMan.pop(index)
resData.append(tmpMan)
return resData """
D3算法构建决策树
步骤:
0、获取数据集
1、判断当前数据集是否需要继续分类,如不需要,则返回结果分类
2、找到最优特征
3、根据最优特征进行分类,并把最优特征删去
4、
"""
def createTree(data, labels):
classify = [man[-1] for man in data]
# 如果当前数据集数据都是同一分类结果则不用继续分类
if len(set(classify)) == 1:
return classify[0] # 如果数据集中的样本没有特征了,则返回数据集中出现最多的分类结果
if not labels:
return statisticsMostClassify(classify) # 原数据集香农熵
originalShannon = calcShannon(data)
# 熵差
diffShannon = 0
# 最优特征(index下标)
bestFeatureIndex = 0
# 按照最优特征分类后的结果{分类结果值:分类后的数据集}
bestClassifyData = {}
# 循环计算按照每一个特征分类后的结果,选择其中使得熵差值最大的特征作为最优特征
for i in range(len(labels)):
tmpClassifyData = {}
# 取出第i个特征的所有可能值
valueAll = [man[i] for man in data]
valueSetAll = set(valueAll) # 去重后的所有可能特征值
# 循环计算按各个可能值分类后的熵,然后求期望
classifyShannonMean = 0
for value in valueSetAll:
resData = categorizationOfData(i, value, data) # 按该特征值分类后结果
classifyShannon = calcShannon(resData) # 分类后的熵
classifyShannonMean += (valueAll.count(value) / len(valueAll)) * classifyShannon # 期望
tmpClassifyData.update({value: resData})
# 计算按照当前特征分类后的熵差
diff = originalShannon - classifyShannonMean
if diff >= diffShannon:
bestFeatureIndex = i
bestClassifyData = tmpClassifyData
diffShannon = diff
# 按结果分类,把labels中的最优特征删去,构建节点,并将各结果数据集递归
bestFeature = labels[bestFeatureIndex] # 获取最优特征的中文描述
tmpLabels = labels[:]
tmpLabels.pop(bestFeatureIndex)
node = {bestFeature: {}} # 当前节点
for key in bestClassifyData:
resClassify = createTree(bestClassifyData[key], tmpLabels)
node[bestFeature].update({key: resClassify})
return node # 使用样本测试样本构建决策树
tree = createTree(data, labels)
# 打印树
print(tree)
# 得到结果:{'是否戴眼镜': {'有眼镜': {'身材': {'胖': {'头发长短': {'长发': '男', '短发': '女'}}, '瘦': '女'}}, '没眼镜': '男'}}
(ps:不知不觉已经是第100篇随笔了,还是很有成就感的^_^)
D3算法编写决策树的更多相关文章
- SparkMLlib回归算法之决策树
SparkMLlib回归算法之决策树 (一),决策树概念 1,决策树算法(ID3,C4.5 ,CART)之间的比较: 1,ID3算法在选择根节点和各内部节点中的分支属性时,采用信息增益作为评价标准.信 ...
- (ZT)算法杂货铺——分类算法之决策树(Decision tree)
https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html 3.1.摘要 在前面两篇文章中,分别介绍和讨论了朴素贝叶斯分 ...
- SparkMLlib分类算法之决策树学习
SparkMLlib分类算法之决策树学习 (一) 决策树的基本概念 决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风 ...
- 机器学习中的算法(1)-决策树模型组合之随机森林与GBDT
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- paper 56 :机器学习中的算法:决策树模型组合之随机森林(Random Forest)
周五的组会如约而至,讨论了一个比较感兴趣的话题,就是使用SVM和随机森林来训练图像,这样的目的就是 在图像特征之间建立内在的联系,这个model的训练,着实需要好好的研究一下,下面是我们需要准备的入门 ...
- ID3算法(决策树)
一,预备知识: 信息量: 单个类别的信息熵: 条件信息量: 单个类别的条件熵: 信息增益: 信息熵: 条件熵:(表示分类的类,表示属性V的取值,m为属性V的取值个数,n为分类的个数) 二.算法流程: ...
- python数据分析算法(决策树2)CART算法
CART(Classification And Regression Tree),分类回归树,,决策树可以分为ID3算法,C4.5算法,和CART算法.ID3算法,C4.5算法可以生成二叉树或者多叉树 ...
- python 数据分析算法(决策树)
决策树基于时间的各个判断条件,由各个节点组成,类似一颗树从树的顶端,然后分支,再分支,每个节点由响的因素组成 决策树有两个阶段,构造和剪枝 构造: 构造的过程就是选择什么属性作为节点构造,通常有三种节 ...
- 机器学习(Machine Learning)算法总结-决策树
一.机器学习基本概念总结 分类(classification):目标标记为类别型的数据(离散型数据)回归(regression):目标标记为连续型数据 有监督学习(supervised learnin ...
随机推荐
- Http协议&Servlet
http协议 针对网络上的客户端 与 服务器端在执行http请求的时候,遵守的一种规范. 其实就是规定了客户端在访问服务器端的时候,要带上哪些东西, 服务器端返回数据的时候,也要带上什么东西. 版本 ...
- Android系统修改之Notification布局修改(一)
源码基于Android4.4 相关布局文件的位置: frameworks/base/core/res目录下: 1. notification_template_base.xml 2. notifica ...
- MySQL数据库的sql语句的导出与导入
1.MySQL数据库的导出 (1)选择对应的数据库 (2)点击右键选择Dump SQL File (3)会出现保存框,选择保存的位置,名称不建议重新起名 (4)点击保存出现 (5)点击Close就可以 ...
- BZOJ 4259 残缺的字符串
思路 同样是FFT进行字符串匹配 只不过两个都有通配符 匹配函数再乘一个\(A_i\)即可 代码 #include <cstdio> #include <algorithm> ...
- ssm框架中文请求乱码get
<bean id="utf8Charset" class="java.nio.charset.Charset" factory-method=" ...
- 使用win10的开始屏幕,在系统中设置简洁、快捷桌面
前几天入手了一个本本,由于之前电脑使用的柠檬桌面软件和现在本本的分辨率不适应,意外发现win10自带的开始屏幕整理桌面也是很有意思,再加上触摸板的手势,瞬间觉得整个电脑都清洁许多.废话少说,开始上料. ...
- R语言常用函数:交集intersect、并集union、找不同setdiff、判断相同setequal
在R语言进行数据分析时,经常需要找不同组间的相同和不同,那你应该掌握如下几个函数,让你事半功倍. 交集intersect两个向量的交集,集合可以是数字.字符串等 # 两个数值向量取交集intersec ...
- python实现将base64编码的图片下载到本地
# -*- coding:utf-8 -*- #!python3 import os import base64 sss ="""base64的编码"" ...
- .bat批处理启动redis
背景: 最近,公司的项目开发,需要用到Redis,然而每天都需要到d盘下面的去启动redis很烦, 我是我就想写一个.bat启动文件放在桌面上,这样每天只要在桌面上点以下redis的bat文件就可以启 ...
- 函数嵌套定义,闭包及闭包的应用场景,装饰器,global.nonlocal关键字
函数的嵌套定义 在一个函数的内部定义另一个函数 为什么要有函数的嵌套定义: 1)函数fn2想直接使用fn1函数的局部变量,可以将fn2直接定义到fn1的内部,这样fn2就可以直接访问fn1的变凉了 2 ...