knn算法详解
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。判断邻居就是用向量距离大小来刻画。
 一张必不可少的图
一张必不可少的图算法流程
缺点
import numpy as np
import matplotlib.pyplot as plt #绘图
import pandas as pd
再导入数据集
以excel格式为例,我的iris目标文件存储在
"D://test_knn"中
url = "D://test_knn./iris.csv" #url path # Assign column names to the dataset
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class'] # Read dataset to pandas dataframe
dataset = pd.read_csv(url, names=names)
可以用下面函数检验导入是否成功
dataset.head() #默认读取前五行
输出结果如下:
sepal-length sepal-width petal-length petal-width Class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
2.Preprocessing the dataset 数据预处理
x= dataset.iloc[:, :-1].values #x 属性
#第一个冒号是所有列,第二个是所有行,除了最后一个(Purchased) y = dataset.iloc[:, 4].values #y 标签
# 只取最后一个作为依赖变量。
3.Train Test Split
把数据划分成训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
80%的数据划分到训练集,20%的数据划分到测试集
4.Feature scaling
from sklearn.preprocessing import StandardScaler #导入库 这个不知道可以去查查用法
scaler = StandardScaler()
scaler.fit(X_train) X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
5.Training and Predictions 训练预测
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5) # k=5
classifier.fit(X_train, y_train)
y_pred=classifier.predict(X_test)
6.Evaluating the algorithm
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
预期输出结果如下:
The output of the above script looks like this:
[[11 0 0]
0 13 0]
0 1 6]]
precision recall f1-score support Iris-setosa 1.00 1.00 1.00 11
Iris-versicolor 1.00 1.00 1.00 13
Iris-virginica 1.00 1.00 1.00 6
avg/total 1.00 1.00 1.00 30
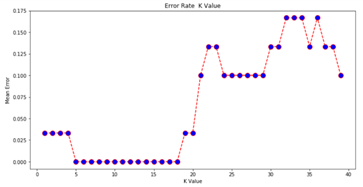
7.Comparing Error Rate with the K Value
把各种可能的k的取值,及其对应的分类误差率(error rate)绘制在一张图上。
error = [] # Calculating error for K values between 1 and 40
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(np.mean(pred_i != y_test))
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
输出结果预期如下:
至此, 这套knn算法就实现了,现在体会到python工具包的强大了,好多底层的算法都不需要自己写函数实现。
搜了一下用C实现knn,代码很繁琐,但是很直观,每一步干什么很清楚。python写的话呢,如果对这些库不熟悉,那就很头秃了,需要一个一个函数查它的用法,不过,如果真的掌握了可以更快更轻松地实现。就是这样子了!
刚开始做的时候看到一堆代码,一脸懵逼,感觉在看文言文一样。其实只要耐心看,真的只是了解一点库函数用法,算法本身思想很简单!
第一个机器学习算法笔记,开心!
knn算法详解的更多相关文章
- 算法代码[置顶] 机器学习实战之KNN算法详解
改章节笔者在深圳喝咖啡的时候突然想到的...之前就有想写几篇关于算法代码的文章,所以回家到以后就奋笔疾书的写出来发表了 前一段时间介绍了Kmeans聚类,而KNN这个算法刚好是聚类以后经常使用的匹配技 ...
- 机器学习-KNN算法详解与实战
最邻近规则分类(K-Nearest Neighbor)KNN算法 1.综述 1.1 Cover和Hart在1968年提出了最初的邻近算法 1.2 分类(classification)算法 1.3 输入 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
随机推荐
- JDK源码分析(9) LinkedHashMap
概述 LinkedHashMap是一个关联数组.哈希表,它是线程不安全的,允许key为null,value为null.他继承自HashMap,实现了Map<K,V>接口.其内部还维护了一个 ...
- Django学习目录
Django学习目录 Django框架简介 Django基础 >>点我 ORM介绍 Django中ORM介绍 >>点我 ORM表操作 Django中ORM表相关操作 >& ...
- jQuery 为动态添加的元素绑定事件
在使用jquery的方式为元素绑定事件时,我经常使用bind或者click,但这只能为页面已经加载好的元素绑定事件.像需要用ajax的方式请求远程数据来动态添加页面元素时,显然以上几种绑定事件的方式是 ...
- 第七周博客作业<西北师范大学|李晓婷>
1.助教博客链接:https://home.cnblogs.com/u/lxt-/ 2.本周应批作业0,实批作业0. 3.本周小结:本周我们助教开始准备团队项目题目,下周三之前将会进行作业提交.
- dpdk之路-环境部署
dpdk实验环境部署 1.实验环境说明 vmware workstatioin 12 centos 7.5.1804 dpdk-stable-18.11.1 2.实验步骤 (1)虚拟机安装 http: ...
- 1. Ansible 简介
目录 1. Ansible 是什么? 2. Ansible 特性 3. 控制主机需求 4. 被管理节点需求 1. Ansible 是什么? Ansible 是一个配置管理系统(configuratio ...
- [转载]Yacc 与 Lex 快速入门
https://www.ibm.com/developerworks/cn/linux/sdk/lex/index.html
- SQL判断语句
,,decode(tts.execute_state,,'false','true')) from twf_tech_schedule tts sql判断语句
- tomcat配置及环境搭建
步骤一 下载tomcat 下载tomcat并安装,登陆tomcat官网,http://tomcat.apache.org/,Windows系统建议选择Windows Service Installer ...
- move_base Warning: Invalid argument "/map" passed to canTransform argument target_frame的解决方法
把global_costmap_params.yaml和local_costmap_params.yaml文件里的头几行去掉“/”,然后重新编译就可以了. 效果如下: