java编译过程(字节码编译和即时编译)
简介:
编译包括两种情况:
1,源码编译成字节码
2,字节码编译成本地机器码(符合本地系统专属的指令)
解释执行也包括两种情况:
1,源码解释执行
2,字节码解释执行 解释和编译执行的区别是:是否产生中间本地机器码。
一,编译过程:
大部分的程序代码从开始编译到最终转化成物理机的目标代码或虚拟机能执行的指令集之前,都会按照如下图所示的各个步骤进行:
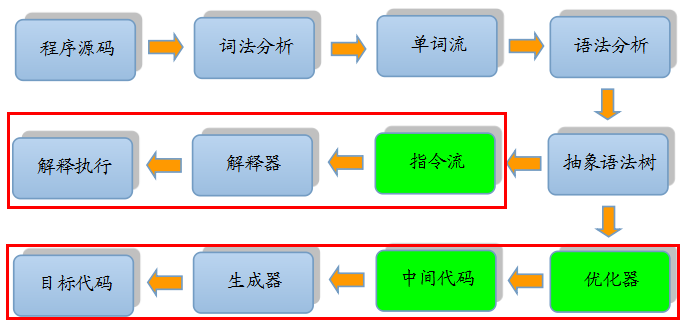
其中绿色的模块可以选择性实现。
- 上图中间的那条分支是解释执行的过程(即一条字节码一条字节码地解释执行,如JavaScript),
- 而下面的那条分支就是传统编译原理中从源代码到目标机器代码的生成过程。
二,现代经典编译原理的思路:
在执行前先对程序源码进行词法解析和语法解析处理,把源码转化为抽象语法树。
对于一门具体语言的实现来说:
- 词法和语法分析乃至后面的优化器和目标代码生成器都可以选择独立于执行引擎,形成一个完整意义的编译器去实现,这类代表是C/C++语言。
- 也可以把抽象语法树或指令流之前的步骤实现一个半独立的编译器,这类代表是Java语言。
- 又或者可以把这些步骤和执行引擎全部集中在一起实现,如大多数的JavaScript执行器。
三,Javac编译
在Java中提到“编译”,自然很容易想到Javac编译器将*.java文件编译成为*.class文件的过程,
1,这里的Javac编译器称为前端编译器,其他的前端编译器还有诸如Eclipse JDT中的增量式编译器ECJ等。
2,相对应的还有后端编译器,它在程序运行期间将字节码转变成机器码(现在的Java程序在运行时基本都是解释执行加编译执行),
如HotSpot虚拟机自带的JIT(Just In Time Compiler)编译器(分Client端和Server端)。
3,有时候还有静态提前编译器(AOT,Ahead Of Time Compiler)直接把*.java文件编译成本地机器代码,如GCJ、Excelsior JET等,这类编译器我们应该比较少遇到。
Javac编译(前端编译)的过程:
1,词法、语法分析
词法分析是将源代码的字符流转变为标记(Token)集合。
单个字符是程序编写过程中的的最小元素,而标记则是编译过程的最小元素,关键字、变量名、字面量、运算符等都可以成为标记,
比如整型标志int由三个字符构成,但是它只是一个标记,不可拆分。
语法分析是根据Token序列来构造抽象语法树的过程。
抽象语法树是一种用来描述程序代码语法结构的树形表示方式,语法树的每一个节点都代表着程序代码中的一个语法结构,如类型、修饰符、运算符等。
经过这个步骤后,编译器就基本不会再对源码文件进行操作了,后续的操作都建立在抽象语法树之上。
2,填充符号表
完成了语法分析和词法分析之后,下一步就是填充符号表的过程。
符号表是由一组符号地址和符号信息构成的表格。
符号表中所登记的信息在编译的不同阶段都要用到,在语义分析(后面的步骤)中,符号表所登记的内容将用于语义检查和产生中间代码,
在目标代码生成阶段,对符号名进行地址分配时,符号表是地址分配的依据。
比如:默认构造器的添加。
3,语义分析
语法树能表示一个结构正确的源程序的抽象,但无法保证源程序是符合逻辑的。
而语义分析的主要任务是:
对结构上正确的源程序进行上下文有关性的审查。
语义分析过程分为标注检查和数据及控制流分析两个步骤:
1,标注检查的内容包括诸如:变量使用前是否已被声明、变量和赋值之间的数据类型是否匹配等。
2,数据及控制流分析是对程序上下文逻辑更进一步的验证,
检查出诸如:程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了等问题。
4,字节码生成
字节码生成是Javac编译过程的最后一个阶段。
字节码生成阶段不仅仅是把前面各个步骤所生成的信息转化成字节码写到磁盘中,编译器还进行了少量的代码添加和转换工作。
- 实例构造器<init>()方法和类构造器<clinit>()方法就是在这个阶段添加到语法树之中的
- 这里的实例构造器并不是指默认的构造函数,而是指我们自己重载的构造函数,
如果用户代码中没有提供任何构造函数,那编译器会自动添加一个没有参数、访问权限与当前类一致的默认构造函数,这个工作在填充符号表阶段就已经完成了。
四,JIT编译
1,即时编译的产生:
Java程序最初是仅仅通过解释器解释执行的,即对字节码逐条解释执行,这种方式的执行速度相对会比较慢,
尤其当某个方法或代码块运行的特别频繁时,这种方式的执行效率就显得很低。
于是后来在虚拟机中引入了JIT编译器(即时编译器),
当虚拟机发现某个方法或代码块运行特别频繁时,就会把这些代码认定为“Hot Spot Code”(热点代码),
为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各层次的优化,完成这项任务的正是JIT编译器。
PS:区别是:即时编译生成机器相关的中间码,可重复执行缓存效率高。解释执行直接执行字节码,重复执行需要重复解释。
现在主流的商用虚拟机(如Sun HotSpot、IBM J9)中几乎都同时包含解释器和编译器
(三大商用虚拟机之一的JRockit是个例外,它内部没有解释器,因此会有启动相应时间长,但它主要是面向服务端的应用,这类应用一般不会重点关注启动时间)。
二者各有优势:
- 当程序需要迅速启动和执行时,解释器可以首先发挥作用,省去编译的时间,立即执行;
- 当程序运行后,随着时间的推移,编译器逐渐会失去作用,把越来越多的代码编译成本地代码后,可以获取更高的执行效率。
解释执行可以节约内存,而编译执行可以提升效率。
目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作。
2,运行过程中会被即时编译器编译的“热点代码”有两类:
被多次调用的方法。
被多次调用的循环体。
两种情况,编译器都是以整个方法作为编译对象,这种编译也是虚拟机中标准的编译方式。
一段代码或方法是不是热点代码,是不是需要触发即时编译,需要进行Hot Spot Detection(热点探测)。
3,目前主要的热点 判定方式有以下两种:
3,1,基于采样的热点探测:
虚拟机会周期性地检查各个线程的栈顶,如果发现某些方法经常出现在栈顶,那这段方法代码就是“热点代码”。
- 好处是:实现简单高效,还可以很容易地获取方法调用关系,
- 缺点是:很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的外界因素的影响而扰乱热点探测。
3,2,基于计数器的热点探测:
虚拟机会为每个方法,甚至是代码块建立计数器,统计方法的执行次数,
如果执行次数超过一定的阀值,就认为它是“热点方法”。
这种统计方法实现复杂一些,需要为每个方法建立并维护计数器,而且不能直接获取到方法的调用关系,但是它的统计结果相对更加精确严谨。
4,在HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法的两个计数器:
方法调用计数器和回边计数器。
4,1,方法调用计数器:
用来统计方法调用的次数,在默认设置下,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间内方法被调用的次数。
4,2,回边计数器:
用于统计一个方法中循环体代码执行的次数.
(准确地说,应该是回边的次数,因为并非所有的循环都是回边),
在字节码中遇到控制流向后跳转的指令就称为“回边”。
在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阀值,当计数器的值超过了阀值,就会触发JIT编译。
5,即时编译和解释执行的执行顺序:
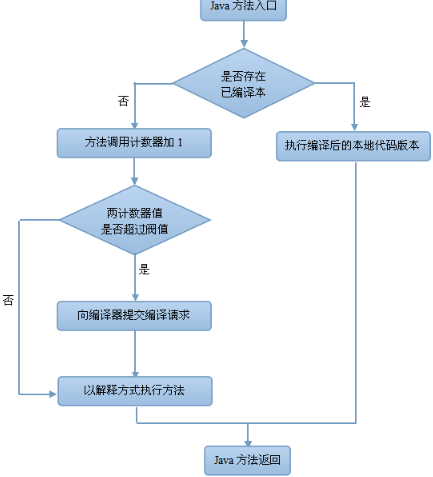
- 触发了JIT编译后,在默认设置下,执行引擎并不会同步等待编译请求完成,
- 而是继续进入解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成为止(编译工作在后台线程中进行)。
- 当编译工作完成后,下一次调用该方法或代码时,就会使用已编译的版本。
6,方法调用计数器触发即时编译的流程:
方法计数器触发即时编译的过程与回边计数器触发即时编译的过程类似
java编译过程(字节码编译和即时编译)的更多相关文章
- java编译后字节码解析
java编译后字节码解析 参考网摘: https://my.oschina.net/indestiny/blog/194260
- JVM总括三-字节码、字节码指令、JIT编译执行
JVM总括三-字节码.字节码指令.JIT编译执行 目录:JVM总括:目录 java文件编译后的class文件,java跨平台的中间层,JVM通过对字节码的解释执行(执行模式,还有JIT编译执行,下面讲 ...
- 鸿蒙内核源码分析(编译过程篇) | 简单案例窥视GCC编译全过程 | 百篇博客分析OpenHarmony源码| v57.01
百篇博客系列篇.本篇为: v57.xx 鸿蒙内核源码分析(编译过程篇) | 简单案例窥视编译全过程 | 51.c.h.o 编译构建相关篇为: v50.xx 鸿蒙内核源码分析(编译环境篇) | 编译鸿蒙 ...
- Python 文件编译为字节码的方法
一般情况下 python 不需要手动编译字节码.但是如果不想直接 release 源代码给其他人,将文件编译成字节码,可以实现一定程度的信息隐藏. 1) 使用模块 py_compile 编译一个单文件 ...
- 深入浅出Java探针技术1--基于java agent的字节码增强案例
Java agent又叫做Java 探针,本文将从以下四个问题出发来深入浅出了解下Java agent 一.什么是java agent? Java agent是在JDK1.5引入的,是一种可以动态修改 ...
- Java虚拟机--虚拟机字节码执行引擎
Java虚拟机--虚拟机字节码执行引擎 所有的Java虚拟机的执行引擎都是一致的:输入的是字节码文件,处理过程是字节码解析的等效过程,输出的是执行结果. 运行时栈帧结构 用于支持虚拟机进行方法调用和方 ...
- jbe 可以用来修改Java class的字节码,配合jd-gui 使用
jbe 可以用来修改Java class的字节码,配合jd-gui 使用
- 《深入理解java虚拟机》学习笔记之虚拟机即时编译详解
郑重声明:本片博客是学习<深入理解java虚拟机>一书所记录的笔记,内容基本为书中知识. Java程序最初是通过解释器(Interpreter)进行解释执行的,当虚拟机发现某个方法或代码块 ...
- 使用uncompyle2直接反编译python字节码文件pyo/pyc
update:在Mac OS X版的September 10, 2014版(5.0.9-1)中发现安装目录中的src.zip已更换位置至WingIDE.app/Contents/Resources/b ...
- python反编译之字节码
如果你曾经写过或者用过 Python,你可能已经习惯了看到 Python 源代码文件:它们的名称以.Py 结尾.你可能还见过另一种类型的文件是 .pyc 结尾的,它们就是 Python "字 ...
随机推荐
- Dynamics Customer Engagement V9版本配置面向Internet的部署时候下一步按钮不可点击的解决办法
微软动态CRM专家罗勇 ,回复299或者20190120可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me . Dynamics 3 ...
- android 开发之 ListView 与Adapter 应用实践
在开发android中,ListView 的应用显得非常频繁,只要需要显示列表展示的应用,可以说是必不可少,下面是记录开发中应用到ListView与Adapter 使用的实例: ListView 所在 ...
- git 的 origin 的含义
我们从progit 一书中可以看到: 远程仓库名字 “origin” 与分支名字 “master” 一样,在 Git 中并没有任何特别的含义一样. 同时“master”是当你运行git init时默认 ...
- 这么小的key-val数据库居然也支持事务——与短跑名将同名的数据库Bolt
传送门: 柏链项目学院 什么是Bolt? Bolt是一个纯净的基于go语言编写的key-val数据库,该项目受到LMDB项目的启发,目标是提供一个不需要完整服务器的简单.快速.可靠的数据库. ...
- python进阶之time模块详解
Time模块 Time模块包含的函数 Time模块包含了一下内置的函数,既有时间处理的,也有转换时间格式的: 序号 函数及描述 1 time.altzone 返回格林威治西部的夏令时地区的偏移秒数.如 ...
- 【Teradata SQL】FALLBACK表改为NO FALLBACK表
FALLBACK表在数据库中会留存双份数据,增加了数据可用性,但浪费了存储空间.变更表属性语句如下: alter table tab_fallback ,no fallback;
- vim之快速查找功能
vim有强大的字符串查找功能. 我们通常在vim下要查找字符串的时候, 都是输入 / 或者 ? 加 需要查找的字符串来进行搜索,比如想搜索 super 这个单词, 可以输入 /super 或者 ...
- 【题解】P1119 灾后重建
题目地址 理解Floyed的本质 Floyed的本质是动态规划. 在地K次循环中,Floyed算法枚举任意点对(X,Y),在这之前,K从未做过任何点对的中点.因此,可以利用K为中转的路径长度更新. 在 ...
- iis .apk .ipa下载设置
.apk .ipa无法下载 解决步骤:1).打开IIS服务管理器,找到服务器,右键-属性,打开IIS服务属性:2.单击MIME类型下的“MIME类型”按钮,打开MIME类型设置窗口:3).单击“新建” ...
- Mac下MySql初始密码设置及mysql数据库操作
1. 首先 点击系统偏好设置 -> 点击MySQL, 在弹出的页面中,关闭服务.2. 进入终端命令输出: cd /usr/local/mysql/bin/ 命令,回车.3. 回车后,输入命令:s ...